 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Mandarin Electrolaryngeal Speech Voice Conversion
Jun 11, 2023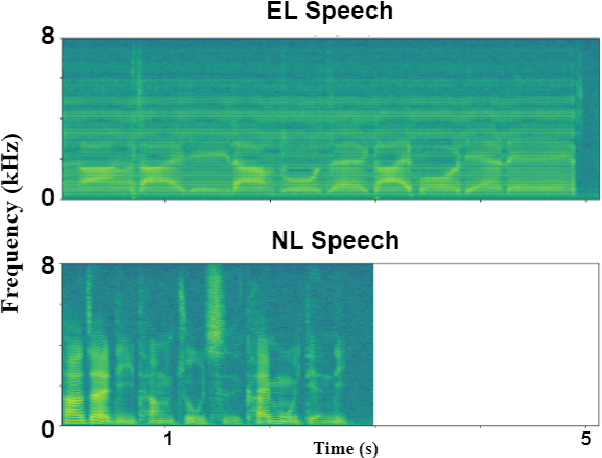

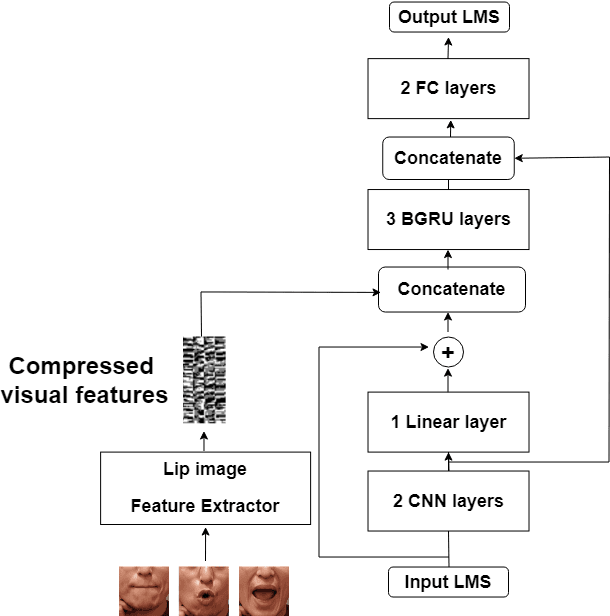
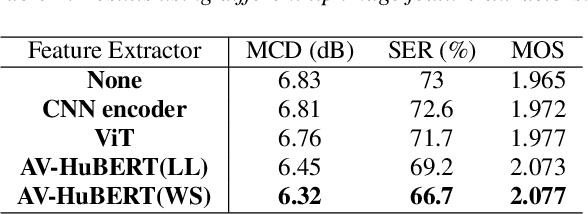
Electrolarynx is a commonly used assistive device to help patients with removed vocal cords regain their ability to speak. Although the electrolarynx can generate excitation signals like the vocal cords, the naturalness and intelligibility of electrolaryngeal (EL) speech are very different from those of natural (NL) speech. Many deep-learning-based models have been applied to electrolaryngeal speech voice conversion (ELVC) for converting EL speech to NL speech. In this study, we propose a multimodal voice conversion (VC) model that integrates acoustic and visual information into a unified network. We compared different pre-trained models as visual feature extractors and evaluated the effectiveness of these features in the ELVC task. The experimental results demonstrate that the proposed multimodal VC model outperforms single-modal models in both objective and subjective metrics, suggesting that the integration of visual information can significantly improve the quality of ELVC.
Mandarin Electrolaryngeal Speech Voice Conversion using Cross-domain Features
Jun 11, 2023Patients who have had their entire larynx removed, including the vocal folds, owing to throat cancer may experience difficulties in speaking. In such cases, electrolarynx devices are often prescribed to produce speech, which is commonly referred to as electrolaryngeal speech (EL speech). However, the quality and intelligibility of EL speech are poor. To address this problem, EL voice conversion (ELVC) is a method used to improve the intelligibility and quality of EL speech. In this paper, we propose a novel ELVC system that incorporates cross-domain features, specifically spectral features and self-supervised learning (SSL) embeddings. The experimental results show that applying cross-domain features can notably improve the conversion performance for the ELVC task compared with utilizing only traditional spectral features.