 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable reinforcement learning from human feedback to improve alignment
Dec 15, 2025
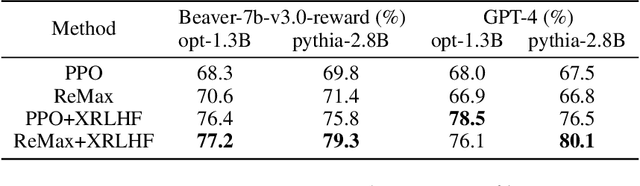

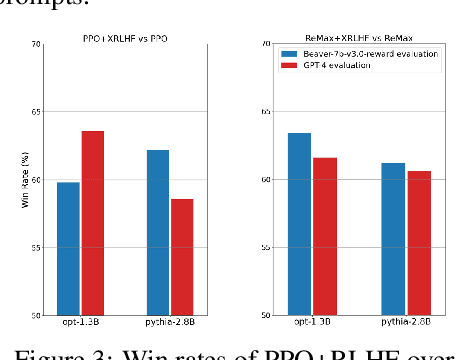
A common and effective strategy for humans to improve an unsatisfactory outcome in daily life is to find a cause of this outcome and correct the cause. In this paper, we investigate whether this human improvement strategy can be applied to improving reinforcement learning from human feedback (RLHF) for alignment of language models (LMs). In particular, it is observed in the literature that LMs tuned by RLHF can still output unsatisfactory responses. This paper proposes a method to improve the unsatisfactory responses by correcting their causes. Our method has two parts. The first part proposes a post-hoc explanation method to explain why an unsatisfactory response is generated to a prompt by identifying the training data that lead to this response. We formulate this problem as a constrained combinatorial optimization problem where the objective is to find a set of training data closest to this prompt-response pair in a feature representation space, and the constraint is that the prompt-response pair can be decomposed as a convex combination of this set of training data in the feature space. We propose an efficient iterative data selection algorithm to solve this problem. The second part proposes an unlearning method that improves unsatisfactory responses to some prompts by unlearning the training data that lead to these unsatisfactory responses and, meanwhile, does not significantly degrade satisfactory responses to other prompts. Experimental results demonstrate that our algorithm can improve RLHF.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

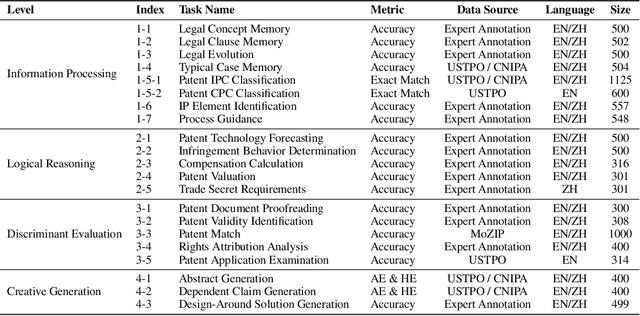
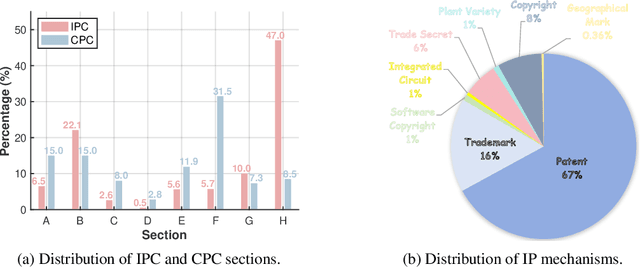
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
In-Trajectory Inverse Reinforcement Learning: Learn Incrementally From An Ongoing Trajectory
Oct 21, 2024Inverse reinforcement learning (IRL) aims to learn a reward function and a corresponding policy that best fit the demonstrated trajectories of an expert. However, current IRL works cannot learn incrementally from an ongoing trajectory because they have to wait to collect at least one complete trajectory to learn. To bridge the gap, this paper considers the problem of learning a reward function and a corresponding policy while observing the initial state-action pair of an ongoing trajectory and keeping updating the learned reward and policy when new state-action pairs of the ongoing trajectory are observed. We formulate this problem as an online bi-level optimization problem where the upper level dynamically adjusts the learned reward according to the newly observed state-action pairs with the help of a meta-regularization term, and the lower level learns the corresponding policy. We propose a novel algorithm to solve this problem and guarantee that the algorithm achieves sub-linear local regret $O(\sqrt{T}+\log T+\sqrt{T}\log T)$. If the reward function is linear, we prove that the proposed algorithm achieves sub-linear regret $O(\log T)$. Experiments are used to validate the proposed algorithm.
