 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBloodroot: When Watermarking Turns Poisonous For Stealthy Backdoor
Oct 09, 2025Backdoor data poisoning is a crucial technique for ownership protection and defending against malicious attacks. Embedding hidden triggers in training data can manipulate model outputs, enabling provenance verification, and deterring unauthorized use. However, current audio backdoor methods are suboptimal, as poisoned audio often exhibits degraded perceptual quality, which is noticeable to human listeners. This work explores the intrinsic stealthiness and effectiveness of audio watermarking in achieving successful poisoning. We propose a novel Watermark-as-Trigger concept, integrated into the Bloodroot backdoor framework via adversarial LoRA fine-tuning, which enhances perceptual quality while achieving a much higher trigger success rate and clean-sample accuracy. Experiments on speech recognition (SR) and speaker identification (SID) datasets show that watermark-based poisoning remains effective under acoustic filtering and model pruning. The proposed Bloodroot backdoor framework not only secures data-to-model ownership, but also well reveals the risk of adversarial misuse.
Guitar Tone Morphing by Diffusion-based Model
Oct 09, 2025In Music Information Retrieval (MIR), modeling and transforming the tone of musical instruments, particularly electric guitars, has gained increasing attention due to the richness of the instrument tone and the flexibility of expression. Tone morphing enables smooth transitions between different guitar sounds, giving musicians greater freedom to explore new textures and personalize their performances. This study explores learning-based approaches for guitar tone morphing, beginning with LoRA fine-tuning to improve the model performance on limited data. Moreover, we introduce a simpler method, named spherical interpolation using Music2Latent. It yields significantly better results than the more complex fine-tuning approach. Experiments show that the proposed architecture generates smoother and more natural tone transitions, making it a practical and efficient tool for music production and real-time audio effects.
* 5 pages
Do You Hear What I Mean? Quantifying the Instruction-Perception Gap in Instruction-Guided Expressive Text-To-Speech Systems
Sep 18, 2025Instruction-guided text-to-speech (ITTS) enables users to control speech generation through natural language prompts, offering a more intuitive interface than traditional TTS. However, the alignment between user style instructions and listener perception remains largely unexplored. This work first presents a perceptual analysis of ITTS controllability across two expressive dimensions (adverbs of degree and graded emotion intensity) and collects human ratings on speaker age and word-level emphasis attributes. To comprehensively reveal the instruction-perception gap, we provide a data collection with large-scale human evaluations, named Expressive VOice Control (E-VOC) corpus. Furthermore, we reveal that (1) gpt-4o-mini-tts is the most reliable ITTS model with great alignment between instruction and generated utterances across acoustic dimensions. (2) The 5 analyzed ITTS systems tend to generate Adult voices even when the instructions ask to use child or Elderly voices. (3) Fine-grained control remains a major challenge, indicating that most ITTS systems have substantial room for improvement in interpreting slightly different attribute instructions.
Towards Robust Assessment of Pathological Voices via Combined Low-Level Descriptors and Foundation Model Representations
May 30, 2025



Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders by providing standardized evaluations of vocal function. Traditionally, expert raters use standard scales such as the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) and Grade, Roughness, Breathiness, Asthenia, and Strain (GRBAS). However, these metrics are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes Voice Quality Assessment Network (VOQANet), a deep learning-based framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To enhance robustness and interpretability, we also introduce VOQANet+, which integrates low-level speech descriptors such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior studies focused only on vowel-based phonation (PVQD-A subset) of the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) to improve generalizability. Results show that sentence-based input outperforms vowel-based input, especially at the patient level, underscoring the value of longer utterances for capturing perceptual voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error (RMSE) and Pearson correlation coefficient (PCC) across CAPE-V and GRBAS dimensions, with VOQANet+ achieving even better performance. Additional experiments under noisy conditions show that VOQANet+ maintains high prediction accuracy and robustness, supporting its potential for real-world and telehealth deployment.
Towards Robust Automated Perceptual Voice Quality Assessment with Speech Foundation Models
May 28, 2025Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders. Traditionally, expert raters use scales such as the CAPE-V and GRBAS. However, these are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes VOQANet, a deep learning framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To improve robustness and interpretability, we introduce VOQANet+, which integrates handcrafted acoustic features such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior work focusing only on vowel-based phonation (PVQD-A subset) from the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) for better generalizability. Results show that sentence-based input outperforms vowel-based input, particularly at the patient level, highlighting the benefit of longer utterances for capturing voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error and Pearson correlation across CAPE-V and GRBAS dimensions, with VOQANet+ achieving further improvements. Additional tests under noisy conditions show that VOQANet+ maintains high prediction accuracy, supporting its use in real-world and telehealth settings. These findings demonstrate the value of combining SFM embeddings with domain-informed acoustic features for interpretable and robust voice quality assessment.
Creativity in LLM-based Multi-Agent Systems: A Survey
May 27, 2025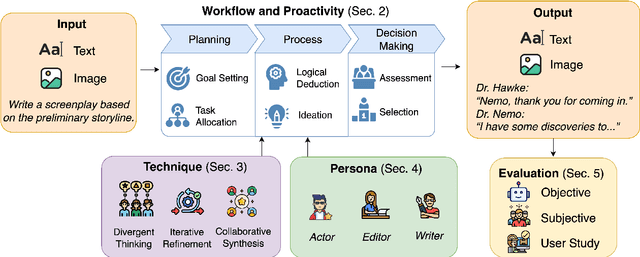



