 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Performance Guarantee for Large Reasoning Models
Jan 30, 2026Large reasoning models have shown strong performance through extended chain-of-thought reasoning, yet their computational cost remains significant. Probably approximately correct (PAC) reasoning provides statistical guarantees for efficient reasoning by adaptively switching between thinking and non-thinking models, but the guarantee holds only in the marginal case and does not provide exact conditional coverage. We propose G-PAC reasoning, a practical framework that provides PAC-style guarantees at the group level by partitioning the input space. We develop two instantiations: Group PAC (G-PAC) reasoning for known group structures and Clustered PAC (C-PAC) reasoning for unknown groupings. We prove that both G-PAC and C-PAC achieve group-conditional risk control, and that grouping can strictly improve efficiency over marginal PAC reasoning in heterogeneous settings. Our experiments on diverse reasoning benchmarks demonstrate that G-PAC and C-PAC successfully achieve group-conditional risk control while maintaining substantial computational savings.
Anytime Safe PAC Efficient Reasoning
Jan 30, 2026Large Reasoning Models (LRMs) have demonstrated remarkable performance on complex tasks but suffer from high computational costs and latency. While selective thinking strategies improve efficiency by routing easy queries to non-thinking models, existing approaches often incur uncontrollable errors, especially in online settings where the performance loss of a non-thinking model is only partially observed and data are non-stationary. To address this, we propose Betting Probably Approximately Correct (B-PAC) reasoning, a principled method that enables anytime safe and efficient online reasoning under partial feedback. Specifically, we utilize inverse propensity scoring estimators to construct test supermartingales for candidate thresholds, and then dynamically adjust the routing threshold based on the accumulated statistical evidence of safety. Theoretically, we establish the anytime-valid performance loss control and the efficiency of B-PAC reasoning. Extensive experiments demonstrate that B-PAC reasoning significantly reduces computational overhead, decreasing thinking model usage by up to 81.01\%, while controlling the performance loss below the user-specified level.
HyPAC: Cost-Efficient LLMs-Human Hybrid Annotation with PAC Error Guarantees
