 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-Inspired Self-Supervised Learning for Wrist-worn IMU Signals
Mar 11, 2026Wearable accelerometers have enabled large-scale health and wellness monitoring, yet learning robust human-activity representations has been constrained by the scarcity of labeled data. While self-supervised learning offers a potential remedy, existing approaches treat sensor streams as unstructured time series, overlooking the underlying biological structure of human movement, a factor we argue is critical for effective Human Activity Recognition (HAR). We introduce a novel tokenization strategy grounded in the submovement theory of motor control, which posits that continuous wrist motion is composed of superposed elementary basis functions called submovements. We define our token as the movement segment, a unit of motion composed of a finite sequence of submovements that is readily extractable from wrist accelerometer signals. By treating these segments as tokens, we pretrain a Transformer encoder via masked movement-segment reconstruction to model the temporal dependencies of movement segments, shifting the learning focus beyond local waveform morphology. Pretrained on the NHANES corpus (approximately 28k hours; approximately 11k participants; approximately 10M windows), our representations outperform strong wearable SSL baselines across six subject-disjoint HAR benchmarks. Furthermore, they demonstrate stronger data efficiency in data-scarce settings. Code and pretrained weights will be made publicly available.
Transfer Learning for Keypoint Detection in Low-Resolution Thermal TUG Test Images
Jan 30, 2025This study presents a novel approach to human keypoint detection in low-resolution thermal images using transfer learning techniques. We introduce the first application of the Timed Up and Go (TUG) test in thermal image computer vision, establishing a new paradigm for mobility assessment. Our method leverages a MobileNetV3-Small encoder and a ViTPose decoder, trained using a composite loss function that balances latent representation alignment and heatmap accuracy. The model was evaluated using the Object Keypoint Similarity (OKS) metric from the COCO Keypoint Detection Challenge. The proposed model achieves better performance with AP, AP50, and AP75 scores of 0.861, 0.942, and 0.887 respectively, outperforming traditional supervised learning approaches like Mask R-CNN and ViTPose-Base. Moreover, our model demonstrates superior computational efficiency in terms of parameter count and FLOPS. This research lays a solid foundation for future clinical applications of thermal imaging in mobility assessment and rehabilitation monitoring.
MSECG: Incorporating Mamba for Robust and Efficient ECG Super-Resolution
Dec 06, 2024Electrocardiogram (ECG) signals play a crucial role in diagnosing cardiovascular diseases. To reduce power consumption in wearable or portable devices used for long-term ECG monitoring, super-resolution (SR) techniques have been developed, enabling these devices to collect and transmit signals at a lower sampling rate. In this study, we propose MSECG, a compact neural network model designed for ECG SR. MSECG combines the strength of the recurrent Mamba model with convolutional layers to capture both local and global dependencies in ECG waveforms, allowing for the effective reconstruction of high-resolution signals. We also assess the model's performance in real-world noisy conditions by utilizing ECG data from the PTB-XL database and noise data from the MIT-BIH Noise Stress Test Database. Experimental results show that MSECG outperforms two contemporary ECG SR models under both clean and noisy conditions while using fewer parameters, offering a more powerful and robust solution for long-term ECG monitoring applications.
