 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROIDS: Robust Outlier-Aware Informed Down-Sampling
Jan 27, 2026Informed down-sampling (IDS) is known to improve performance in symbolic regression when combined with various selection strategies, especially tournament selection. However, recent work found that IDS's gains are not consistent across all problems. Our analysis reveals that IDS performance is worse for problems containing outliers. IDS systematically favors including outliers in subsets which pushes GP towards finding solutions that overfit to outliers. To address this, we introduce ROIDS (Robust Outlier-Aware Informed Down-Sampling), which excludes potential outliers from the sampling process of IDS. With ROIDS it is possible to keep the advantages of IDS without overfitting to outliers and to compete on a wide range of benchmark problems. This is also reflected in our experiments in which ROIDS shows the desired behavior on all studied benchmark problems. ROIDS consistently outperforms IDS on synthetic problems with added outliers as well as on a wide range of complex real-world problems, surpassing IDS on over 80% of the real-world benchmark problems. Moreover, compared to all studied baseline approaches, ROIDS achieves the best average rank across all tested benchmark problems. This robust behavior makes ROIDS a reliable down-sampling method for selection in symbolic regression, especially when outliers may be included in the data set.
Was Tournament Selection All We Ever Needed? A Critical Reflection on Lexicase Selection
Feb 25, 2025



The success of lexicase selection has led to various extensions, including its combination with down-sampling, which further increased performance. However, recent work found that down-sampling also leads to significant improvements in the performance of tournament selection. This raises the question of whether tournament selection combined with down-sampling is the better choice, given its faster running times. To address this question, we run a set of experiments comparing epsilon-lexicase and tournament selection with different down-sampling techniques on synthetic problems of varying noise levels and problem sizes as well as real-world symbolic regression problems. Overall, we find that down-sampling improves generalization and performance even when compared over the same number of generations. This means that down-sampling is beneficial even with way fewer fitness evaluations. Additionally, down-sampling successfully reduces code growth. We observe that population diversity increases for tournament selection when combined with down-sampling. Further, we find that tournament selection and epsilon-lexicase selection with down-sampling perform similar, while tournament selection is significantly faster. We conclude that tournament selection should be further analyzed and improved in future work instead of only focusing on the improvement of lexicase variants.
Lexicase-based Selection Methods with Down-sampling for Symbolic Regression Problems: Overview and Benchmark
Jul 31, 2024
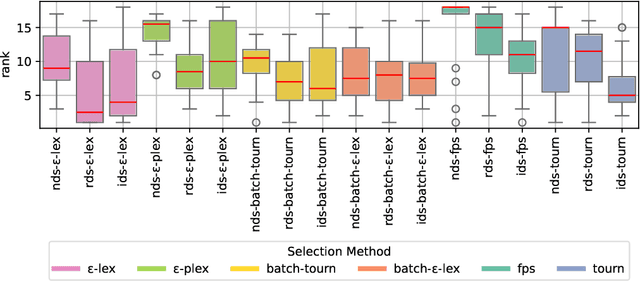

