 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalize Then Propagate: Efficient Homophilous Regularization for Few-shot Semi-Supervised Node Classification
Jan 15, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable ability in semi-supervised node classification. However, most existing GNNs rely heavily on a large amount of labeled data for training, which is labor-intensive and requires extensive domain knowledge. In this paper, we first analyze the restrictions of GNNs generalization from the perspective of supervision signals in the context of few-shot semi-supervised node classification. To address these challenges, we propose a novel algorithm named NormProp, which utilizes the homophily assumption of unlabeled nodes to generate additional supervision signals, thereby enhancing the generalization against label scarcity. The key idea is to efficiently capture both the class information and the consistency of aggregation during message passing, via decoupling the direction and Euclidean norm of node representations. Moreover, we conduct a theoretical analysis to determine the upper bound of Euclidean norm, and then propose homophilous regularization to constraint the consistency of unlabeled nodes. Extensive experiments demonstrate that NormProp achieve state-of-the-art performance under low-label rate scenarios with low computational complexity.
GaGSL: Global-augmented Graph Structure Learning via Graph Information Bottleneck
Nov 07, 2024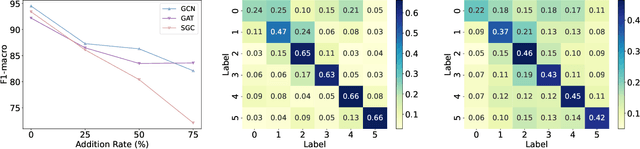
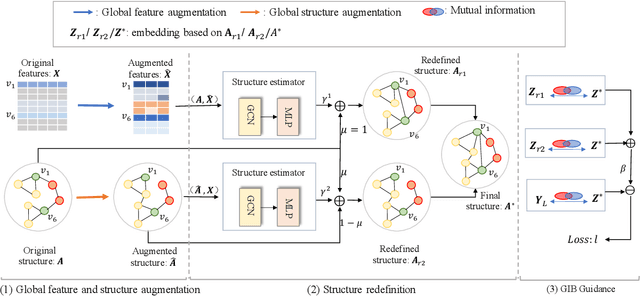
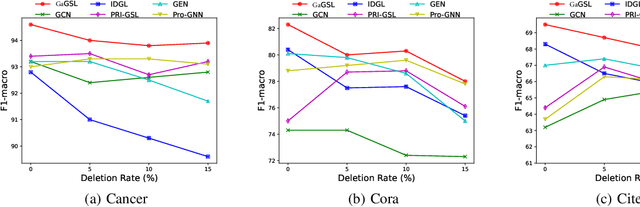
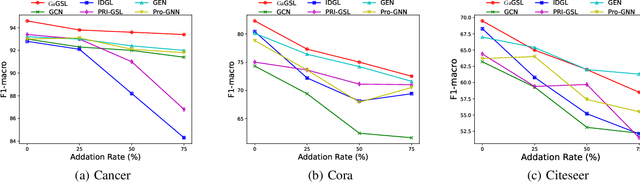
Graph neural networks (GNNs) are prominent for their effectiveness in processing graph data for semi-supervised node classification tasks. Most works of GNNs assume that the observed structure accurately represents the underlying node relationships. However, the graph structure is inevitably noisy or incomplete in reality, which can degrade the quality of graph representations. Therefore, it is imperative to learn a clean graph structure that balances performance and robustness. In this paper, we propose a novel method named \textit{Global-augmented Graph Structure Learning} (GaGSL), guided by the Graph Information Bottleneck (GIB) principle. The key idea behind GaGSL is to learn a compact and informative graph structure for node classification tasks. Specifically, to mitigate the bias caused by relying solely on the original structure, we first obtain augmented features and augmented structure through global feature augmentation and global structure augmentation. We then input the augmented features and augmented structure into a structure estimator with different parameters for optimization and re-definition of the graph structure, respectively. The redefined structures are combined to form the final graph structure. Finally, we employ GIB based on mutual information to guide the optimization of the graph structure to obtain the minimum sufficient graph structure. Comprehensive evaluations across a range of datasets reveal the outstanding performance and robustness of GaGSL compared with the state-of-the-art methods.
Graph Neural Networks with Coarse- and Fine-Grained Division for Mitigating Label Sparsity and Noise
Nov 06, 2024Graph Neural Networks (GNNs) have gained considerable prominence in semi-supervised learning tasks in processing graph-structured data, primarily owing to their message-passing mechanism, which largely relies on the availability of clean labels. However, in real-world scenarios, labels on nodes of graphs are inevitably noisy and sparsely labeled, significantly degrading the performance of GNNs. Exploring robust GNNs for semi-supervised node classification in the presence of noisy and sparse labels remains a critical challenge. Therefore, we propose a novel \textbf{G}raph \textbf{N}eural \textbf{N}etwork with \textbf{C}oarse- and \textbf{F}ine-\textbf{G}rained \textbf{D}ivision for mitigating label sparsity and noise, namely GNN-CFGD. The key idea of GNN-CFGD is reducing the negative impact of noisy labels via coarse- and fine-grained division, along with graph reconstruction. Specifically, we first investigate the effectiveness of linking unlabeled nodes to cleanly labeled nodes, demonstrating that this approach is more effective in combating labeling noise than linking to potentially noisy labeled nodes. Based on this observation, we introduce a Gaussian Mixture Model (GMM) based on the memory effect to perform a coarse-grained division of the given labels into clean and noisy labels. Next, we propose a clean labels oriented link that connects unlabeled nodes to cleanly labeled nodes, aimed at mitigating label sparsity and promoting supervision propagation. Furthermore, to provide refined supervision for noisy labeled nodes and additional supervision for unlabeled nodes, we fine-grain the noisy labeled and unlabeled nodes into two candidate sets based on confidence, respectively. Extensive experiments on various datasets demonstrate the superior effectiveness and robustness of GNN-CFGD.
Similarity-Navigated Conformal Prediction for Graph Neural Networks
May 23, 2024



Graph Neural Networks have achieved remarkable accuracy in semi-supervised node classification tasks. However, these results lack reliable uncertainty estimates. Conformal prediction methods provide a theoretical guarantee for node classification tasks, ensuring that the conformal prediction set contains the ground-truth label with a desired probability (e.g., 95%). In this paper, we empirically show that for each node, aggregating the non-conformity scores of nodes with the same label can improve the efficiency of conformal prediction sets. This observation motivates us to propose a novel algorithm named Similarity-Navigated Adaptive Prediction Sets (SNAPS), which aggregates the non-conformity scores based on feature similarity and structural neighborhood. The key idea behind SNAPS is that nodes with high feature similarity or direct connections tend to have the same label. By incorporating adaptive similar nodes information, SNAPS can generate compact prediction sets and increase the singleton hit ratio (correct prediction sets of size one). Moreover, we theoretically provide a finite-sample coverage guarantee of SNAPS. Extensive experiments demonstrate the superiority of SNAPS, improving the efficiency of prediction sets and singleton hit ratio while maintaining valid coverage.