 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVSNet+: Enhancing Speaker Voice Similarity Assessment Models with Representations from Speech Foundation Models
Paper and Code
Jun 12, 2024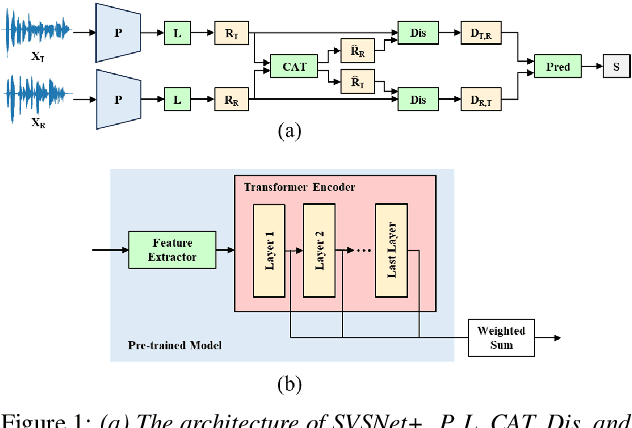



Representations from pre-trained speech foundation models (SFMs) have shown impressive performance in many downstream tasks. However, the potential benefits of incorporating pre-trained SFM representations into speaker voice similarity assessment have not been thoroughly investigated. In this paper, we propose SVSNet+, a model that integrates pre-trained SFM representations to improve performance in assessing speaker voice similarity. Experimental results on the Voice Conversion Challenge 2018 and 2020 datasets show that SVSNet+ incorporating WavLM representations shows significant improvements compared to baseline models. In addition, while fine-tuning WavLM with a small dataset of the downstream task does not improve performance, using the same dataset to learn a weighted-sum representation of WavLM can substantially improve performance. Furthermore, when WavLM is replaced by other SFMs, SVSNet+ still outperforms the baseline models and exhibits strong generalization ability.