Meta-Reinforcement Learning with Universal Policy Adaptation: Provable Near-Optimality under All-task Optimum Comparator
Oct 13, 2024Meta-reinforcement learning (Meta-RL) has attracted attention due to its capability to enhance reinforcement learning (RL) algorithms, in terms of data efficiency and generalizability. In this paper, we develop a bilevel optimization framework for meta-RL (BO-MRL) to learn the meta-prior for task-specific policy adaptation, which implements multiple-step policy optimization on one-time data collection. Beyond existing meta-RL analyses, we provide upper bounds of the expected optimality gap over the task distribution. This metric measures the distance of the policy adaptation from the learned meta-prior to the task-specific optimum, and quantifies the model's generalizability to the task distribution. We empirically validate the correctness of the derived upper bounds and demonstrate the superior effectiveness of the proposed algorithm over benchmarks.
Federated reinforcement learning for robot motion planning with zero-shot generalization
Mar 20, 2024This paper considers the problem of learning a control policy for robot motion planning with zero-shot generalization, i.e., no data collection and policy adaptation is needed when the learned policy is deployed in new environments. We develop a federated reinforcement learning framework that enables collaborative learning of multiple learners and a central server, i.e., the Cloud, without sharing their raw data. In each iteration, each learner uploads its local control policy and the corresponding estimated normalized arrival time to the Cloud, which then computes the global optimum among the learners and broadcasts the optimal policy to the learners. Each learner then selects between its local control policy and that from the Cloud for next iteration. The proposed framework leverages on the derived zero-shot generalization guarantees on arrival time and safety. Theoretical guarantees on almost-sure convergence, almost consensus, Pareto improvement and optimality gap are also provided. Monte Carlo simulation is conducted to evaluate the proposed framework.
iPolicy: Incremental Policy Algorithms for Feedback Motion Planning
Jan 05, 2024This paper presents policy-based motion planning for robotic systems. The motion planning literature has been mostly focused on open-loop trajectory planning which is followed by tracking online. In contrast, we solve the problem of path planning and controller synthesis simultaneously by solving the related feedback control problem. We present a novel incremental policy (iPolicy) algorithm for motion planning, which integrates sampling-based methods and set-valued optimal control methods to compute feedback controllers for the robotic system. In particular, we use sampling to incrementally construct the state space of the system. Asynchronous value iterations are performed on the sampled state space to synthesize the incremental policy feedback controller. We show the convergence of the estimates to the optimal value function in continuous state space. Numerical results with various different dynamical systems (including nonholonomic systems) verify the optimality and effectiveness of iPolicy.
Learning Evacuee Models from Robot-Guided Emergency Evacuation Experiments
Jun 30, 2023Recent research has examined the possibility of using robots to guide evacuees to safe exits during emergencies. Yet, there are many factors that can impact a person's decision to follow a robot. Being able to model how an evacuee follows an emergency robot guide could be crucial for designing robots that effectively guide evacuees during an emergency. This paper presents a method for developing realistic and predictive human evacuee models from physical human evacuation experiments. The paper analyzes the behavior of 14 human subjects during physical robot-guided evacuation. We then use the video data to create evacuee motion models that predict the person's future positions during the emergency. Finally, we validate the resulting models by running a k-fold cross-validation on the data collected during physical human subject experiments. We also present performance results of the model using data from a similar simulated emergency evacuation experiment demonstrating that these models can serve as a tool to predict evacuee behavior in novel evacuation simulations.
