 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning
Nov 14, 2025
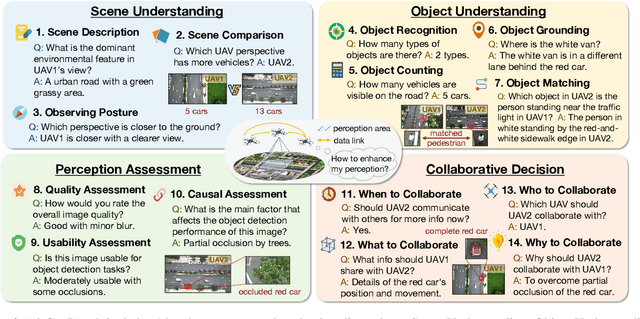
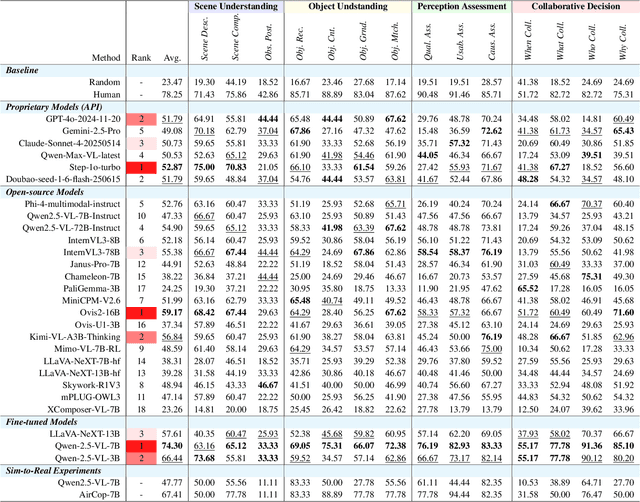
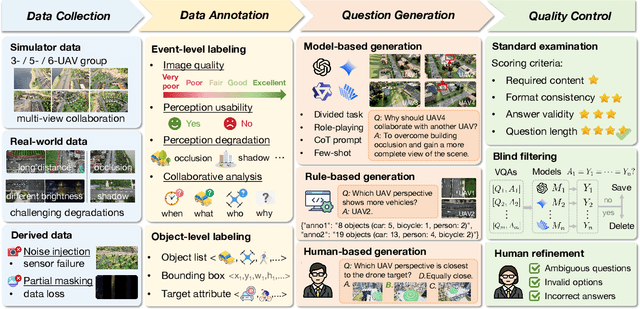
Multimodal Large Language Models (MLLMs) have shown promise in single-agent vision tasks, yet benchmarks for evaluating multi-agent collaborative perception remain scarce. This gap is critical, as multi-drone systems provide enhanced coverage, robustness, and collaboration compared to single-sensor setups. Existing multi-image benchmarks mainly target basic perception tasks using high-quality single-agent images, thus failing to evaluate MLLMs in more complex, egocentric collaborative scenarios, especially under real-world degraded perception conditions.To address these challenges, we introduce AirCopBench, the first comprehensive benchmark designed to evaluate MLLMs in embodied aerial collaborative perception under challenging perceptual conditions. AirCopBench includes 14.6k+ questions derived from both simulator and real-world data, spanning four key task dimensions: Scene Understanding, Object Understanding, Perception Assessment, and Collaborative Decision, across 14 task types. We construct the benchmark using data from challenging degraded-perception scenarios with annotated collaborative events, generating large-scale questions through model-, rule-, and human-based methods under rigorous quality control. Evaluations on 40 MLLMs show significant performance gaps in collaborative perception tasks, with the best model trailing humans by 24.38% on average and exhibiting inconsistent results across tasks. Fine-tuning experiments further confirm the feasibility of sim-to-real transfer in aerial collaborative perception and reasoning.
Psychology-driven LLM Agents for Explainable Panic Prediction on Social Media during Sudden Disaster Events
May 22, 2025During sudden disaster events, accurately predicting public panic sentiment on social media is crucial for proactive governance and crisis management. Current efforts on this problem face three main challenges: lack of finely annotated data hinders emotion prediction studies, unmodeled risk perception causes prediction inaccuracies, and insufficient interpretability of panic formation mechanisms. We address these issues by proposing a Psychology-driven generative Agent framework (PsychoAgent) for explainable panic prediction based on emotion arousal theory. Specifically, we first construct a fine-grained open panic emotion dataset (namely COPE) via human-large language models (LLMs) collaboration to mitigate semantic bias. Then, we develop a framework integrating cross-domain heterogeneous data grounded in psychological mechanisms to model risk perception and cognitive differences in emotion generation. To enhance interpretability, we design an LLM-based role-playing agent that simulates individual psychological chains through dedicatedly designed prompts. Experimental results on our annotated dataset show that PsychoAgent improves panic emotion prediction performance by 12.6% to 21.7% compared to baseline models. Furthermore, the explainability and generalization of our approach is validated. Crucially, this represents a paradigm shift from opaque "data-driven fitting" to transparent "role-based simulation with mechanistic interpretation" for panic emotion prediction during emergencies. Our implementation is publicly available at: https://anonymous.4open.science/r/PsychoAgent-19DD.