Large language model (LLM)-driven multi-agent systems (MAS) are transforming how humans and AIs collaboratively generate ideas and artifacts. While existing surveys provide comprehensive overviews of MAS infrastructures, they largely overlook the dimension of \emph{creativity}, including how novel outputs are generated and evaluated, how creativity informs agent personas, and how creative workflows are coordinated. This is the first survey dedicated to creativity in MAS. We focus on text and image generation tasks, and present: (1) a taxonomy of agent proactivity and persona design; (2) an overview of generation techniques, including divergent exploration, iterative refinement, and collaborative synthesis, as well as relevant datasets and evaluation metrics; and (3) a discussion of key challenges, such as inconsistent evaluation standards, insufficient bias mitigation, coordination conflicts, and the lack of unified benchmarks. This survey offers a structured framework and roadmap for advancing the development, evaluation, and standardization of creative MAS.
SeamlessEdit: Background Noise Aware Zero-Shot Speech Editing with in-Context Enhancement
May 20, 2025With the fast development of zero-shot text-to-speech technologies, it is possible to generate high-quality speech signals that are indistinguishable from the real ones. Speech editing, including speech insertion and replacement, appeals to researchers due to its potential applications. However, existing studies only considered clean speech scenarios. In real-world applications, the existence of environmental noise could significantly degrade the quality of the generation. In this study, we propose a noise-resilient speech editing framework, SeamlessEdit, for noisy speech editing. SeamlessEdit adopts a frequency-band-aware noise suppression module and an in-content refinement strategy. It can well address the scenario where the frequency bands of voice and background noise are not separated. The proposed SeamlessEdit framework outperforms state-of-the-art approaches in multiple quantitative and qualitative evaluations.
DOFEN: Deep Oblivious Forest ENsemble
Dec 24, 2024



Deep Neural Networks (DNNs) have revolutionized artificial intelligence, achieving impressive results on diverse data types, including images, videos, and texts. However, DNNs still lag behind Gradient Boosting Decision Trees (GBDT) on tabular data, a format extensively utilized across various domains. In this paper, we propose DOFEN, short for \textbf{D}eep \textbf{O}blivious \textbf{F}orest \textbf{EN}semble, a novel DNN architecture inspired by oblivious decision trees. DOFEN constructs relaxed oblivious decision trees (rODTs) by randomly combining conditions for each column and further enhances performance with a two-level rODT forest ensembling process. By employing this approach, DOFEN achieves state-of-the-art results among DNNs and further narrows the gap between DNNs and tree-based models on the well-recognized benchmark: Tabular Benchmark \citep{grinsztajn2022tree}, which includes 73 total datasets spanning a wide array of domains. The code of DOFEN is available at: \url{https://github.com/Sinopac-Digital-Technology-Division/DOFEN}.
An Attention-based Framework with Multistation Information for Earthquake Early Warnings
Dec 24, 2024Earthquake early warning systems play crucial roles in reducing the risk of seismic disasters. Previously, the dominant modeling system was the single-station models. Such models digest signal data received at a given station and predict earth-quake parameters, such as the p-phase arrival time, intensity, and magnitude at that location. Various methods have demonstrated adequate performance. However, most of these methods present the challenges of the difficulty of speeding up the alarm time, providing early warning for distant areas, and considering global information to enhance performance. Recently, deep learning has significantly impacted many fields, including seismology. Thus, this paper proposes a deep learning-based framework, called SENSE, for the intensity prediction task of earthquake early warning systems. To explicitly consider global information from a regional or national perspective, the input to SENSE comprises statistics from a set of stations in a given region or country. The SENSE model is designed to learn the relationships among the set of input stations and the locality-specific characteristics of each station. Thus, SENSE is not only expected to provide more reliable forecasts by considering multistation data but also has the ability to provide early warnings to distant areas that have not yet received signals. This study conducted extensive experiments on datasets from Taiwan and Japan. The results revealed that SENSE can deliver competitive or even better performances compared with other state-of-the-art methods.
Abnormal Respiratory Sound Identification Using Audio-Spectrogram Vision Transformer
May 14, 2024

Respiratory disease, the third leading cause of deaths globally, is considered a high-priority ailment requiring significant research on identification and treatment. Stethoscope-recorded lung sounds and artificial intelligence-powered devices have been used to identify lung disorders and aid specialists in making accurate diagnoses. In this study, audio-spectrogram vision transformer (AS-ViT), a new approach for identifying abnormal respiration sounds, was developed. The sounds of the lungs are converted into visual representations called spectrograms using a technique called short-time Fourier transform (STFT). These images are then analyzed using a model called vision transformer to identify different types of respiratory sounds. The classification was carried out using the ICBHI 2017 database, which includes various types of lung sounds with different frequencies, noise levels, and backgrounds. The proposed AS-ViT method was evaluated using three metrics and achieved 79.1% and 59.8% for 60:40 split ratio and 86.4% and 69.3% for 80:20 split ratio in terms of unweighted average recall and overall scores respectively for respiratory sound detection, surpassing previous state-of-the-art results.
* Published in 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC)