 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePop Music Highlighter: Marking the Emotion Keypoints
Sep 25, 2018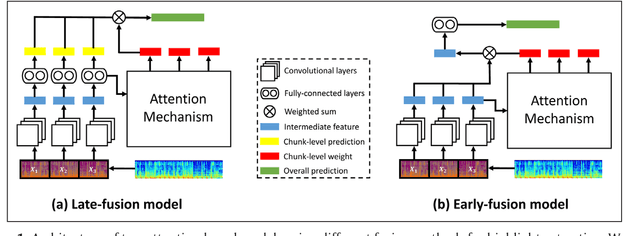
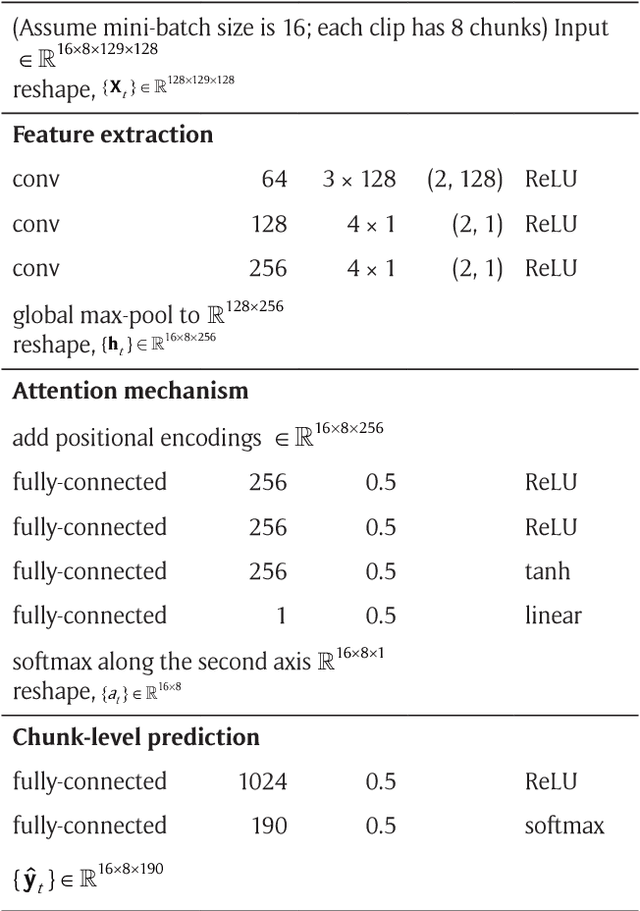
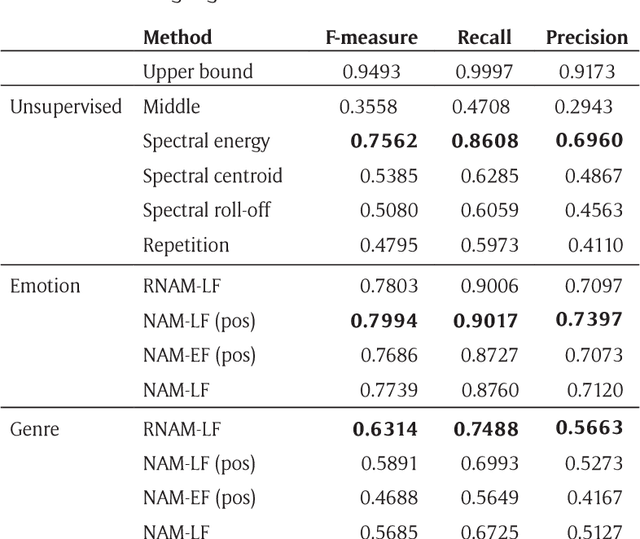
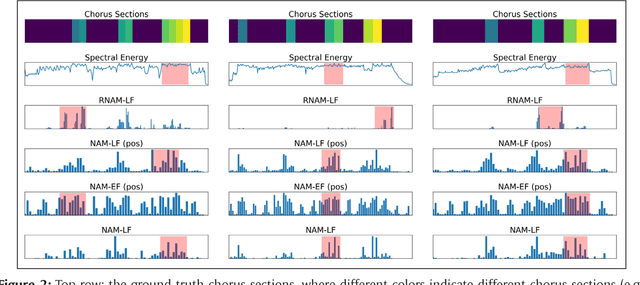
The goal of music highlight extraction is to get a short consecutive segment of a piece of music that provides an effective representation of the whole piece. In a previous work, we introduced an attention-based convolutional recurrent neural network that uses music emotion classification as a surrogate task for music highlight extraction, for Pop songs. The rationale behind that approach is that the highlight of a song is usually the most emotional part. This paper extends our previous work in the following two aspects. First, methodology-wise we experiment with a new architecture that does not need any recurrent layers, making the training process faster. Moreover, we compare a late-fusion variant and an early-fusion variant to study which one better exploits the attention mechanism. Second, we conduct and report an extensive set of experiments comparing the proposed attention-based methods against a heuristic energy-based method, a structural repetition-based method, and a few other simple feature-based methods for this task. Due to the lack of public-domain labeled data for highlight extraction, following our previous work we use the RWC POP 100-song data set to evaluate how the detected highlights overlap with any chorus sections of the songs. The experiments demonstrate the effectiveness of our methods over competing methods. For reproducibility, we open source the code and pre-trained model at https://github.com/remyhuang/pop-music-highlighter/.
Generating Music Medleys via Playing Music Puzzle Games
Nov 17, 2017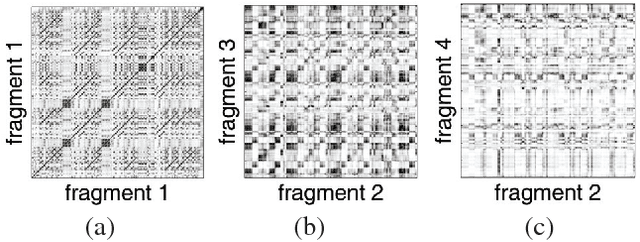
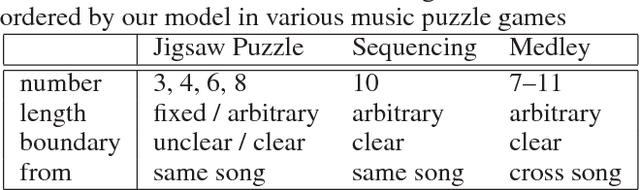
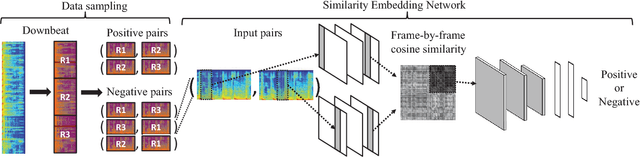
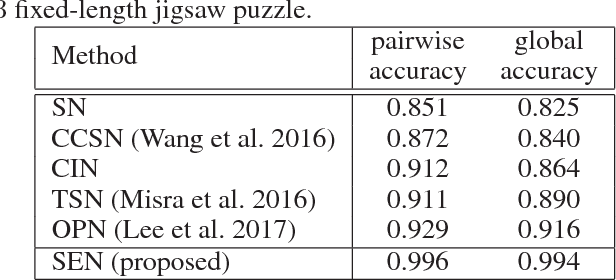
Generating music medleys is about finding an optimal permutation of a given set of music clips. Toward this goal, we propose a self-supervised learning task, called the music puzzle game, to train neural network models to learn the sequential patterns in music. In essence, such a game requires machines to correctly sort a few multisecond music fragments. In the training stage, we learn the model by sampling multiple non-overlapping fragment pairs from the same songs and seeking to predict whether a given pair is consecutive and is in the correct chronological order. For testing, we design a number of puzzle games with different difficulty levels, the most difficult one being music medley, which requiring sorting fragments from different songs. On the basis of state-of-the-art Siamese convolutional network, we propose an improved architecture that learns to embed frame-level similarity scores computed from the input fragment pairs to a common space, where fragment pairs in the correct order can be more easily identified. Our result shows that the resulting model, dubbed as the similarity embedding network (SEN), performs better than competing models across different games, including music jigsaw puzzle, music sequencing, and music medley. Example results can be found at our project website, https://remyhuang.github.io/DJnet.
MidiNet: A Convolutional Generative Adversarial Network for Symbolic-domain Music Generation
Jul 18, 2017
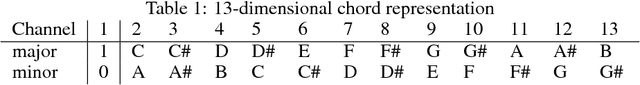

Most existing neural network models for music generation use recurrent neural networks. However, the recent WaveNet model proposed by DeepMind shows that convolutional neural networks (CNNs) can also generate realistic musical waveforms in the audio domain. Following this light, we investigate using CNNs for generating melody (a series of MIDI notes) one bar after another in the symbolic domain. In addition to the generator, we use a discriminator to learn the distributions of melodies, making it a generative adversarial network (GAN). Moreover, we propose a novel conditional mechanism to exploit available prior knowledge, so that the model can generate melodies either from scratch, by following a chord sequence, or by conditioning on the melody of previous bars (e.g. a priming melody), among other possibilities. The resulting model, named MidiNet, can be expanded to generate music with multiple MIDI channels (i.e. tracks). We conduct a user study to compare the melody of eight-bar long generated by MidiNet and by Google's MelodyRNN models, each time using the same priming melody. Result shows that MidiNet performs comparably with MelodyRNN models in being realistic and pleasant to listen to, yet MidiNet's melodies are reported to be much more interesting.
Revisiting the problem of audio-based hit song prediction using convolutional neural networks
Apr 05, 2017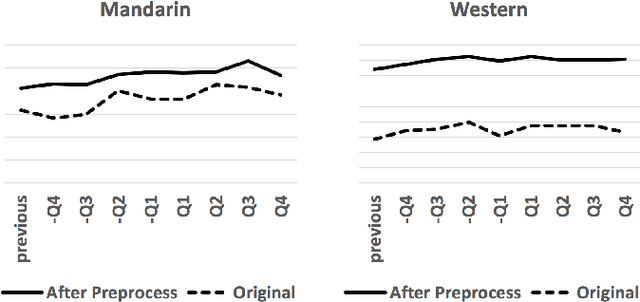
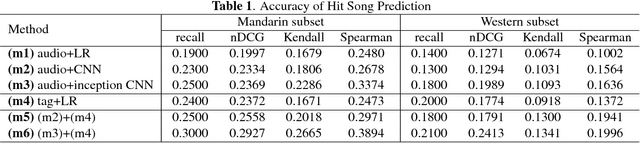
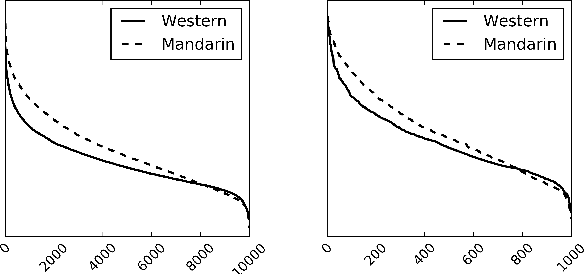
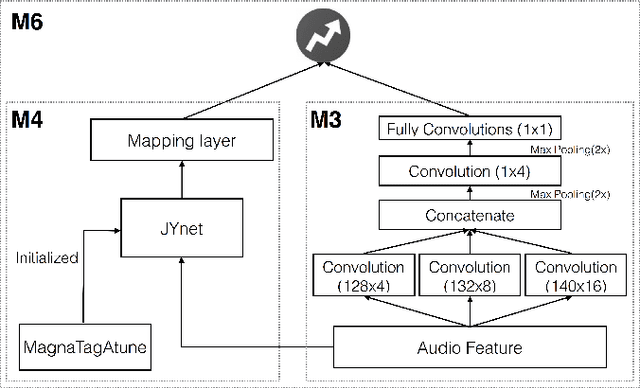
Being able to predict whether a song can be a hit has impor- tant applications in the music industry. Although it is true that the popularity of a song can be greatly affected by exter- nal factors such as social and commercial influences, to which degree audio features computed from musical signals (whom we regard as internal factors) can predict song popularity is an interesting research question on its own. Motivated by the recent success of deep learning techniques, we attempt to ex- tend previous work on hit song prediction by jointly learning the audio features and prediction models using deep learning. Specifically, we experiment with a convolutional neural net- work model that takes the primitive mel-spectrogram as the input for feature learning, a more advanced JYnet model that uses an external song dataset for supervised pre-training and auto-tagging, and the combination of these two models. We also consider the inception model to characterize audio infor- mation in different scales. Our experiments suggest that deep structures are indeed more accurate than shallow structures in predicting the popularity of either Chinese or Western Pop songs in Taiwan. We also use the tags predicted by JYnet to gain insights into the result of different models.
Neural Network Based Next-Song Recommendation
Jun 24, 2016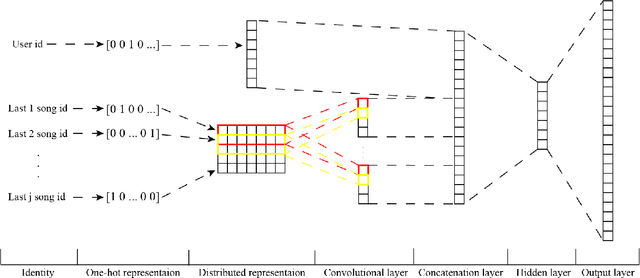
Recently, the next-item/basket recommendation system, which considers the sequential relation between bought items, has drawn attention of researchers. The utilization of sequential patterns has boosted performance on several kinds of recommendation tasks. Inspired by natural language processing (NLP) techniques, we propose a novel neural network (NN) based next-song recommender, CNN-rec, in this paper. Then, we compare the proposed system with several NN based and classic recommendation systems on the next-song recommendation task. Verification results indicate the proposed system outperforms classic systems and has comparable performance with the state-of-the-art system.