 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNUQSGD: Provably Communication-efficient Data-parallel SGD via Nonuniform Quantization
May 01, 2021

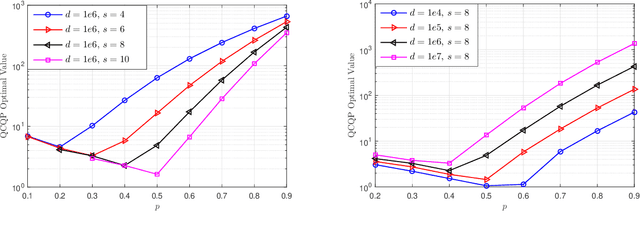
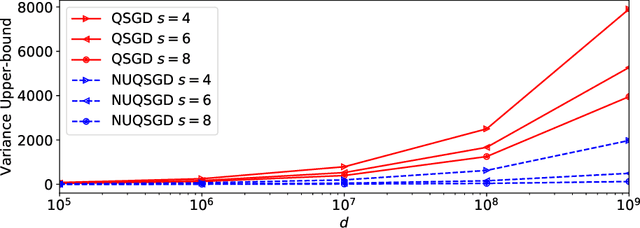
As the size and complexity of models and datasets grow, so does the need for communication-efficient variants of stochastic gradient descent that can be deployed to perform parallel model training. One popular communication-compression method for data-parallel SGD is QSGD (Alistarh et al., 2017), which quantizes and encodes gradients to reduce communication costs. The baseline variant of QSGD provides strong theoretical guarantees, however, for practical purposes, the authors proposed a heuristic variant which we call QSGDinf, which demonstrated impressive empirical gains for distributed training of large neural networks. In this paper, we build on this work to propose a new gradient quantization scheme, and show that it has both stronger theoretical guarantees than QSGD, and matches and exceeds the empirical performance of the QSGDinf heuristic and of other compression methods.