TrustEMG-Net: Using Representation-Masking Transformer with U-Net for Surface Electromyography Enhancement
Oct 04, 2024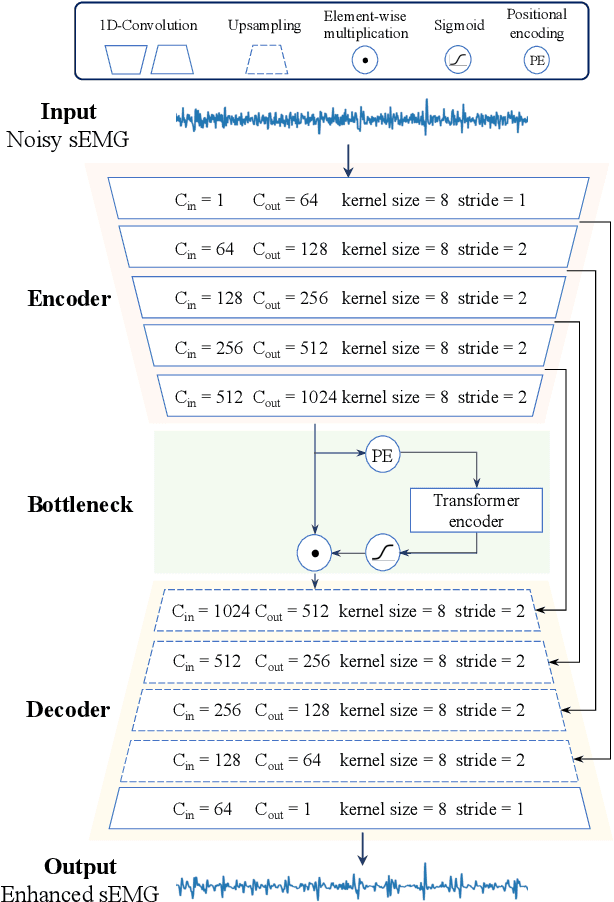
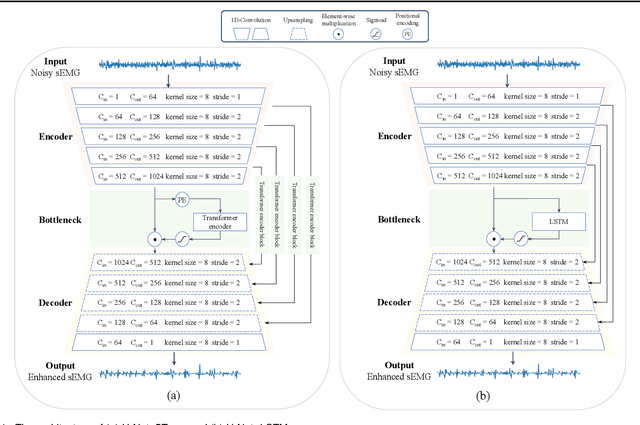
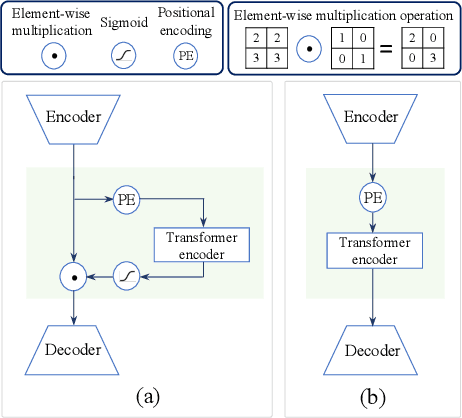
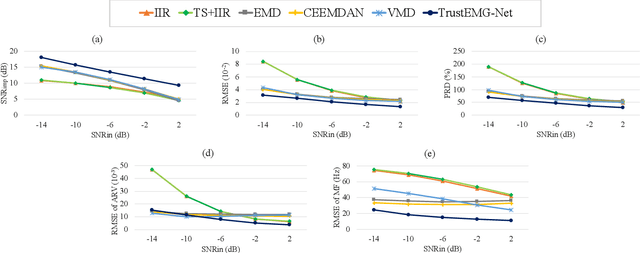
Surface electromyography (sEMG) is a widely employed bio-signal that captures human muscle activity via electrodes placed on the skin. Several studies have proposed methods to remove sEMG contaminants, as non-invasive measurements render sEMG susceptible to various contaminants. However, these approaches often rely on heuristic-based optimization and are sensitive to the contaminant type. A more potent, robust, and generalized sEMG denoising approach should be developed for various healthcare and human-computer interaction applications. This paper proposes a novel neural network (NN)-based sEMG denoising method called TrustEMG-Net. It leverages the potent nonlinear mapping capability and data-driven nature of NNs. TrustEMG-Net adopts a denoising autoencoder structure by combining U-Net with a Transformer encoder using a representation-masking approach. The proposed approach is evaluated using the Ninapro sEMG database with five common contamination types and signal-to-noise ratio (SNR) conditions. Compared with existing sEMG denoising methods, TrustEMG-Net achieves exceptional performance across the five evaluation metrics, exhibiting a minimum improvement of 20%. Its superiority is consistent under various conditions, including SNRs ranging from -14 to 2 dB and five contaminant types. An ablation study further proves that the design of TrustEMG-Net contributes to its optimality, providing high-quality sEMG and serving as an effective, robust, and generalized denoising solution for sEMG applications.
MECG-E: Mamba-based ECG Enhancer for Baseline Wander Removal
Sep 27, 2024Electrocardiogram (ECG) is an important non-invasive method for diagnosing cardiovascular disease. However, ECG signals are susceptible to noise contamination, such as electrical interference or signal wandering, which reduces diagnostic accuracy. Various ECG denoising methods have been proposed, but most existing methods yield suboptimal performance under very noisy conditions or require several steps during inference, leading to latency during online processing. In this paper, we propose a novel ECG denoising model, namely Mamba-based ECG Enhancer (MECG-E), which leverages the Mamba architecture known for its fast inference and outstanding nonlinear mapping capabilities. Experimental results indicate that MECG-E surpasses several well-known existing models across multiple metrics under different noise conditions. Additionally, MECG-E requires less inference time than state-of-the-art diffusion-based ECG denoisers, demonstrating the model's functionality and efficiency.
