 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Visual Saliency of Outlier Items in Product Search
Mar 30, 2025



In two-sided marketplaces, items compete for user attention, which translates to revenue for suppliers. Item exposure, indicated by the amount of attention items receive in a ranking, can be influenced by factors like position bias. Recent work suggests that inter-item dependencies, such as outlier items in a ranking, also affect item exposure. Outlier items are items that observably deviate from the other items in a ranked list. Understanding outlier items is crucial for determining an item's exposure distribution. In our previous work, we investigated the impact of different presentational features on users' perception of outlier in search results. In this work, we focus on two key questions left unanswered by our previous work: (i) What is the effect of isolated bottom-up visual factors on item outlierness in product lists? (ii) How do top-down factors influence users' perception of item outlierness in a realistic online shopping scenario? We start with bottom-up factors and employ visual saliency models to evaluate their ability to detect outlier items in product lists purely based on visual attributes. Then, to examine top-down factors, we conduct eye-tracking experiments on an online shopping task. Moreover, we employ eye-tracking to not only be closer to the real-world case but also to address the accuracy problem of reaction time in the visual search task. Our experiments show the ability of visual saliency models to detect bottom-up factors, consistently highlighting areas with strong visual contrasts. The results of our eye-tracking experiment for lists without outliers show that despite being less visually attractive, product descriptions captured attention the fastest, indicating the importance of top-down factors. In our eye-tracking experiments, we observed that outlier items engaged users for longer durations compared to non-outlier items.
On the Impact of Outlier Bias on User Clicks
May 01, 2023User interaction data is an important source of supervision in counterfactual learning to rank (CLTR). Such data suffers from presentation bias. Much work in unbiased learning to rank (ULTR) focuses on position bias, i.e., items at higher ranks are more likely to be examined and clicked. Inter-item dependencies also influence examination probabilities, with outlier items in a ranking as an important example. Outliers are defined as items that observably deviate from the rest and therefore stand out in the ranking. In this paper, we identify and introduce the bias brought about by outlier items: users tend to click more on outlier items and their close neighbors. To this end, we first conduct a controlled experiment to study the effect of outliers on user clicks. Next, to examine whether the findings from our controlled experiment generalize to naturalistic situations, we explore real-world click logs from an e-commerce platform. We show that, in both scenarios, users tend to click significantly more on outlier items than on non-outlier items in the same rankings. We show that this tendency holds for all positions, i.e., for any specific position, an item receives more interactions when presented as an outlier as opposed to a non-outlier item. We conclude from our analysis that the effect of outliers on clicks is a type of bias that should be addressed in ULTR. We therefore propose an outlier-aware click model that accounts for both outlier and position bias, called outlier-aware position-based model ( OPBM). We estimate click propensities based on OPBM ; through extensive experiments performed on both real-world e-commerce data and semi-synthetic data, we verify the effectiveness of our outlier-aware click model. Our results show the superiority of OPBM against baselines in terms of ranking performance and true relevance estimation.
