 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-LN Bench: Towards Long-horizon Goal-oriented Navigation with Active Dialogs
Dec 31, 2025In most existing embodied navigation tasks, instructions are well-defined and unambiguous, such as instruction following and object searching. Under this idealized setting, agents are required solely to produce effective navigation outputs conditioned on vision and language inputs. However, real-world navigation instructions are often vague and ambiguous, requiring the agent to resolve uncertainty and infer user intent through active dialog. To address this gap, we propose Interactive Instance Object Navigation (IION), a task that requires agents not only to generate navigation actions but also to produce language outputs via active dialog, thereby aligning more closely with practical settings. IION extends Instance Object Navigation (ION) by allowing agents to freely consult an oracle in natural language while navigating. Building on this task, we present the Vision Language-Language Navigation (VL-LN) benchmark, which provides a large-scale, automatically generated dataset and a comprehensive evaluation protocol for training and assessing dialog-enabled navigation models. VL-LN comprises over 41k long-horizon dialog-augmented trajectories for training and an automatic evaluation protocol with an oracle capable of responding to agent queries. Using this benchmark, we train a navigation model equipped with dialog capabilities and show that it achieves significant improvements over the baselines. Extensive experiments and analyses further demonstrate the effectiveness and reliability of VL-LN for advancing research on dialog-enabled embodied navigation. Code and dataset: https://0309hws.github.io/VL-LN.github.io/
DP-CSGP: Differentially Private Stochastic Gradient Push with Compressed Communication
Dec 15, 2025In this paper, we propose a Differentially Private Stochastic Gradient Push with Compressed communication (termed DP-CSGP) for decentralized learning over directed graphs. Different from existing works, the proposed algorithm is designed to maintain high model utility while ensuring both rigorous differential privacy (DP) guarantees and efficient communication. For general non-convex and smooth objective functions, we show that the proposed algorithm achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}δ \right)}/(\sqrt{n}Jε) \right)$ ($J$ and $d$ are the number of local samples and the dimension of decision variables, respectively) with $\left(ε, δ\right)$-DP guarantee for each node, matching that of decentralized counterparts with exact communication. Extensive experiments on benchmark tasks show that, under the same privacy budget, DP-CSGP achieves comparable model accuracy with significantly lower communication cost than existing decentralized counterparts with exact communication.
CoCoL: A Communication Efficient Decentralized Collaborative Method for Multi-Robot Systems
Aug 28, 2025



Collaborative learning enhances the performance and adaptability of multi-robot systems in complex tasks but faces significant challenges due to high communication overhead and data heterogeneity inherent in multi-robot tasks. To this end, we propose CoCoL, a Communication efficient decentralized Collaborative Learning method tailored for multi-robot systems with heterogeneous local datasets. Leveraging a mirror descent framework, CoCoL achieves remarkable communication efficiency with approximate Newton-type updates by capturing the similarity between objective functions of robots, and reduces computational costs through inexact sub-problem solutions. Furthermore, the integration of a gradient tracking scheme ensures its robustness against data heterogeneity. Experimental results on three representative multi robot collaborative learning tasks show the superiority of the proposed CoCoL in significantly reducing both the number of communication rounds and total bandwidth consumption while maintaining state-of-the-art accuracy. These benefits are particularly evident in challenging scenarios involving non-IID (non-independent and identically distributed) data distribution, streaming data, and time-varying network topologies.
Dyn-D$^2$P: Dynamic Differentially Private Decentralized Learning with Provable Utility Guarantee
May 10, 2025Most existing decentralized learning methods with differential privacy (DP) guarantee rely on constant gradient clipping bounds and fixed-level DP Gaussian noises for each node throughout the training process, leading to a significant accuracy degradation compared to non-private counterparts. In this paper, we propose a new Dynamic Differentially Private Decentralized learning approach (termed Dyn-D$^2$P) tailored for general time-varying directed networks. Leveraging the Gaussian DP (GDP) framework for privacy accounting, Dyn-D$^2$P dynamically adjusts gradient clipping bounds and noise levels based on gradient convergence. This proposed dynamic noise strategy enables us to enhance model accuracy while preserving the total privacy budget. Extensive experiments on benchmark datasets demonstrate the superiority of Dyn-D$^2$P over its counterparts employing fixed-level noises, especially under strong privacy guarantees. Furthermore, we provide a provable utility bound for Dyn-D$^2$P that establishes an explicit dependency on network-related parameters, with a scaling factor of $1/\sqrt{n}$ in terms of the number of nodes $n$ up to a bias error term induced by gradient clipping. To our knowledge, this is the first model utility analysis for differentially private decentralized non-convex optimization with dynamic gradient clipping bounds and noise levels.