Jan 30, 2026Data annotation often involves multiple sources with different cost-quality trade-offs, such as fast large language models (LLMs), slow reasoning models, and human experts. In this work, we study the problem of routing inputs to the most cost-efficient annotation source while controlling the labeling error on test instances. We propose \textbf{HyPAC}, a method that adaptively labels inputs to the most cost-efficient annotation source while providing distribution-free guarantees on annotation error. HyPAC calibrates two decision thresholds using importance sampling and upper confidence bounds, partitioning inputs into three regions based on uncertainty and routing each to the appropriate annotation source. We prove that HyPAC achieves the minimum expected cost with a probably approximately correct (PAC) guarantee on the annotation error, free of data distribution and pre-trained models. Experiments on common benchmarks demonstrate the effectiveness of our method, reducing the annotation cost by 78.51\% while tightly controlling the annotation error.
Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
MATAI: A Generalist Machine Learning Framework for Property Prediction and Inverse Design of Advanced Alloys
Nov 13, 2025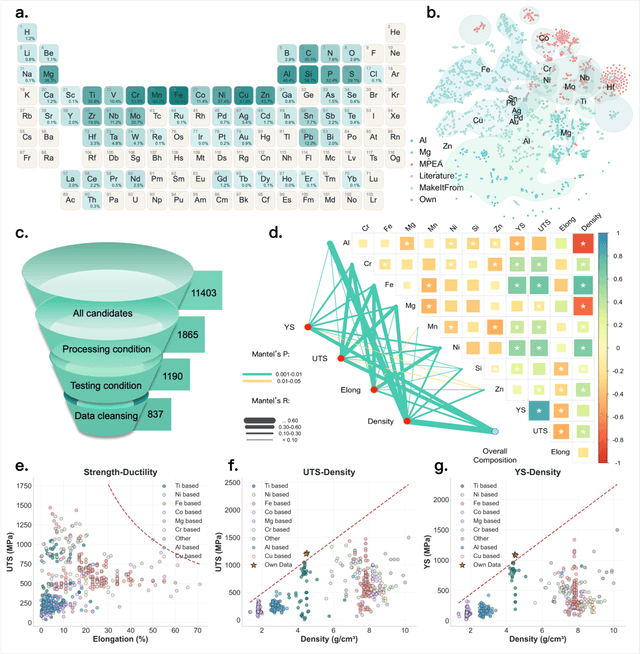
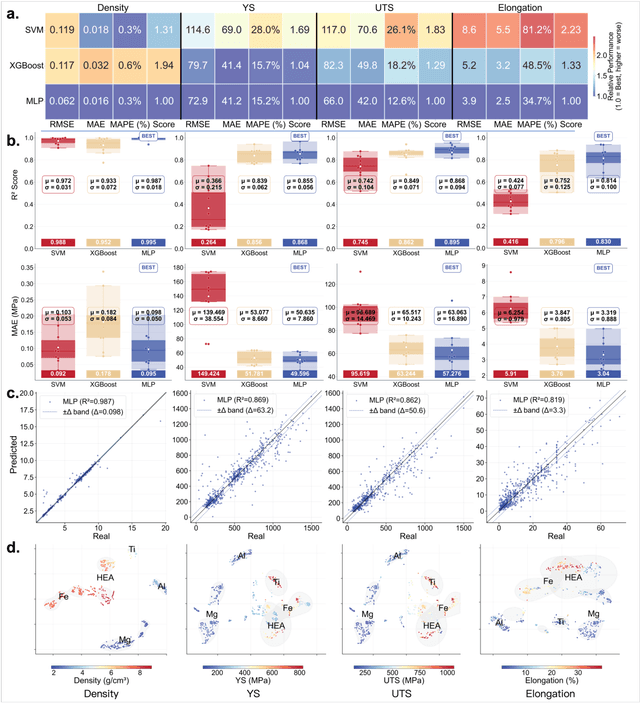
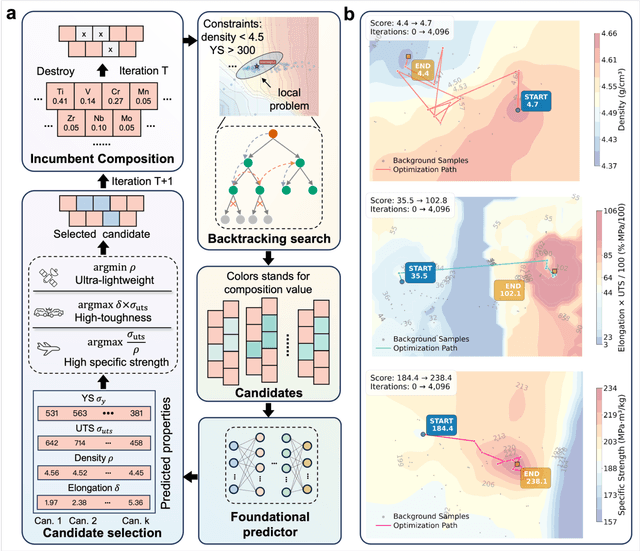
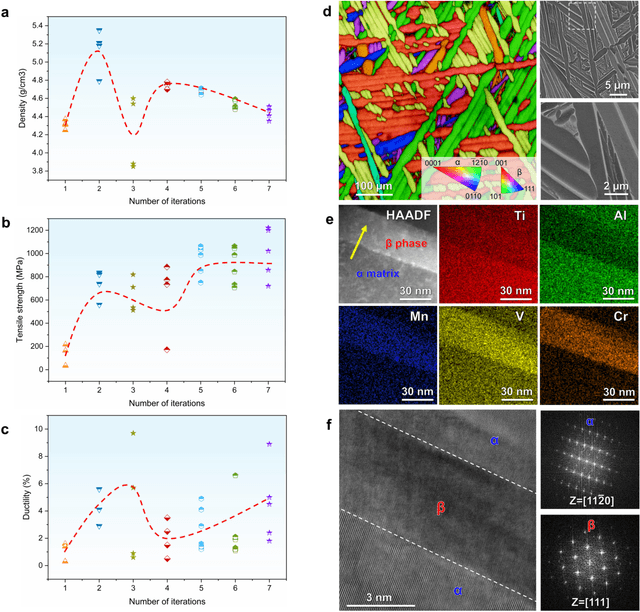
The discovery of advanced metallic alloys is hindered by vast composition spaces, competing property objectives, and real-world constraints on manufacturability. Here we introduce MATAI, a generalist machine learning framework for property prediction and inverse design of as-cast alloys. MATAI integrates a curated alloy database, deep neural network-based property predictors, a constraint-aware optimization engine, and an iterative AI-experiment feedback loop. The framework estimates key mechanical propertie, sincluding density, yield strength, ultimate tensile strength, and elongation, directly from composition, using multi-task learning and physics-informed inductive biases. Alloy design is framed as a constrained optimization problem and solved using a bi-level approach that combines local search with symbolic constraint programming. We demonstrate MATAI's capabilities on the Ti-based alloy system, a canonical class of lightweight structural materials, where it rapidly identifies candidates that simultaneously achieve lower density (<4.45 g/cm3), higher strength (>1000 MPa) and appreciable ductility (>5%) through only seven iterations. Experimental validation confirms that MATAI-designed alloys outperform commercial references such as TC4, highlighting the framework's potential to accelerate the discovery of lightweight, high-performance materials under real-world design constraints.