Multi-Robot-Guided Crowd Evacuation: Two-Scale Modeling and Control Based on Mean-Field Hydrodynamic Models
Feb 28, 2023Emergency evacuation describes a complex situation involving time-critical decision-making by evacuees. Mobile robots are being actively explored as a potential solution to provide timely guidance. In this work, we study a robot-guided crowd evacuation problem where a small group of robots is used to guide a large human crowd to safe locations. The challenge lies in how to utilize micro-level human-robot interactions to indirectly influence a population that significantly outnumbers the robots to achieve the collective evacuation objective. To address the challenge, we follow a two-scale modeling strategy and explore mean-field hydrodynamic models which consist of a family of microscopic social-force models that explicitly describe how human movements are locally affected by other humans, the environment, and the robots, and associated macroscopic equations for the temporal and spatial evolution of the crowd density and flow velocity. We design controllers for the robots such that they not only automatically explore the environment (with unknown dynamic obstacles) to cover it as much as possible but also dynamically adjust the directions of their local navigation force fields based on the real-time macro-states of the crowd to guide the crowd to a safe location. We prove the stability of the proposed evacuation algorithm and conduct a series of simulations (involving unknown dynamic obstacles) to validate the performance of the algorithm.
Efficient Gradient Approximation Method for Constrained Bilevel Optimization
Feb 03, 2023



Bilevel optimization has been developed for many machine learning tasks with large-scale and high-dimensional data. This paper considers a constrained bilevel optimization problem, where the lower-level optimization problem is convex with equality and inequality constraints and the upper-level optimization problem is non-convex. The overall objective function is non-convex and non-differentiable. To solve the problem, we develop a gradient-based approach, called gradient approximation method, which determines the descent direction by computing several representative gradients of the objective function inside a neighborhood of the current estimate. We show that the algorithm asymptotically converges to the set of Clarke stationary points, and demonstrate the efficacy of the algorithm by the experiments on hyperparameter optimization and meta-learning.
Multi-Robot-Assisted Human Crowd Evacuation using Navigation Velocity Fields
Sep 20, 2022
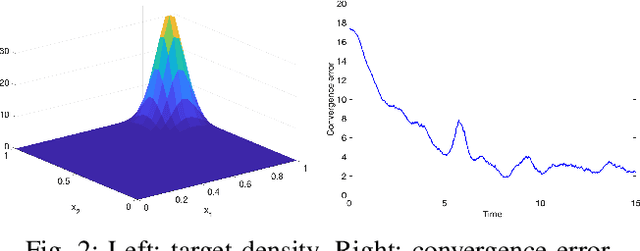
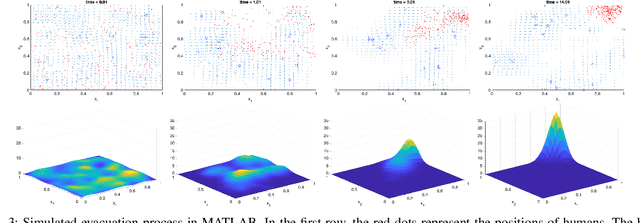
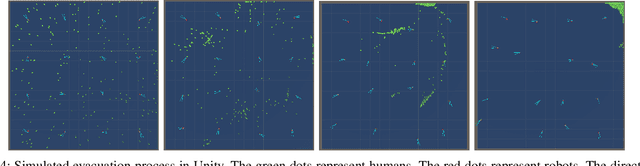
This work studies a robot-assisted crowd evacuation problem where we control a small group of robots to guide a large human crowd to safe locations. The challenge lies in how to model human-robot interactions and design robot controls to indirectly control a human population that significantly outnumbers the robots. To address the challenge, we treat the crowd as a continuum and formulate the evacuation objective as driving the crowd density to target locations. We propose a novel mean-field model which consists of a family of microscopic equations that explicitly model how human motions are locally guided by the robots and an associated macroscopic equation that describes how the crowd density is controlled by the navigation velocity fields generated by all robots. Then, we design density feedback controllers for the robots to dynamically adjust their states such that the generated navigation velocity fields drive the crowd density to a target density. Stability guarantees of the proposed controllers are proven. Agent-based simulations are included to evaluate the proposed evacuation algorithms.