 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalBench.PT: A Benchmark for Portuguese Law
Feb 22, 2025The recent application of LLMs to the legal field has spurred the creation of benchmarks across various jurisdictions and languages. However, no benchmark has yet been specifically designed for the Portuguese legal system. In this work, we present LegalBench.PT, the first comprehensive legal benchmark covering key areas of Portuguese law. To develop LegalBench.PT, we first collect long-form questions and answers from real law exams, and then use GPT-4o to convert them into multiple-choice, true/false, and matching formats. Once generated, the questions are filtered and processed to improve the quality of the dataset. To ensure accuracy and relevance, we validate our approach by having a legal professional review a sample of the generated questions. Although the questions are synthetically generated, we show that their basis in human-created exams and our rigorous filtering and processing methods applied result in a reliable benchmark for assessing LLMs' legal knowledge and reasoning abilities. Finally, we evaluate the performance of leading LLMs on LegalBench.PT and investigate potential biases in GPT-4o's responses. We also assess the performance of Portuguese lawyers on a sample of questions to establish a baseline for model comparison and validate the benchmark.
SaulLM-7B: A pioneering Large Language Model for Law
Mar 07, 2024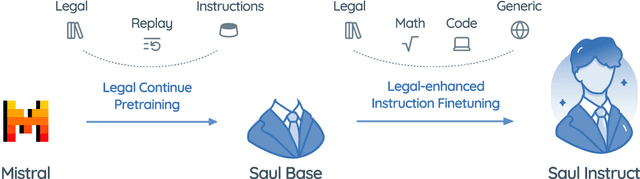
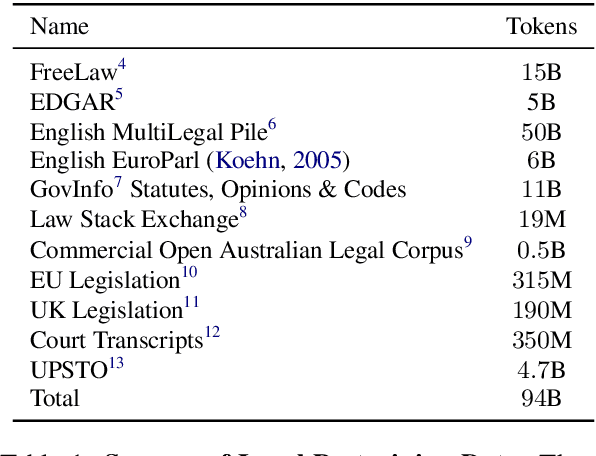


In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens. SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B's performance in legal tasks. SaulLM-7B is released under the MIT License.
One Wide Feedforward is All You Need
Sep 04, 2023



The Transformer architecture has two main non-embedding components: Attention and the Feed Forward Network (FFN). Attention captures interdependencies between words regardless of their position, while the FFN non-linearly transforms each input token independently. In this work we explore the role of the FFN, and find that despite taking up a significant fraction of the model's parameters, it is highly redundant. Concretely, we are able to substantially reduce the number of parameters with only a modest drop in accuracy by removing the FFN on the decoder layers and sharing a single FFN across the encoder. Finally we scale this architecture back to its original size by increasing the hidden dimension of the shared FFN, achieving substantial gains in both accuracy and latency with respect to the original Transformer Big.
Learning Language-Specific Layers for Multilingual Machine Translation
May 04, 2023Multilingual Machine Translation promises to improve translation quality between non-English languages. This is advantageous for several reasons, namely lower latency (no need to translate twice), and reduced error cascades (e.g., avoiding losing gender and formality information when translating through English). On the downside, adding more languages reduces model capacity per language, which is usually countered by increasing the overall model size, making training harder and inference slower. In this work, we introduce Language-Specific Transformer Layers (LSLs), which allow us to increase model capacity, while keeping the amount of computation and the number of parameters used in the forward pass constant. The key idea is to have some layers of the encoder be source or target language-specific, while keeping the remaining layers shared. We study the best way to place these layers using a neural architecture search inspired approach, and achieve an improvement of 1.3 chrF (1.5 spBLEU) points over not using LSLs on a separate decoder architecture, and 1.9 chrF (2.2 spBLEU) on a shared decoder one.
State Spaces Aren't Enough: Machine Translation Needs Attention
Apr 25, 2023Structured State Spaces for Sequences (S4) is a recently proposed sequence model with successful applications in various tasks, e.g. vision, language modeling, and audio. Thanks to its mathematical formulation, it compresses its input to a single hidden state, and is able to capture long range dependencies while avoiding the need for an attention mechanism. In this work, we apply S4 to Machine Translation (MT), and evaluate several encoder-decoder variants on WMT'14 and WMT'16. In contrast with the success in language modeling, we find that S4 lags behind the Transformer by approximately 4 BLEU points, and that it counter-intuitively struggles with long sentences. Finally, we show that this gap is caused by S4's inability to summarize the full source sentence in a single hidden state, and show that we can close the gap by introducing an attention mechanism.