 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVSNet+: Enhancing Speaker Voice Similarity Assessment Models with Representations from Speech Foundation Models
Jun 12, 2024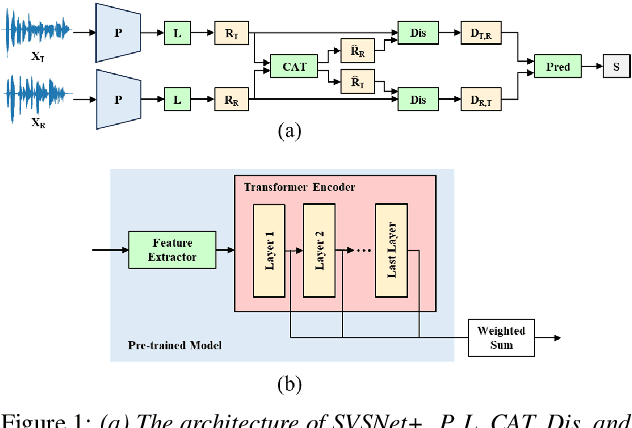



Representations from pre-trained speech foundation models (SFMs) have shown impressive performance in many downstream tasks. However, the potential benefits of incorporating pre-trained SFM representations into speaker voice similarity assessment have not been thoroughly investigated. In this paper, we propose SVSNet+, a model that integrates pre-trained SFM representations to improve performance in assessing speaker voice similarity. Experimental results on the Voice Conversion Challenge 2018 and 2020 datasets show that SVSNet+ incorporating WavLM representations shows significant improvements compared to baseline models. In addition, while fine-tuning WavLM with a small dataset of the downstream task does not improve performance, using the same dataset to learn a weighted-sum representation of WavLM can substantially improve performance. Furthermore, when WavLM is replaced by other SFMs, SVSNet+ still outperforms the baseline models and exhibits strong generalization ability.
Audio-Visual Mandarin Electrolaryngeal Speech Voice Conversion
Jun 11, 2023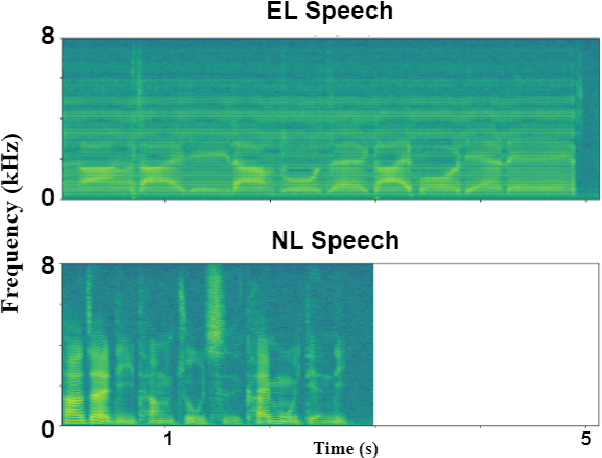

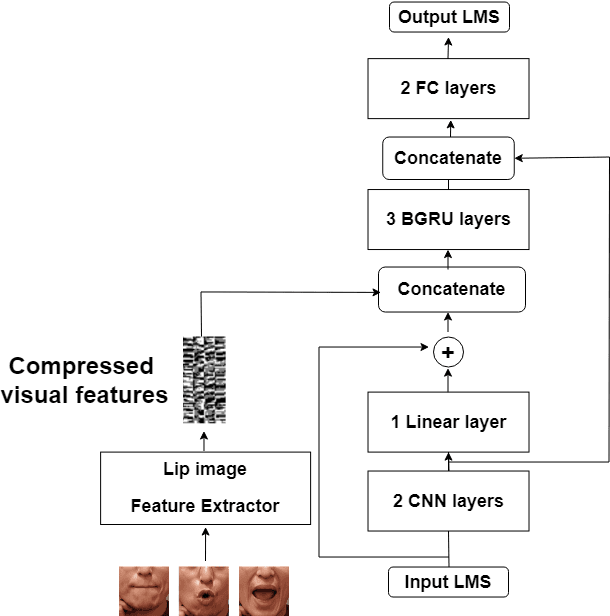
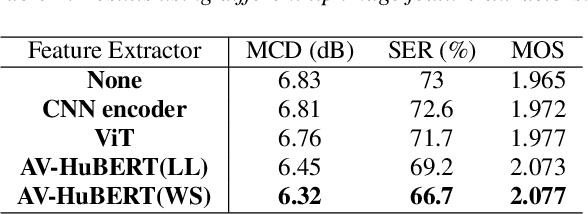
Electrolarynx is a commonly used assistive device to help patients with removed vocal cords regain their ability to speak. Although the electrolarynx can generate excitation signals like the vocal cords, the naturalness and intelligibility of electrolaryngeal (EL) speech are very different from those of natural (NL) speech. Many deep-learning-based models have been applied to electrolaryngeal speech voice conversion (ELVC) for converting EL speech to NL speech. In this study, we propose a multimodal voice conversion (VC) model that integrates acoustic and visual information into a unified network. We compared different pre-trained models as visual feature extractors and evaluated the effectiveness of these features in the ELVC task. The experimental results demonstrate that the proposed multimodal VC model outperforms single-modal models in both objective and subjective metrics, suggesting that the integration of visual information can significantly improve the quality of ELVC.