On Random Sampling of Diffused Graph Signals with Sparse Inputs on Vertex Domain
Dec 28, 2024



The sampling of graph signals has recently drawn much attention due to the wide applications of graph signal processing. While a lot of efficient methods and interesting results have been reported to the sampling of band-limited or smooth graph signals, few research has been devoted to non-smooth graph signals, especially to sparse graph signals, which are also of importance in many practical applications. This paper addresses the random sampling of non-smooth graph signals generated by diffusion of sparse inputs. We aim to present a solid theoretical analysis on the random sampling of diffused sparse graph signals, which can be parallel to that of band-limited graph signals, and thus present a sufficient condition to the number of samples ensuring the unique recovery for uniform random sampling. Then, we focus on two classes of widely used binary graph models, and give explicit and tighter estimations on the sampling numbers ensuring unique recovery. We also propose an adaptive variable-density sampling strategy to provide a better performance than uniform random sampling. Finally, simulation experiments are presented to validate the effectiveness of the theoretical results.
Multi-robot autonomous 3D reconstruction using Gaussian splatting with Semantic guidance
Dec 03, 2024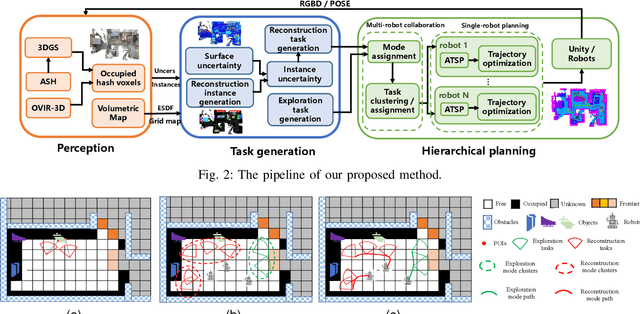
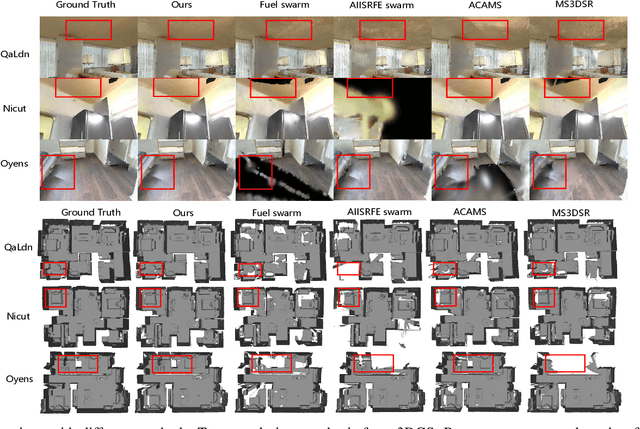

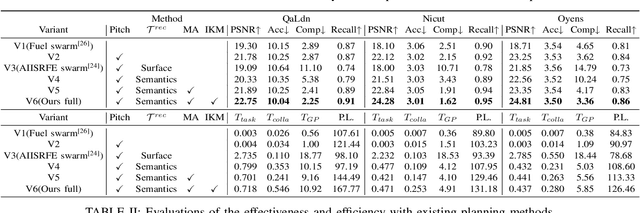
Implicit neural representations and 3D Gaussian splatting (3DGS) have shown great potential for scene reconstruction. Recent studies have expanded their applications in autonomous reconstruction through task assignment methods. However, these methods are mainly limited to single robot, and rapid reconstruction of large-scale scenes remains challenging. Additionally, task-driven planning based on surface uncertainty is prone to being trapped in local optima. To this end, we propose the first 3DGS-based centralized multi-robot autonomous 3D reconstruction framework. To further reduce time cost of task generation and improve reconstruction quality, we integrate online open-vocabulary semantic segmentation with surface uncertainty of 3DGS, focusing view sampling on regions with high instance uncertainty. Finally, we develop a multi-robot collaboration strategy with mode and task assignments improving reconstruction quality while ensuring planning efficiency. Our method demonstrates the highest reconstruction quality among all planning methods and superior planning efficiency compared to existing multi-robot methods. We deploy our method on multiple robots, and results show that it can effectively plan view paths and reconstruct scenes with high quality.
