 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
Paper and Code
Oct 22, 2024
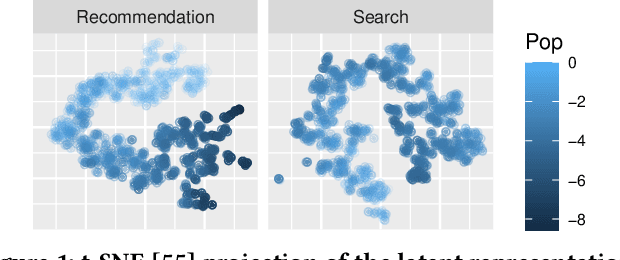


Generative retrieval for search and recommendation is a promising paradigm for retrieving items, offering an alternative to traditional methods that depend on external indexes and nearest-neighbor searches. Instead, generative models directly associate inputs with item IDs. Given the breakthroughs of Large Language Models (LLMs), these generative systems can play a crucial role in centralizing a variety of Information Retrieval (IR) tasks in a single model that performs tasks such as query understanding, retrieval, recommendation, explanation, re-ranking, and response generation. Despite the growing interest in such a unified generative approach for IR systems, the advantages of using a single, multi-task model over multiple specialized models are not well established in the literature. This paper investigates whether and when such a unified approach can outperform task-specific models in the IR tasks of search and recommendation, broadly co-existing in multiple industrial online platforms, such as Spotify, YouTube, and Netflix. Previous work shows that (1) the latent representations of items learned by generative recommenders are biased towards popularity, and (2) content-based and collaborative-filtering-based information can improve an item's representations. Motivated by this, our study is guided by two hypotheses: [H1] the joint training regularizes the estimation of each item's popularity, and [H2] the joint training regularizes the item's latent representations, where search captures content-based aspects of an item and recommendation captures collaborative-filtering aspects. Our extensive experiments with both simulated and real-world data support both [H1] and [H2] as key contributors to the effectiveness improvements observed in the unified search and recommendation generative models over the single-task approaches.