 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-LN Bench: Towards Long-horizon Goal-oriented Navigation with Active Dialogs
Dec 31, 2025In most existing embodied navigation tasks, instructions are well-defined and unambiguous, such as instruction following and object searching. Under this idealized setting, agents are required solely to produce effective navigation outputs conditioned on vision and language inputs. However, real-world navigation instructions are often vague and ambiguous, requiring the agent to resolve uncertainty and infer user intent through active dialog. To address this gap, we propose Interactive Instance Object Navigation (IION), a task that requires agents not only to generate navigation actions but also to produce language outputs via active dialog, thereby aligning more closely with practical settings. IION extends Instance Object Navigation (ION) by allowing agents to freely consult an oracle in natural language while navigating. Building on this task, we present the Vision Language-Language Navigation (VL-LN) benchmark, which provides a large-scale, automatically generated dataset and a comprehensive evaluation protocol for training and assessing dialog-enabled navigation models. VL-LN comprises over 41k long-horizon dialog-augmented trajectories for training and an automatic evaluation protocol with an oracle capable of responding to agent queries. Using this benchmark, we train a navigation model equipped with dialog capabilities and show that it achieves significant improvements over the baselines. Extensive experiments and analyses further demonstrate the effectiveness and reliability of VL-LN for advancing research on dialog-enabled embodied navigation. Code and dataset: https://0309hws.github.io/VL-LN.github.io/
MMSI-Video-Bench: A Holistic Benchmark for Video-Based Spatial Intelligence
Dec 11, 2025Spatial understanding over continuous visual input is crucial for MLLMs to evolve into general-purpose assistants in physical environments. Yet there is still no comprehensive benchmark that holistically assesses the progress toward this goal. In this work, we introduce MMSI-Video-Bench, a fully human-annotated benchmark for video-based spatial intelligence in MLLMs. It operationalizes a four-level framework, Perception, Planning, Prediction, and Cross-Video Reasoning, through 1,106 questions grounded in 1,278 clips from 25 datasets and in-house videos. Each item is carefully designed and reviewed by 3DV experts with explanatory rationales to ensure precise, unambiguous grounding. Leveraging its diverse data sources and holistic task coverage, MMSI-Video-Bench also supports three domain-oriented sub-benchmarks (Indoor Scene Perception Bench, Robot Bench and Grounding Bench) for targeted capability assessment. We evaluate 25 strong open-source and proprietary MLLMs, revealing a striking human--AI gap: many models perform near chance, and the best reasoning model lags humans by nearly 60%. We further find that spatially fine-tuned models still fail to generalize effectively on our benchmark. Fine-grained error analysis exposes systematic failures in geometric reasoning, motion grounding, long-horizon prediction, and cross-video correspondence. We also show that typical frame-sampling strategies transfer poorly to our reasoning-intensive benchmark, and that neither 3D spatial cues nor chain-of-thought prompting yields meaningful gains. We expect our benchmark to establish a solid testbed for advancing video-based spatial intelligence.
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Apr 19, 2024



The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Oct 04, 2022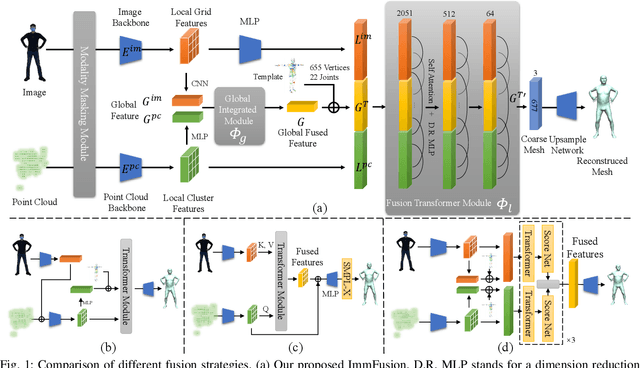
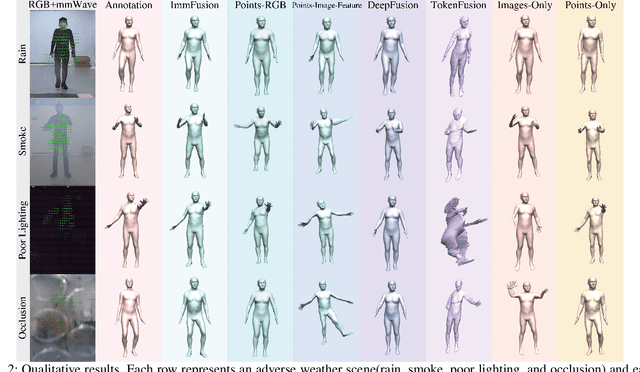

