 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement-assisted Stargan Voice Conversion in Noisy Environments
Paper and Code
Oct 19, 2021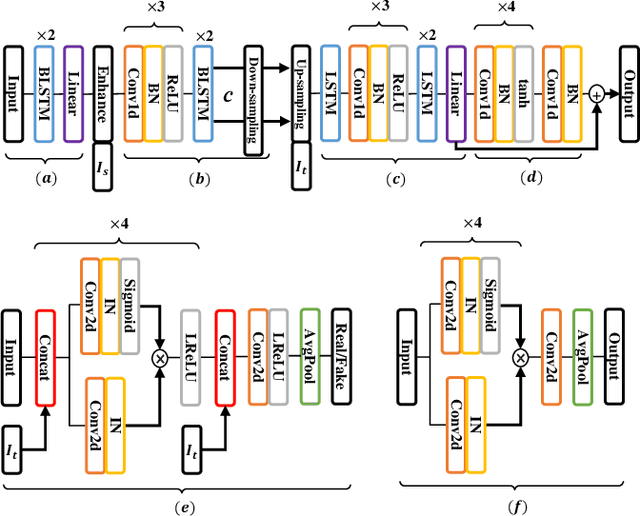

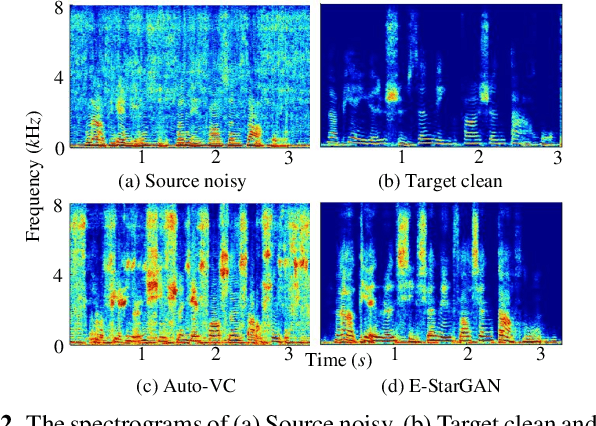
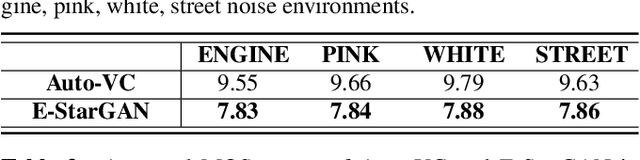
Numerous voice conversion (VC) techniques have been proposed for the conversion of voices among different speakers. Although the decent quality of converted speech can be observed when VC is applied in a clean environment, the quality will drop sharply when the system is running under noisy conditions. In order to address this issue, we propose a novel enhancement-based StarGAN (E-StarGAN) VC system, which leverages a speech enhancement (SE) technique for signal pre-processing. SE systems are generally used to reduce noise components in noisy speech and to generate enhanced speech for downstream application tasks. Therefore, we investigated the effectiveness of E-StarGAN, which combines VC and SE, and demonstrated the robustness of the proposed approach in various noisy environments. The results of VC experiments conducted on a Mandarin dataset show that when combined with SE, the proposed E-StarGAN VC model is robust to unseen noises. In addition, the subjective listening test results show that the proposed E-StarGAN model can improve the sound quality of speech signals converted from noise-corrupted source utterances.