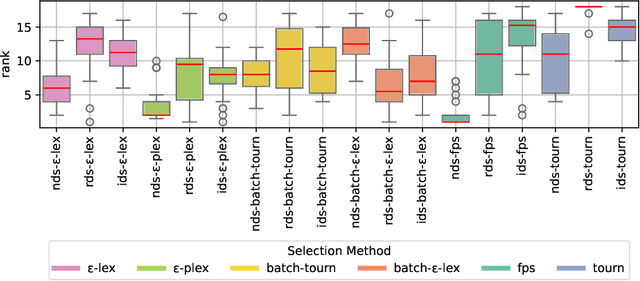
In recent years, several new lexicase-based selection variants have emerged due to the success of standard lexicase selection in various application domains. For symbolic regression problems, variants that use an epsilon-threshold or batches of training cases, among others, have led to performance improvements. Lately, especially variants that combine lexicase selection and down-sampling strategies have received a lot of attention. This paper evaluates random as well as informed down-sampling in combination with the relevant lexicase-based selection methods on a wide range of symbolic regression problems. In contrast to most work, we not only compare the methods over a given evaluation budget, but also over a given time as time is usually limited in practice. We find that for a given evaluation budget, epsilon-lexicase selection in combination with random or informed down-sampling outperforms all other methods. Only for a rather long running time of 24h, the best performing method is tournament selection in combination with informed down-sampling. If the given running time is very short, lexicase variants using batches of training cases perform best.
Enhancing Genetic Improvement Mutations Using Large Language Models
Oct 18, 2023Large language models (LLMs) have been successfully applied to software engineering tasks, including program repair. However, their application in search-based techniques such as Genetic Improvement (GI) is still largely unexplored. In this paper, we evaluate the use of LLMs as mutation operators for GI to improve the search process. We expand the Gin Java GI toolkit to call OpenAI's API to generate edits for the JCodec tool. We randomly sample the space of edits using 5 different edit types. We find that the number of patches passing unit tests is up to 75% higher with LLM-based edits than with standard Insert edits. Further, we observe that the patches found with LLMs are generally less diverse compared to standard edits. We ran GI with local search to find runtime improvements. Although many improving patches are found by LLM-enhanced GI, the best improving patch was found by standard GI.
Down-Sampled Epsilon-Lexicase Selection for Real-World Symbolic Regression Problems
Feb 08, 2023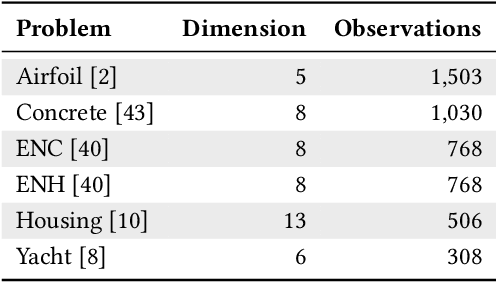
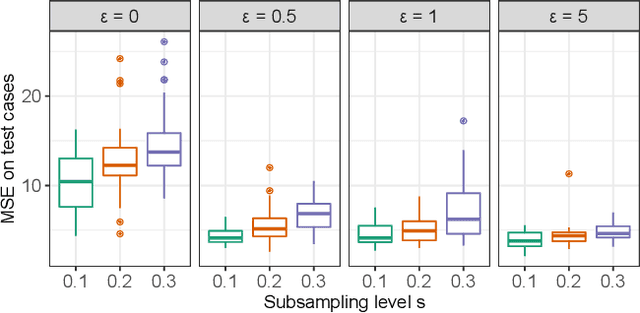

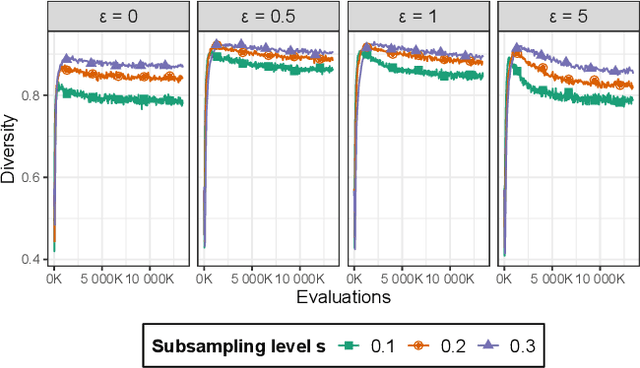
Epsilon-lexicase selection is a parent selection method in genetic programming that has been successfully applied to symbolic regression problems. Recently, the combination of random subsampling with lexicase selection significantly improved performance in other genetic programming domains such as program synthesis. However, the influence of subsampling on the solution quality of real-world symbolic regression problems has not yet been studied. In this paper, we propose down-sampled epsilon-lexicase selection which combines epsilon-lexicase selection with random subsampling to improve the performance in the domain of symbolic regression. Therefore, we compare down-sampled epsilon-lexicase with traditional selection methods on common real-world symbolic regression problems and analyze its influence on the properties of the population over a genetic programming run. We find that the diversity is reduced by using down-sampled epsilon-lexicase selection compared to standard epsilon-lexicase selection. This comes along with high hyperselection rates we observe for down-sampled epsilon-lexicase selection. Further, we find that down-sampled epsilon-lexicase selection outperforms the traditional selection methods on all studied problems. Overall, with down-sampled epsilon-lexicase selection we observe an improvement of the solution quality of up to 85% in comparison to standard epsilon-lexicase selection.