Speech Enhancement-assisted Stargan Voice Conversion in Noisy Environments
Oct 19, 2021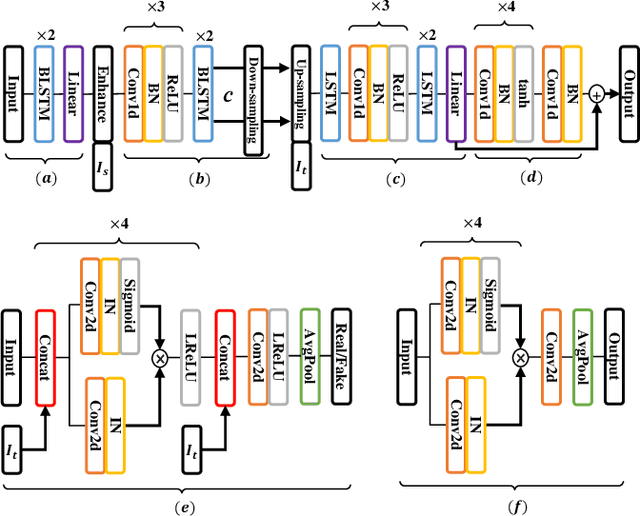

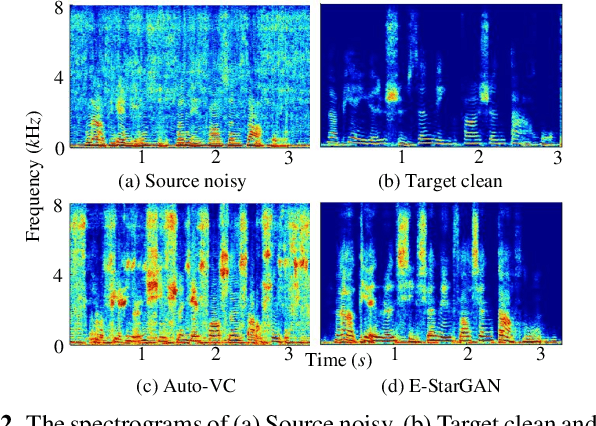
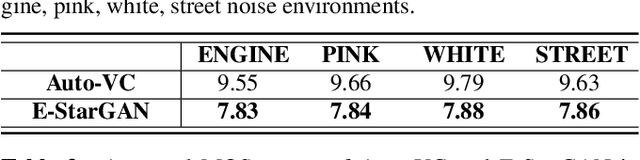
Numerous voice conversion (VC) techniques have been proposed for the conversion of voices among different speakers. Although the decent quality of converted speech can be observed when VC is applied in a clean environment, the quality will drop sharply when the system is running under noisy conditions. In order to address this issue, we propose a novel enhancement-based StarGAN (E-StarGAN) VC system, which leverages a speech enhancement (SE) technique for signal pre-processing. SE systems are generally used to reduce noise components in noisy speech and to generate enhanced speech for downstream application tasks. Therefore, we investigated the effectiveness of E-StarGAN, which combines VC and SE, and demonstrated the robustness of the proposed approach in various noisy environments. The results of VC experiments conducted on a Mandarin dataset show that when combined with SE, the proposed E-StarGAN VC model is robust to unseen noises. In addition, the subjective listening test results show that the proposed E-StarGAN model can improve the sound quality of speech signals converted from noise-corrupted source utterances.