Let's Revise Step-by-Step: A Unified Local Search Framework for Code Generation with LLMs
Aug 10, 2025Large Language Models (LLMs) with inference-time scaling techniques show promise for code generation, yet face notable efficiency and scalability challenges. Construction-based tree-search methods suffer from rapid growth in tree size, high token consumption, and lack of anytime property. In contrast, improvement-based methods offer better performance but often struggle with uninformative reward signals and inefficient search strategies. In this work, we propose \textbf{ReLoc}, a unified local search framework which effectively performs step-by-step code revision. Specifically, ReLoc explores a series of local revisions through four key algorithmic components: initial code drafting, neighborhood code generation, candidate evaluation, and incumbent code updating, each of which can be instantiated with specific decision rules to realize different local search algorithms such as Hill Climbing (HC) or Genetic Algorithm (GA). Furthermore, we develop a specialized revision reward model that evaluates code quality based on revision distance to produce fine-grained preferences that guide the local search toward more promising candidates. Finally, our extensive experimental results demonstrate that our approach achieves superior performance across diverse code generation tasks, significantly outperforming both construction-based tree search as well as the state-of-the-art improvement-based code generation methods.
C-Adapter: Adapting Deep Classifiers for Efficient Conformal Prediction Sets
Oct 12, 2024Conformal prediction, as an emerging uncertainty quantification technique, typically functions as post-hoc processing for the outputs of trained classifiers. To optimize the classifier for maximum predictive efficiency, Conformal Training rectifies the training objective with a regularization that minimizes the average prediction set size at a specific error rate. However, the regularization term inevitably deteriorates the classification accuracy and leads to suboptimal efficiency of conformal predictors. To address this issue, we introduce \textbf{Conformal Adapter} (C-Adapter), an adapter-based tuning method to enhance the efficiency of conformal predictors without sacrificing accuracy. In particular, we implement the adapter as a class of intra order-preserving functions and tune it with our proposed loss that maximizes the discriminability of non-conformity scores between correctly and randomly matched data-label pairs. Using C-Adapter, the model tends to produce extremely high non-conformity scores for incorrect labels, thereby enhancing the efficiency of prediction sets across different coverage rates. Extensive experiments demonstrate that C-Adapter can effectively adapt various classifiers for efficient prediction sets, as well as enhance the conformal training method.
IPEval: A Bilingual Intellectual Property Agency Consultation Evaluation Benchmark for Large Language Models
Jun 18, 2024
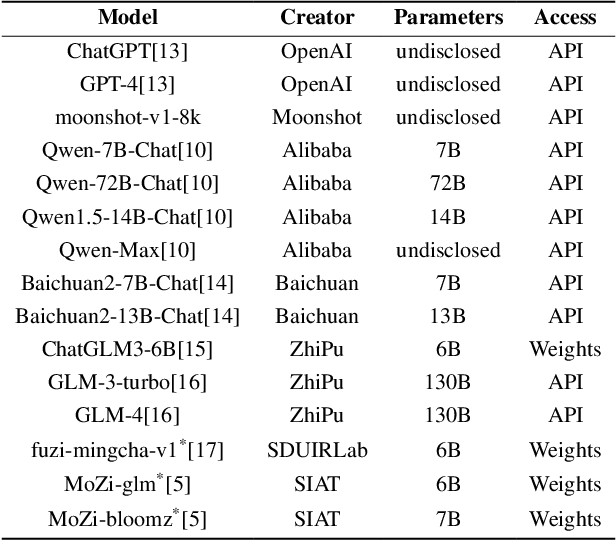
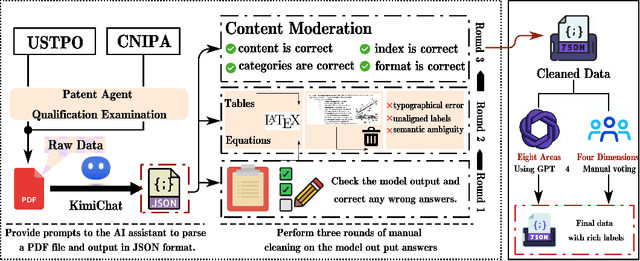
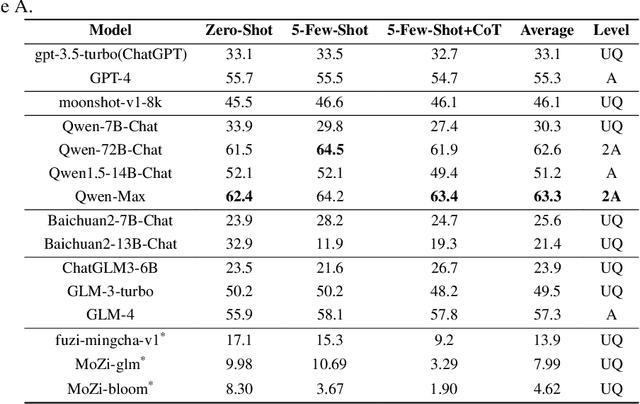