Achieving Near-Optimal Convergence for Distributed Minimax Optimization with Adaptive Stepsizes
Jun 05, 2024



In this paper, we show that applying adaptive methods directly to distributed minimax problems can result in non-convergence due to inconsistency in locally computed adaptive stepsizes. To address this challenge, we propose D-AdaST, a Distributed Adaptive minimax method with Stepsize Tracking. The key strategy is to employ an adaptive stepsize tracking protocol involving the transmission of two extra (scalar) variables. This protocol ensures the consistency among stepsizes of nodes, eliminating the steady-state error due to the lack of coordination of stepsizes among nodes that commonly exists in vanilla distributed adaptive methods, and thus guarantees exact convergence. For nonconvex-strongly-concave distributed minimax problems, we characterize the specific transient times that ensure time-scale separation of stepsizes and quasi-independence of networks, leading to a near-optimal convergence rate of $\tilde{\mathcal{O}} \left( \epsilon ^{-\left( 4+\delta \right)} \right)$ for any small $\delta > 0$, matching that of the centralized counterpart. To our best knowledge, D-AdaST is the first distributed adaptive method achieving near-optimal convergence without knowing any problem-dependent parameters for nonconvex minimax problems. Extensive experiments are conducted to validate our theoretical results.
PrivSGP-VR: Differentially Private Variance-Reduced Stochastic Gradient Push with Tight Utility Bounds
May 04, 2024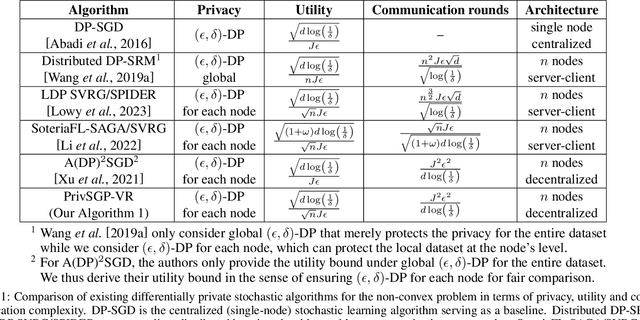
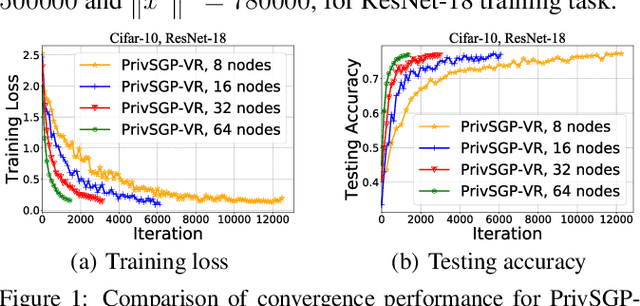
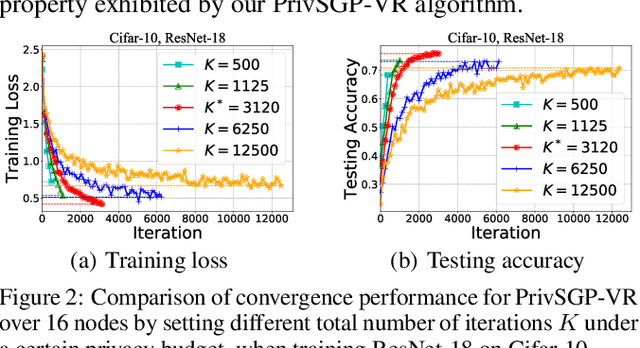
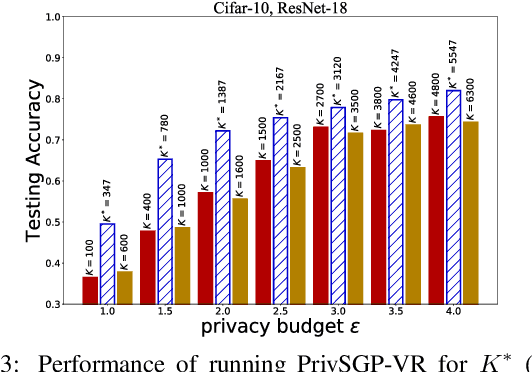
In this paper, we propose a differentially private decentralized learning method (termed PrivSGP-VR) which employs stochastic gradient push with variance reduction and guarantees $(\epsilon, \delta)$-differential privacy (DP) for each node. Our theoretical analysis shows that, under DP Gaussian noise with constant variance, PrivSGP-VR achieves a sub-linear convergence rate of $\mathcal{O}(1/\sqrt{nK})$, where $n$ and $K$ are the number of nodes and iterations, respectively, which is independent of stochastic gradient variance, and achieves a linear speedup with respect to $n$. Leveraging the moments accountant method, we further derive an optimal $K$ to maximize the model utility under certain privacy budget in decentralized settings. With this optimized $K$, PrivSGP-VR achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}{\delta} \right)}/(\sqrt{n}J\epsilon) \right)$, where $J$ and $d$ are the number of local samples and the dimension of decision variable, respectively, which matches that of the server-client distributed counterparts, and exhibits an extra factor of $1/\sqrt{n}$ improvement compared to that of the existing decentralized counterparts, such as A(DP)$^2$SGD. Extensive experiments corroborate our theoretical findings, especially in terms of the maximized utility with optimized $K$, in fully decentralized settings.
