 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Dueling Bandits
Paper and Code
Jun 13, 2015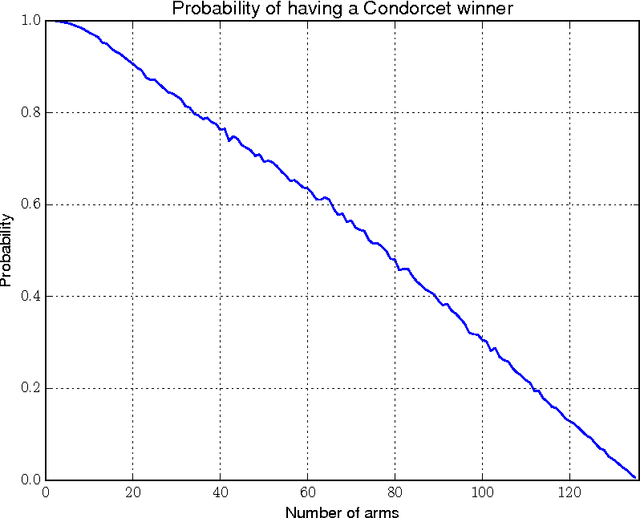
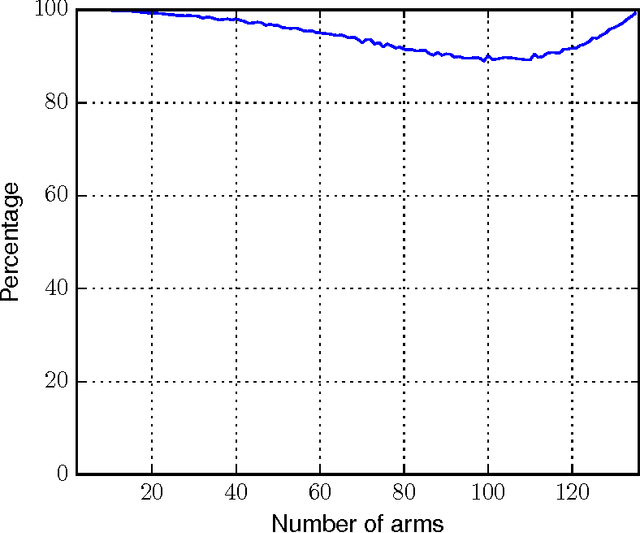
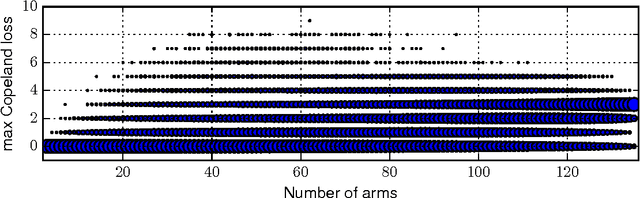
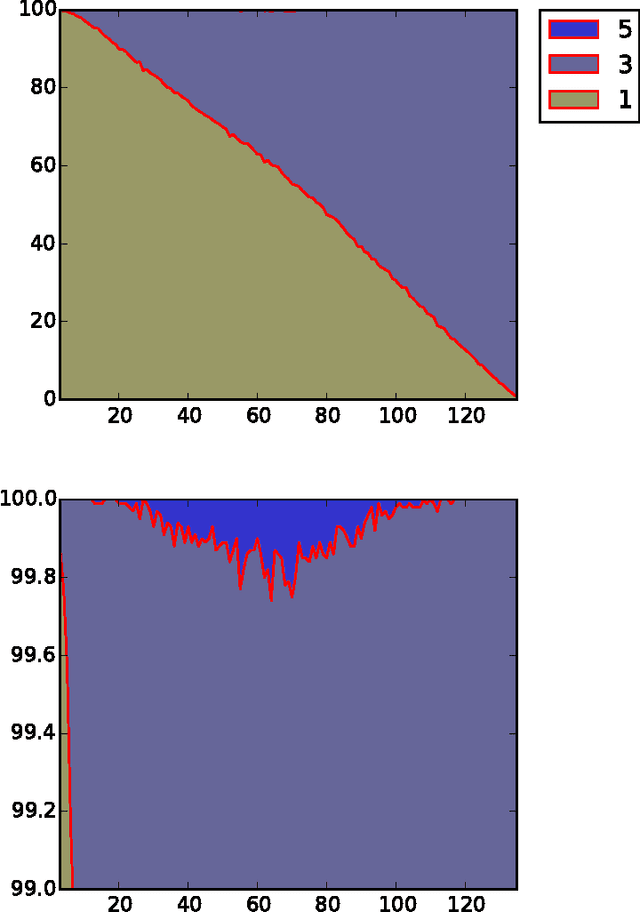
We consider the problem of learning to choose actions using contextual information when provided with limited feedback in the form of relative pairwise comparisons. We study this problem in the dueling-bandits framework of Yue et al. (2009), which we extend to incorporate context. Roughly, the learner's goal is to find the best policy, or way of behaving, in some space of policies, although "best" is not always so clearly defined. Here, we propose a new and natural solution concept, rooted in game theory, called a von Neumann winner, a randomized policy that beats or ties every other policy. We show that this notion overcomes important limitations of existing solutions, particularly the Condorcet winner which has typically been used in the past, but which requires strong and often unrealistic assumptions. We then present three efficient algorithms for online learning in our setting, and for approximating a von Neumann winner from batch-like data. The first of these algorithms achieves particularly low regret, even when data is adversarial, although its time and space requirements are linear in the size of the policy space. The other two algorithms require time and space only logarithmic in the size of the policy space when provided access to an oracle for solving classification problems on the space.