Abnormal Respiratory Sound Identification Using Audio-Spectrogram Vision Transformer
May 14, 2024
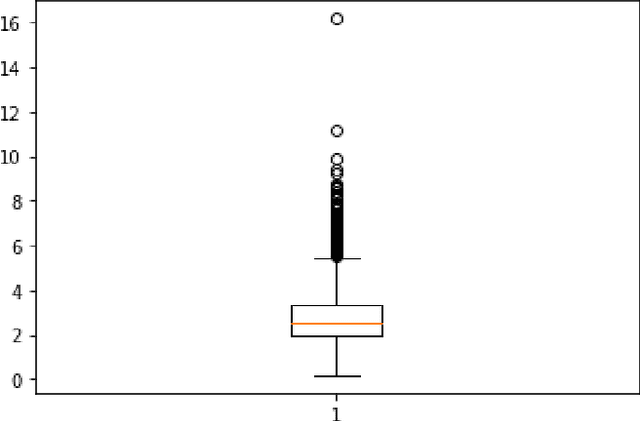

Respiratory disease, the third leading cause of deaths globally, is considered a high-priority ailment requiring significant research on identification and treatment. Stethoscope-recorded lung sounds and artificial intelligence-powered devices have been used to identify lung disorders and aid specialists in making accurate diagnoses. In this study, audio-spectrogram vision transformer (AS-ViT), a new approach for identifying abnormal respiration sounds, was developed. The sounds of the lungs are converted into visual representations called spectrograms using a technique called short-time Fourier transform (STFT). These images are then analyzed using a model called vision transformer to identify different types of respiratory sounds. The classification was carried out using the ICBHI 2017 database, which includes various types of lung sounds with different frequencies, noise levels, and backgrounds. The proposed AS-ViT method was evaluated using three metrics and achieved 79.1% and 59.8% for 60:40 split ratio and 86.4% and 69.3% for 80:20 split ratio in terms of unweighted average recall and overall scores respectively for respiratory sound detection, surpassing previous state-of-the-art results.
* Published in 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC)
A Non-Intrusive Neural Quality Assessment Model for Surface Electromyography Signals
Feb 08, 2024In practical scenarios involving the measurement of surface electromyography (sEMG) in muscles, particularly those areas near the heart, one of the primary sources of contamination is the presence of electrocardiogram (ECG) signals. To assess the quality of real-world sEMG data more effectively, this study proposes QASE-net, a new non-intrusive model that predicts the SNR of sEMG signals. QASE-net combines CNN-BLSTM with attention mechanisms and follows an end-to-end training strategy. Our experimental framework utilizes real-world sEMG and ECG data from two open-access databases, the Non-Invasive Adaptive Prosthetics Database and the MIT-BIH Normal Sinus Rhythm Database, respectively. The experimental results demonstrate the superiority of QASE-net over the previous assessment model, exhibiting significantly reduced prediction errors and notably higher linear correlations with the ground truth. These findings show the potential of QASE-net to substantially enhance the reliability and precision of sEMG quality assessment in practical applications.
SDEMG: Score-based Diffusion Model for Surface Electromyographic Signal Denoising
Feb 06, 2024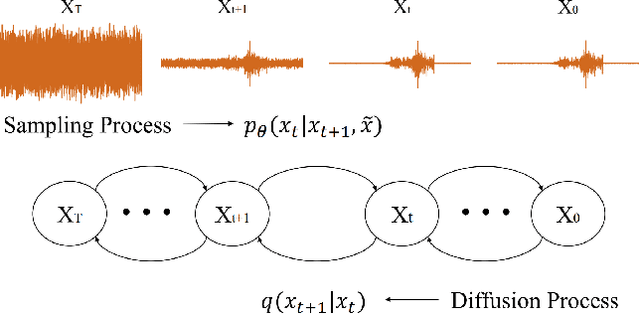
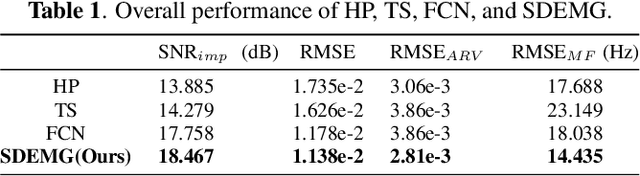
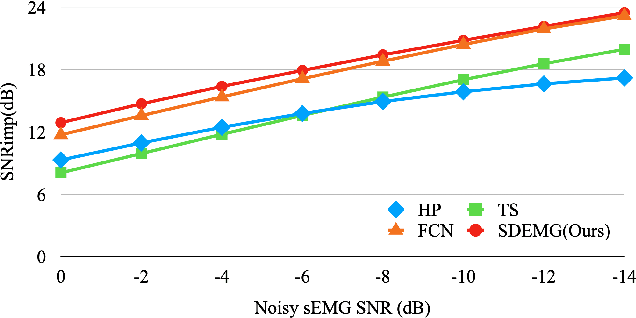
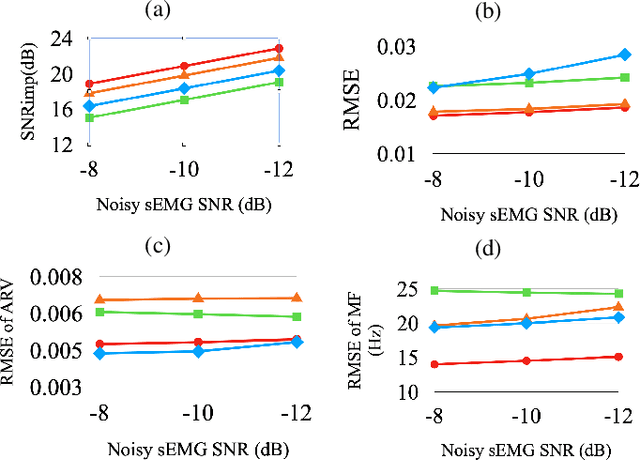
Surface electromyography (sEMG) recordings can be influenced by electrocardiogram (ECG) signals when the muscle being monitored is close to the heart. Several existing methods use signal-processing-based approaches, such as high-pass filter and template subtraction, while some derive mapping functions to restore clean sEMG signals from noisy sEMG (sEMG with ECG interference). Recently, the score-based diffusion model, a renowned generative model, has been introduced to generate high-quality and accurate samples with noisy input data. In