 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-tuned Wav2vec 2.0/HuBERT Benchmark For Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding
Paper and Code
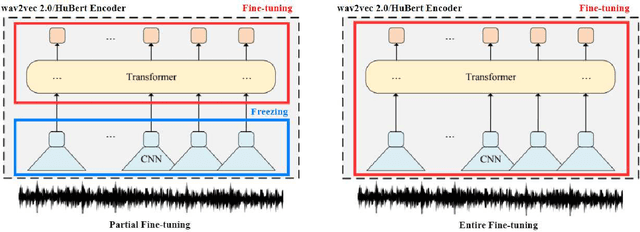
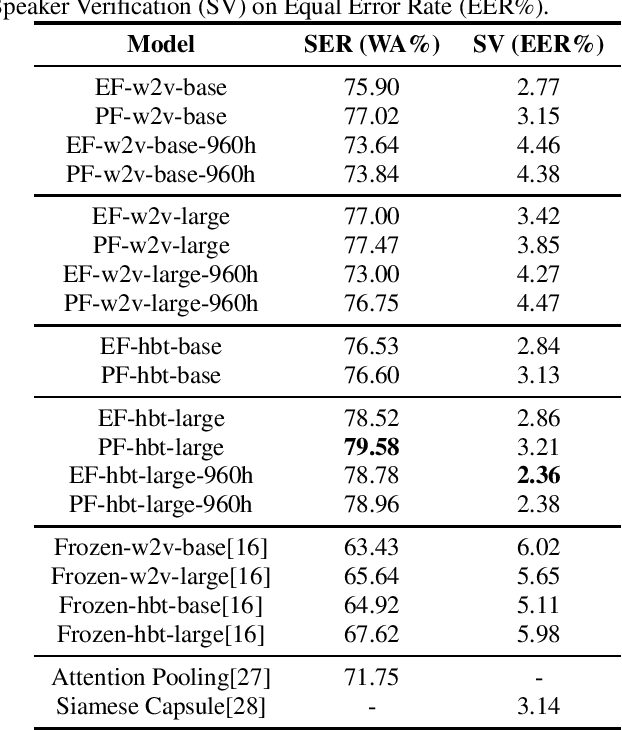
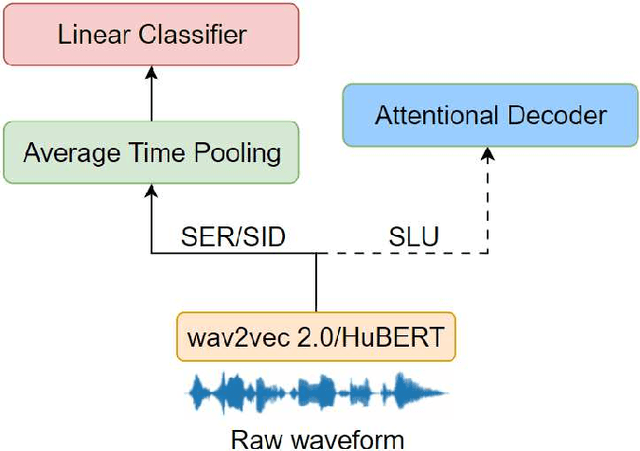
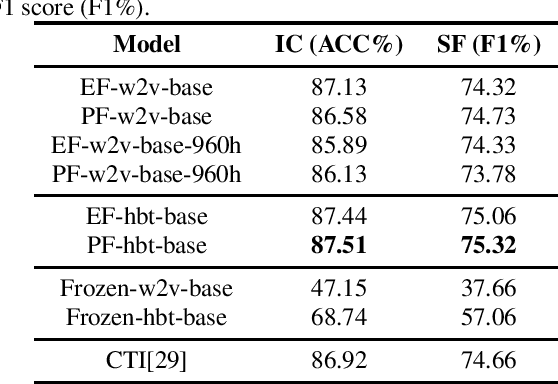
Self-supervised speech representations such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, self-supervised models have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. We also compare pre-trained models with/without ASR fine-tuning. With simple down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 87.51% accuracy for Intent Classification and 75.32% F1 for Slot Filling on SLURP, thus setting a new state-of-the-art for these three benchmarks, proving that fine-tuned wav2vec 2.0 and HuBERT models can better learn prosodic, voice-print and semantic representations.