The rapid development of Large Language Models (LLMs) in vertical domains, including intellectual property (IP), lacks a specific evaluation benchmark for assessing their understanding, application, and reasoning abilities. To fill this gap, we introduce IPEval, the first evaluation benchmark tailored for IP agency and consulting tasks. IPEval comprises 2657 multiple-choice questions across four major dimensions: creation, application, protection, and management of IP. These questions span patent rights (inventions, utility models, designs), trademarks, copyrights, trade secrets, and other related laws. Evaluation methods include zero-shot, 5-few-shot, and Chain of Thought (CoT) for seven LLM types, predominantly in English or Chinese. Results show superior English performance by models like GPT series and Qwen series, while Chinese-centric LLMs excel in Chinese tests, albeit specialized IP LLMs lag behind general-purpose ones. Regional and temporal aspects of IP underscore the need for LLMs to grasp legal nuances and evolving laws. IPEval aims to accurately gauge LLM capabilities in IP and spur development of specialized models. Website: \url{https://ipeval.github.io/}
Similarity-Navigated Conformal Prediction for Graph Neural Networks
May 23, 2024



Graph Neural Networks have achieved remarkable accuracy in semi-supervised node classification tasks. However, these results lack reliable uncertainty estimates. Conformal prediction methods provide a theoretical guarantee for node classification tasks, ensuring that the conformal prediction set contains the ground-truth label with a desired probability (e.g., 95%). In this paper, we empirically show that for each node, aggregating the non-conformity scores of nodes with the same label can improve the efficiency of conformal prediction sets. This observation motivates us to propose a novel algorithm named Similarity-Navigated Adaptive Prediction Sets (SNAPS), which aggregates the non-conformity scores based on feature similarity and structural neighborhood. The key idea behind SNAPS is that nodes with high feature similarity or direct connections tend to have the same label. By incorporating adaptive similar nodes information, SNAPS can generate compact prediction sets and increase the singleton hit ratio (correct prediction sets of size one). Moreover, we theoretically provide a finite-sample coverage guarantee of SNAPS. Extensive experiments demonstrate the superiority of SNAPS, improving the efficiency of prediction sets and singleton hit ratio while maintaining valid coverage.
TorchCP: A Library for Conformal Prediction based on PyTorch
Feb 20, 2024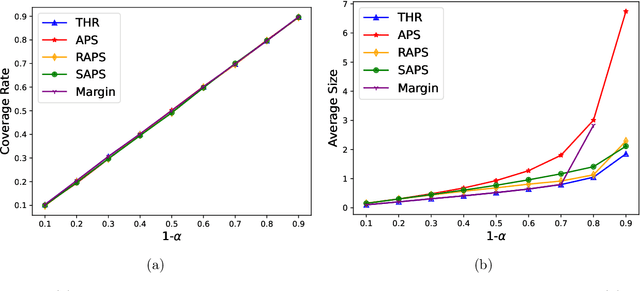
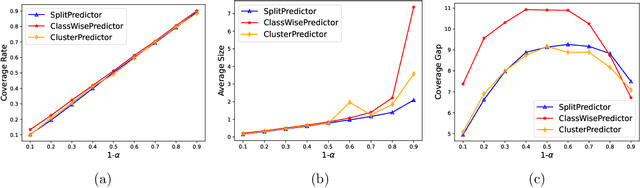
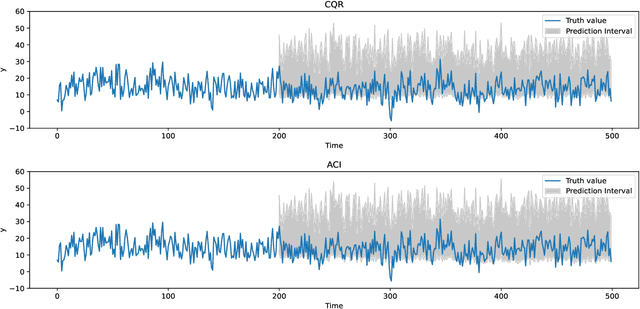
TorchCP is a Python toolbox for conformal prediction research on deep learning models. It contains various implementations for posthoc and training methods for classification and regression tasks (including multi-dimension output). TorchCP is built on PyTorch (Paszke et al., 2019) and leverages the advantages of matrix computation to provide concise and efficient inference implementations. The code is licensed under the LGPL license and is open-sourced at $\href{https://github.com/ml-stat-Sustech/TorchCP}{\text{this https URL}}$.