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Apr 19, 2024



The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
Safe Hybrid-Action Reinforcement Learning-Based Decision and Control for Discretionary Lane Change
Mar 01, 2024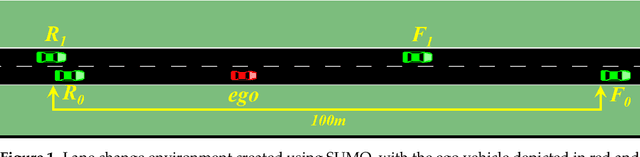
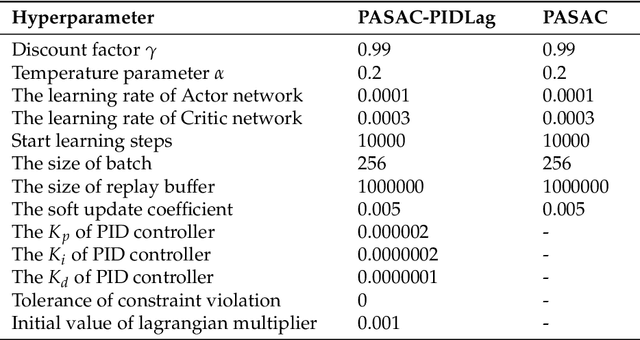
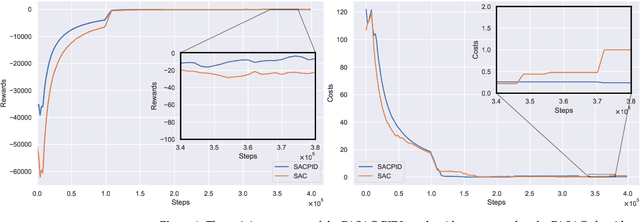
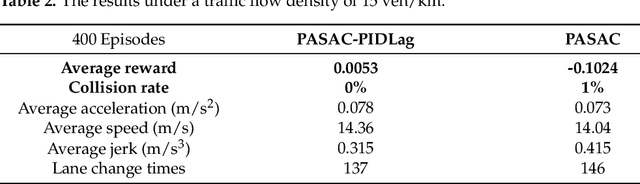
Autonomous lane-change, a key feature of advanced driver-assistance systems, can enhance traffic efficiency and reduce the incidence of accidents. However, safe driving of autonomous vehicles remains challenging in complex environments. How to perform safe and appropriate lane change is a popular topic of research in the field of autonomous driving. Currently, few papers consider the safety of reinforcement learning in autonomous lane-change scenarios. We introduce safe hybrid-action reinforcement learning into discretionary lane change for the first time and propose Parameterized Soft Actor-Critic with PID Lagrangian (PASAC-PIDLag) algorithm. Furthermore, we conduct a comparative analysis of the Parameterized Soft Actor-Critic (PASAC), which is an unsafe version of PASAC-PIDLag. Both algorithms are employed to train the lane-change strategy of autonomous vehicles to output discrete lane-change decision and longitudinal vehicle acceleration. Our simulation results indicate that at a traffic density of 15 vehicles per kilometer (15 veh/km), the PASAC-PIDLag algorithm exhibits superior safety with a collision rate of 0%, outperforming the PASAC algorithm, which has a collision rate of 1%. The outcomes of the generalization assessments reveal that at low traffic density levels, both the PASAC-PIDLag and PASAC algorithms are proficient in attaining a 0% collision rate. Under conditions of high traffic flow density, the PASAC-PIDLag algorithm surpasses PASAC in terms of both safety and optimality.