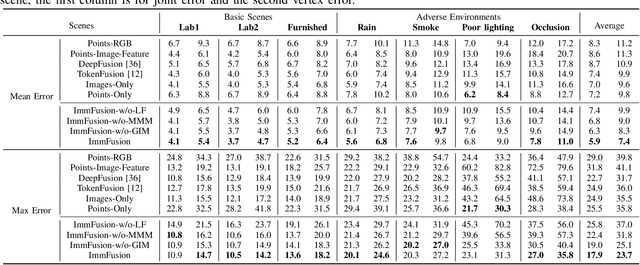
3D human reconstruction from RGB images achieves decent results in good weather conditions but degrades dramatically in rough weather. Complementary, mmWave radars have been employed to reconstruct 3D human joints and meshes in rough weather. However, combining RGB and mmWave signals for robust all-weather 3D human reconstruction is still an open challenge, given the sparse nature of mmWave and the vulnerability of RGB images. In this paper, we present ImmFusion, the first mmWave-RGB fusion solution to reconstruct 3D human bodies in all weather conditions robustly. Specifically, our ImmFusion consists of image and point backbones for token feature extraction and a Transformer module for token fusion. The image and point backbones refine global and local features from original data, and the Fusion Transformer Module aims for effective information fusion of two modalities by dynamically selecting informative tokens. Extensive experiments on a large-scale dataset, mmBody, captured in various environments demonstrate that ImmFusion can efficiently utilize the information of two modalities to achieve a robust 3D human body reconstruction in all weather conditions. In addition, our method's accuracy is significantly superior to that of state-of-the-art Transformer-based LiDAR-camera fusion methods.
mmBody Benchmark: 3D Body Reconstruction Dataset and Analysis for Millimeter Wave Radar
Sep 12, 2022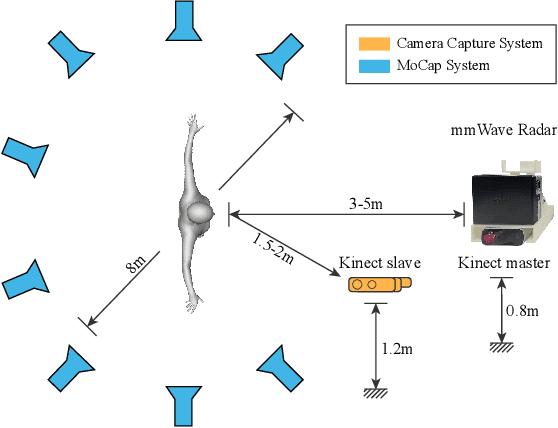
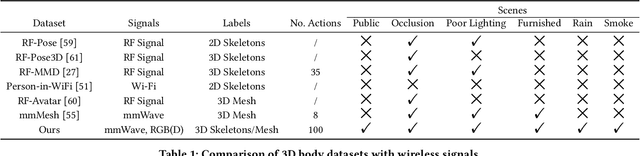
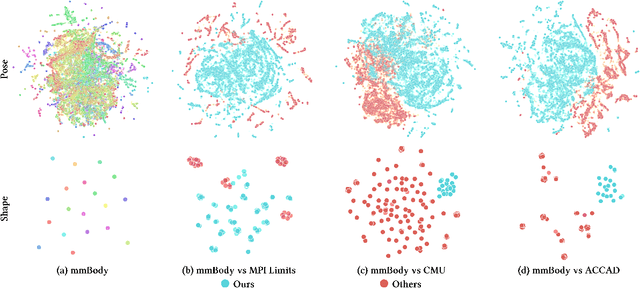

Millimeter Wave (mmWave) Radar is gaining popularity as it can work in adverse environments like smoke, rain, snow, poor lighting, etc. Prior work has explored the possibility of reconstructing 3D skeletons or meshes from the noisy and sparse mmWave Radar signals. However, it is unclear how accurately we can reconstruct the 3D body from the mmWave signals across scenes and how it performs compared with cameras, which are important aspects needed to be considered when either using mmWave radars alone or combining them with cameras. To answer these questions, an automatic 3D body annotation system is first designed and built up with multiple sensors to collect a large-scale dataset. The dataset consists of synchronized and calibrated mmWave radar point clouds and RGB(D) images in different scenes and skeleton/mesh annotations for humans in the scenes. With this dataset, we train state-of-the-art methods with inputs from different sensors and test them in various scenarios. The results demonstrate that 1) despite the noise and sparsity of the generated point clouds, the mmWave radar can achieve better reconstruction accuracy than the RGB camera but worse than the depth camera; 2) the reconstruction from the mmWave radar is affected by adverse weather conditions moderately while the RGB(D) camera is severely affected. Further, analysis of the dataset and the results shadow insights on improving the reconstruction from the mmWave radar and the combination of signals from different sensors.