 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCITISEN: A Deep Learning-Based Speech Signal-Processing Mobile Application
Paper and Code
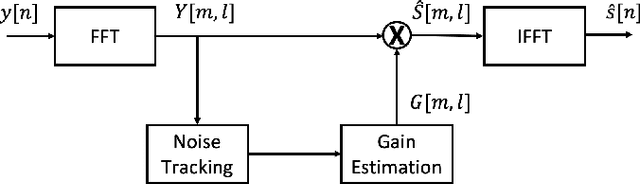
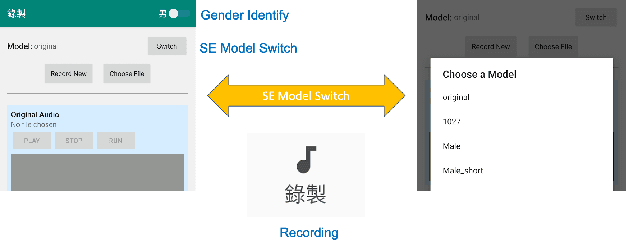
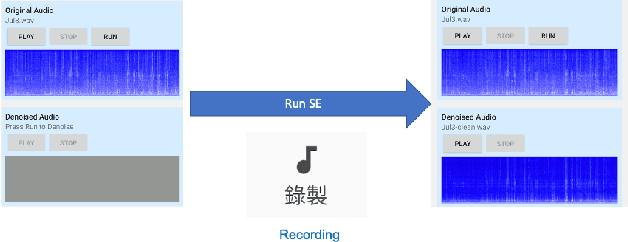
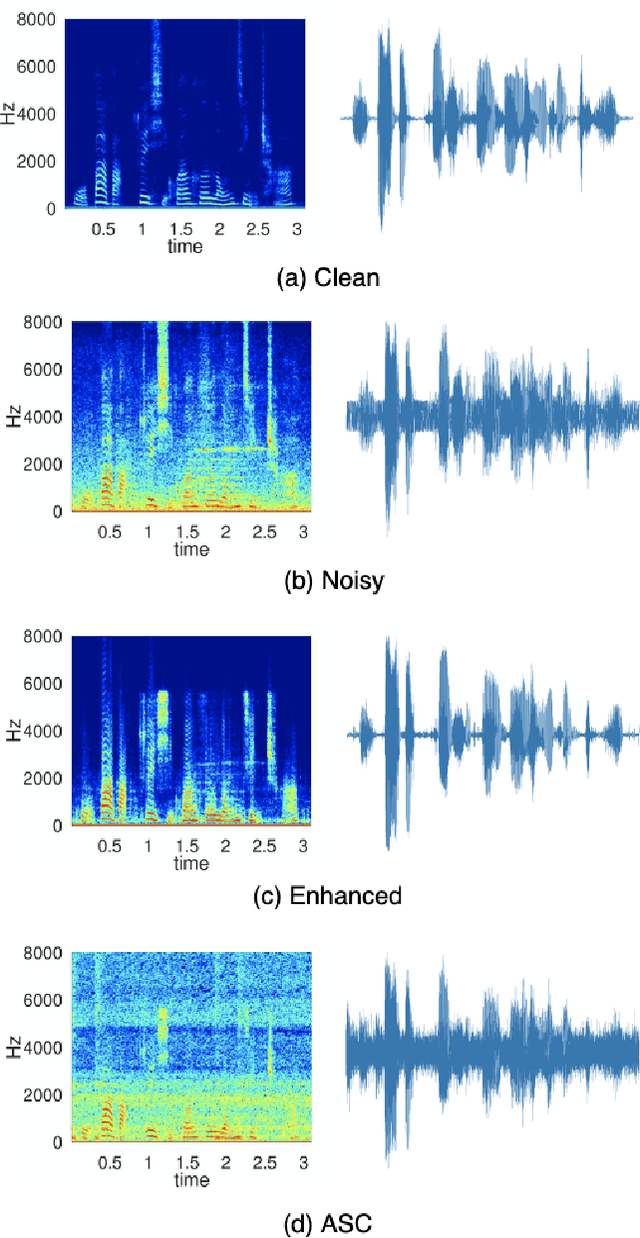
In this paper, we present a deep learning-based speech signal-processing mobile application, CITISEN, which can perform three functions: speech enhancement (SE), acoustic scene conversion (ASC), and model adaptation (MA). For SE, CITISEN can effectively reduce noise components from speech signals and accordingly enhance their clarity and intelligibility. For ASC, CITISEN can convert the current background sound to a different background sound. Finally, for MA, CITISEN can effectively adapt an SE model, with a few audio files, when it encounters unknown speakers or noise types; the adapted SE model is used to enhance the upcoming noisy utterances. Experimental results confirmed the effectiveness of CITISEN in performing these three functions via objective evaluation and subjective listening tests. The promising results reveal that the developed CITISEN mobile application can potentially be used as a front-end processor for various speech-related services such as voice communication, assistive hearing devices, and virtual reality headsets.