Fairness of Exposure in Light of Incomplete Exposure Estimation
May 25, 2022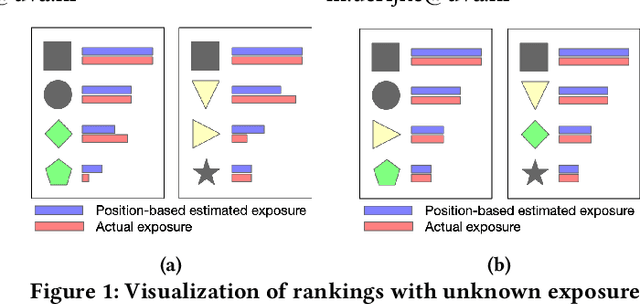
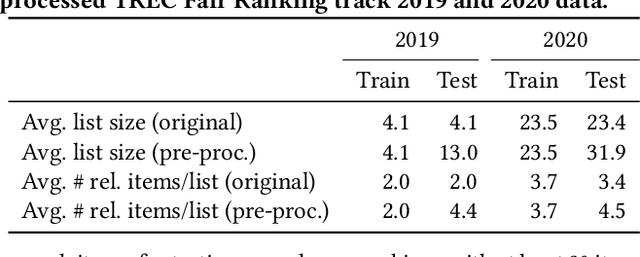
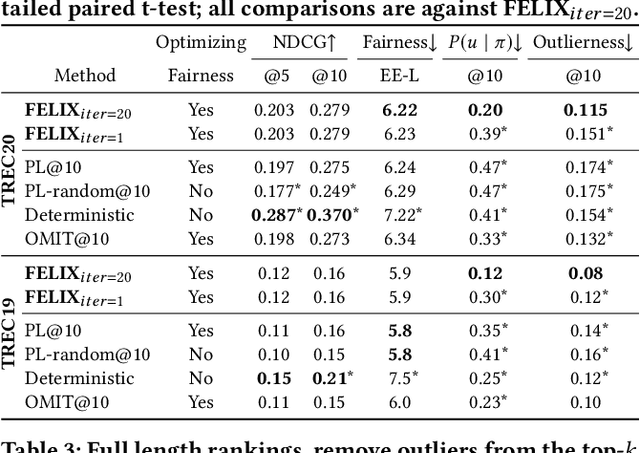
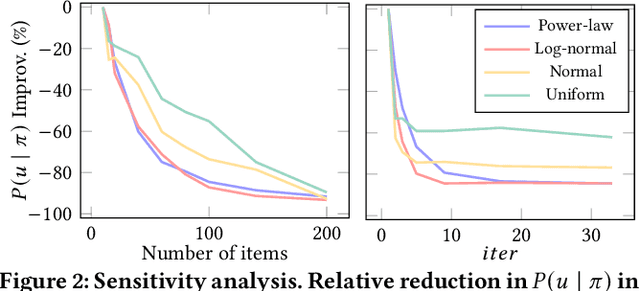
Fairness of exposure is a commonly used notion of fairness for ranking systems. It is based on the idea that all items or item groups should get exposure proportional to the merit of the item or the collective merit of the items in the group. Often, stochastic ranking policies are used to ensure fairness of exposure. Previous work unrealistically assumes that we can reliably estimate the expected exposure for all items in each ranking produced by the stochastic policy. In this work, we discuss how to approach fairness of exposure in cases where the policy contains rankings of which, due to inter-item dependencies, we cannot reliably estimate the exposure distribution. In such cases, we cannot determine whether the policy can be considered fair. Our contributions in this paper are twofold. First, we define a method called FELIX for finding stochastic policies that avoid showing rankings with unknown exposure distribution to the user without having to compromise user utility or item fairness. Second, we extend the study of fairness of exposure to the top-k setting and also assess FELIX in this setting. We find that FELIX can significantly reduce the number of rankings with unknown exposure distribution without a drop in user utility or fairness compared to existing fair ranking methods, both for full-length and top-k rankings. This is an important first step in developing fair ranking methods for cases where we have incomplete knowledge about the user's behaviour.