this study, we proposed a novel approach, termed SDEMG, as a score-based diffusion model for sEMG signal denoising. To evaluate the proposed SDEMG approach, we conduct experiments to reduce noise in sEMG signals, employing data from an openly accessible source, the Non-Invasive Adaptive Prosthetics database, along with ECG signals from the MIT-BIH Normal Sinus Rhythm Database. The experiment result indicates that SDEMG outperformed comparative methods and produced high-quality sEMG samples. The source code of SDEMG the framework is available at: https://github.com/tonyliu0910/SDEMG
Deep Learning-based Fall Detection Algorithm Using Ensemble Model of Coarse-fine CNN and GRU Networks
Apr 13, 2023


Falls are the public health issue for the elderly all over the world since the fall-induced injuries are associated with a large amount of healthcare cost. Falls can cause serious injuries, even leading to death if the elderly suffers a "long-lie". Hence, a reliable fall detection (FD) system is required to provide an emergency alarm for first aid. Due to the advances in wearable device technology and artificial intelligence, some fall detection systems have been developed using machine learning and deep learning methods to analyze the signal collected from accelerometer and gyroscopes. In order to achieve better fall detection performance, an ensemble model that combines a coarse-fine convolutional neural network and gated recurrent unit is proposed in this study. The parallel structure design used in this model restores the different grains of spatial characteristics and capture temporal dependencies for feature representation. This study applies the FallAllD public dataset to validate the reliability of the proposed model, which achieves a recall, precision, and F-score of 92.54%, 96.13%, and 94.26%, respectively. The results demonstrate the reliability of the proposed ensemble model in discriminating falls from daily living activities and its superior performance compared to the state-of-the-art convolutional neural network long short-term memory (CNN-LSTM) for FD.
PreFallKD: Pre-Impact Fall Detection via CNN-ViT Knowledge Distillation
Mar 13, 2023

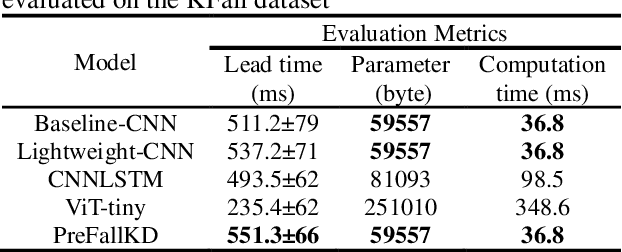
Fall accidents are critical issues in an aging and aged society. Recently, many researchers developed pre-impact fall detection systems using deep learning to support wearable-based fall protection systems for preventing severe injuries. However, most works only employed simple neural network models instead of complex models considering the usability in resource-constrained mobile devices and strict latency requirements. In this work, we propose a novel pre-impact fall detection via CNN-ViT knowledge distillation, namely PreFallKD, to strike a balance between detection performance and computational complexity. The proposed PreFallKD transfers the detection knowledge from the pre-trained teacher model (vision transformer) to the student model (lightweight convolutional neural networks). Additionally, we apply data augmentation techniques to tackle issues of data imbalance. We conduct the experiment on the KFall public dataset and compare PreFallKD with other state-of-the-art models. The experiment results show that PreFallKD could boost the student model during the testing phase and achieves reliable F1-score (92.66%) and lead time (551.3 ms).