Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inference For Neural Machine Translation
Paper and Code
Oct 07, 2020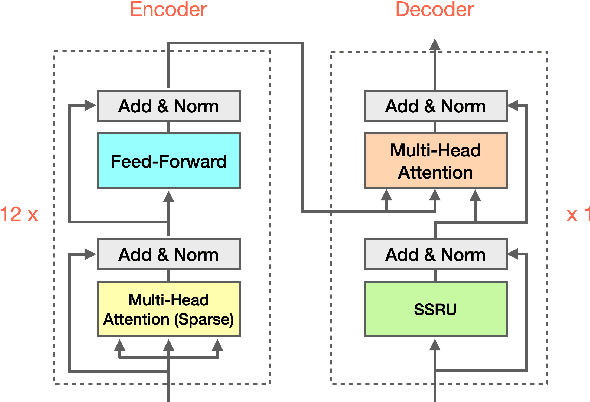
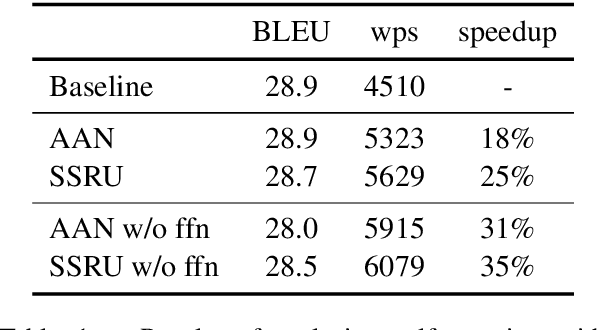
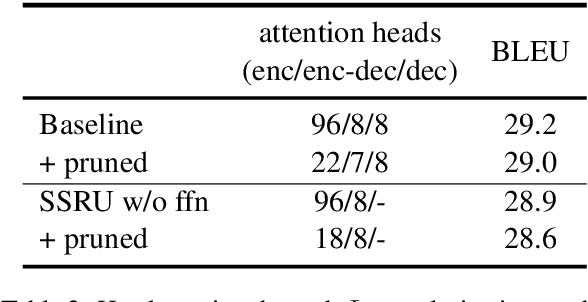
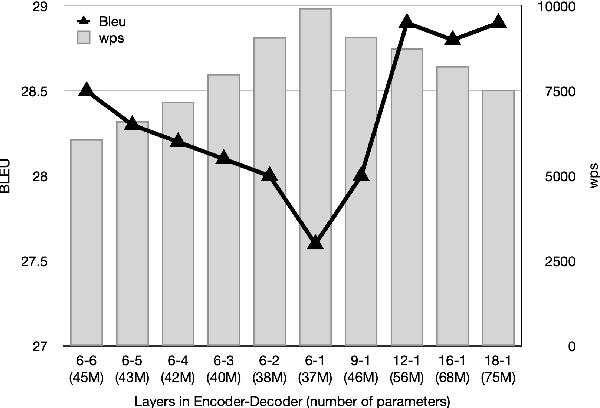
Large Transformer models have achieved state-of-the-art results in neural machine translation and have become standard in the field. In this work, we look for the optimal combination of known techniques to optimize inference speed without sacrificing translation quality. We conduct an empirical study that stacks various approaches and demonstrates that combination of replacing decoder self-attention with simplified recurrent units, adopting a deep encoder and a shallow decoder architecture and multi-head attention pruning can achieve up to 109% and 84% speedup on CPU and GPU respectively and reduce the number of parameters by 25% while maintaining the same translation quality in terms of BLEU.
* Accepted SustaiNLP 2020
View paper on