Probabilistic Permutation Graph Search: Black-Box Optimization for Fairness in Ranking
Apr 28, 2022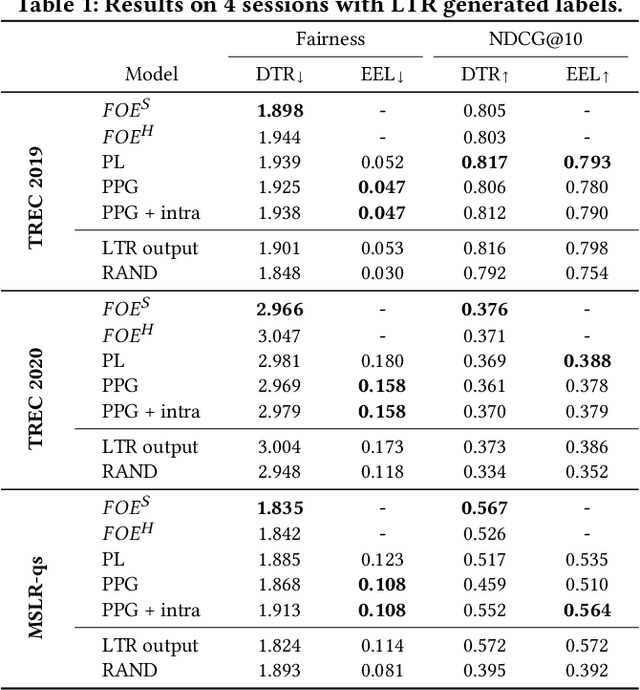
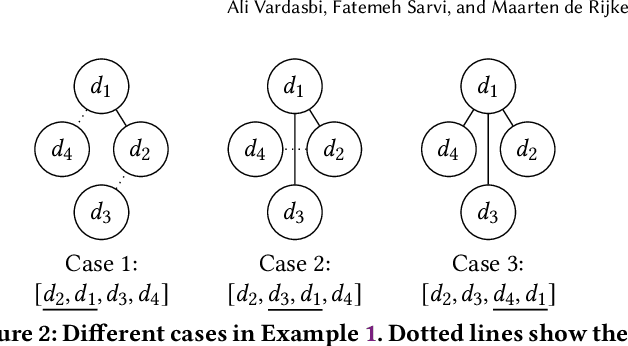
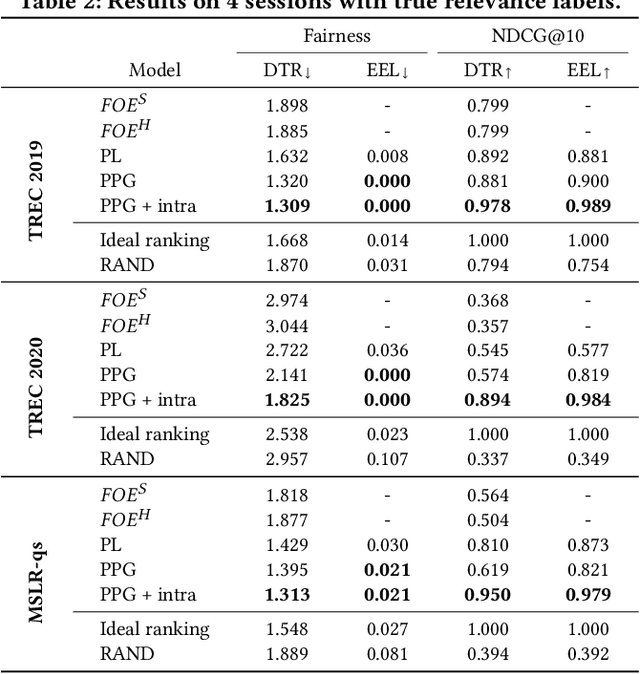
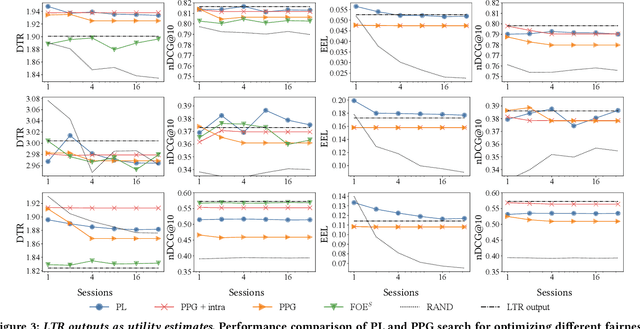
There are several measures for fairness in ranking, based on different underlying assumptions and perspectives. PL optimization with the REINFORCE algorithm can be used for optimizing black-box objective functions over permutations. In particular, it can be used for optimizing fairness measures. However, though effective for queries with a moderate number of repeating sessions, PL optimization has room for improvement for queries with a small number of repeating sessions. In this paper, we present a novel way of representing permutation distributions, based on the notion of permutation graphs. Similar to PL, our distribution representation, called PPG, can be used for black-box optimization of fairness. Different from PL, where pointwise logits are used as the distribution parameters, in PPG pairwise inversion probabilities together with a reference permutation construct the distribution. As such, the reference permutation can be set to the best sampled permutation regarding the objective function, making PPG suitable for both deterministic and stochastic rankings. Our experiments show that PPG, while comparable to PL for larger session repetitions (i.e., stochastic ranking), improves over PL for optimizing fairness metrics for queries with one session (i.e., deterministic ranking). Additionally, when accurate utility estimations are available, e.g., in tabular models, the performance of PPG in fairness optimization is significantly boosted compared to lower quality utility estimations from a learning to rank model, leading to a large performance gap with PL. Finally, the pairwise probabilities make it possible to impose pairwise constraints such as "item $d_1$ should always be ranked higher than item $d_2$." Such constraints can be used to simultaneously optimize the fairness metric and control another objective such as ranking performance.