Attention-based multi-task learning for speech-enhancement and speaker-identification in multi-speaker dialogue scenario
Jan 07, 2021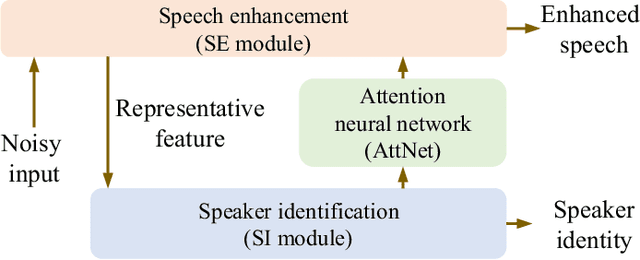
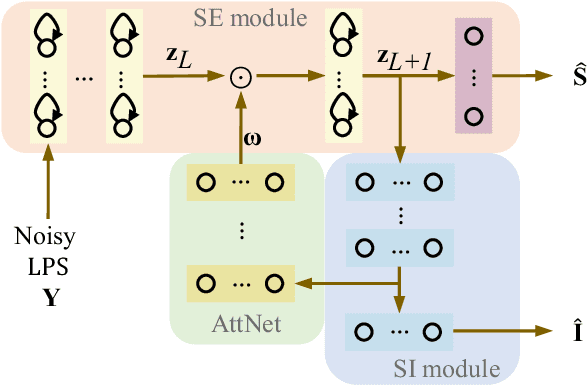
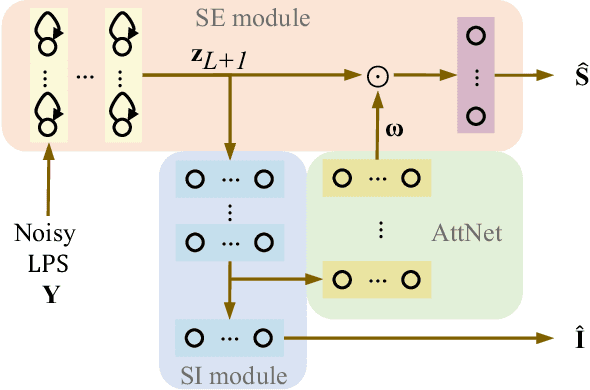
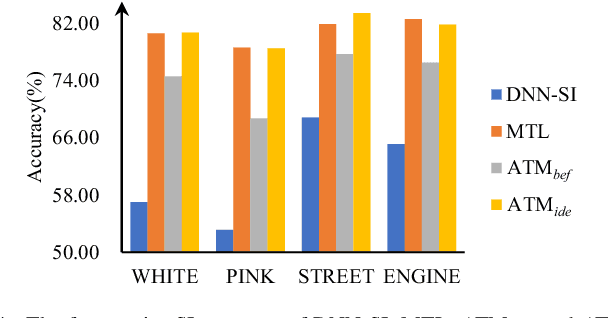
Multi-task learning (MTL) and the attention technique have been proven to effectively extract robust acoustic features for various speech-related applications in noisy environments. In this study, we integrated MTL and the attention-weighting mechanism and propose an attention-based MTL (ATM0 approach to realize a multi-model learning structure and to promote the speech enhancement (SE) and speaker identification (SI) systems simultaneously. There are three subsystems in the proposed ATM: SE, SI, and attention-Net (AttNet). In the proposed system, a long-short-term memory (LSTM) is used to perform SE, while a deep neural network (DNN) model is applied to construct SI and AttNet in ATM. The overall ATM system first extracts the representative features and then enhances the speech spectra in LSTM-SE and classifies speaker identity in DNN-SI. We conducted our experiment on Taiwan Mandarin hearing in noise test database. The evaluation results indicate that the proposed ATM system not only increases the quality and intelligibility of noisy speech input but also improves the accuracy of the SI system when compared to the conventional MTL approaches.
Neural Network Based Next-Song Recommendation
Jun 24, 2016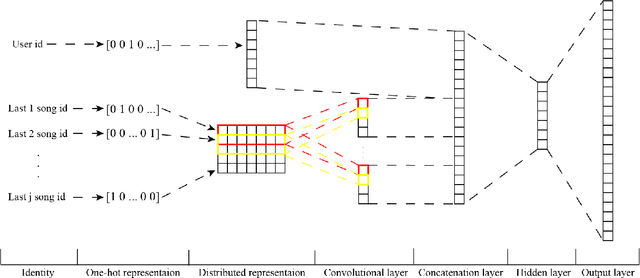
Recently, the next-item/basket recommendation system, which considers the sequential relation between bought items, has drawn attention of researchers. The utilization of sequential patterns has boosted performance on several kinds of recommendation tasks. Inspired by natural language processing (NLP) techniques, we propose a novel neural network (NN) based next-song recommender, CNN-rec, in this paper. Then, we compare the proposed system with several NN based and classic recommendation systems on the next-song recommendation task. Verification results indicate the proposed system outperforms classic systems and has comparable performance with the state-of-the-art system.