Understanding and Mitigating the Effect of Outliers in Fair Ranking
Jan 03, 2022

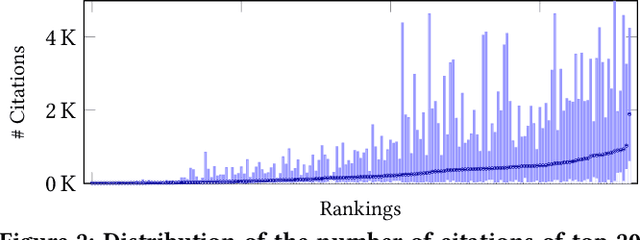
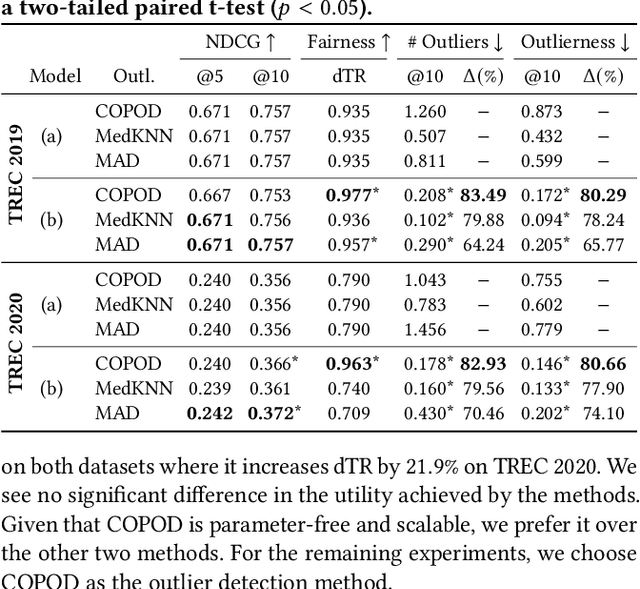
Traditional ranking systems are expected to sort items in the order of their relevance and thereby maximize their utility. In fair ranking, utility is complemented with fairness as an optimization goal. Recent work on fair ranking focuses on developing algorithms to optimize for fairness, given position-based exposure. In contrast, we identify the potential of outliers in a ranking to influence exposure and thereby negatively impact fairness. An outlier in a list of items can alter the examination probabilities, which can lead to different distributions of attention, compared to position-based exposure. We formalize outlierness in a ranking, show that outliers are present in realistic datasets, and present the results of an eye-tracking study, showing that users scanning order and the exposure of items are influenced by the presence of outliers. We then introduce OMIT, a method for fair ranking in the presence of outliers. Given an outlier detection method, OMIT improves fair allocation of exposure by suppressing outliers in the top-k ranking. Using an academic search dataset, we show that outlierness optimization leads to a fairer policy that displays fewer outliers in the top-k, while maintaining a reasonable trade-off between fairness and utility.