CityEQA: A Hierarchical LLM Agent on Embodied Question Answering Benchmark in City Space
Feb 20, 2025Embodied Question Answering (EQA) has primarily focused on indoor environments, leaving the complexities of urban settings - spanning environment, action, and perception - largely unexplored. To bridge this gap, we introduce CityEQA, a new task where an embodied agent answers open-vocabulary questions through active exploration in dynamic city spaces. To support this task, we present CityEQA-EC, the first benchmark dataset featuring 1,412 human-annotated tasks across six categories, grounded in a realistic 3D urban simulator. Moreover, we propose Planner-Manager-Actor (PMA), a novel agent tailored for CityEQA. PMA enables long-horizon planning and hierarchical task execution: the Planner breaks down the question answering into sub-tasks, the Manager maintains an object-centric cognitive map for spatial reasoning during the process control, and the specialized Actors handle navigation, exploration, and collection sub-tasks. Experiments demonstrate that PMA achieves 60.7% of human-level answering accuracy, significantly outperforming frontier-based baselines. While promising, the performance gap compared to humans highlights the need for enhanced visual reasoning in CityEQA. This work paves the way for future advancements in urban spatial intelligence. Dataset and code are available at https://github.com/BiluYong/CityEQA.git.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Effective Multimodal Reinforcement Learning with Modality Alignment and Importance Enhancement
Feb 18, 2023Many real-world applications require an agent to make robust and deliberate decisions with multimodal information (e.g., robots with multi-sensory inputs). However, it is very challenging to train the agent via reinforcement learning (RL) due to the heterogeneity and dynamic importance of different modalities. Specifically, we observe that these issues make conventional RL methods difficult to learn a useful state representation in the end-to-end training with multimodal information. To address this, we propose a novel multimodal RL approach that can do multimodal alignment and importance enhancement according to their similarity and importance in terms of RL tasks respectively. By doing so, we are able to learn an effective state representation and consequentially improve the RL training process. We test our approach on several multimodal RL domains, showing that it outperforms state-of-the-art methods in terms of learning speed and policy quality.
Towards Skilled Population Curriculum for Multi-Agent Reinforcement Learning
Feb 07, 2023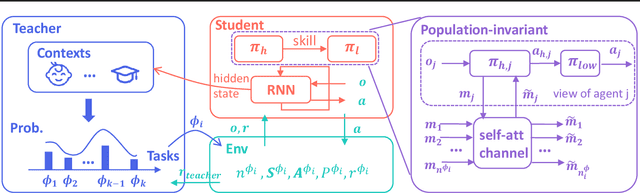


Recent advances in multi-agent reinforcement learning (MARL) allow agents to coordinate their behaviors in complex environments. However, common MARL algorithms still suffer from scalability and sparse reward issues. One promising approach to resolving them is automatic curriculum learning (ACL). ACL involves a student (curriculum learner) training on tasks of increasing difficulty controlled by a teacher (curriculum generator). Despite its success, ACL's applicability is limited by (1) the lack of a general student framework for dealing with the varying number of agents across tasks and the sparse reward problem, and (2) the non-stationarity of the teacher's task due to ever-changing student strategies. As a remedy for ACL, we introduce a novel automatic curriculum learning framework, Skilled Population Curriculum (SPC), which adapts curriculum learning to multi-agent coordination. Specifically, we endow the student with population-invariant communication and a hierarchical skill set, allowing it to learn cooperation and behavior skills from distinct tasks with varying numbers of agents. In addition, we model the teacher as a contextual bandit conditioned by student policies, enabling a team of agents to change its size while still retaining previously acquired skills. We also analyze the inherent non-stationarity of this multi-agent automatic curriculum teaching problem and provide a corresponding regret bound. Empirical results show that our method improves the performance, scalability and sample efficiency in several MARL environments.
Neural Episodic Control with State Abstraction
Jan 27, 2023
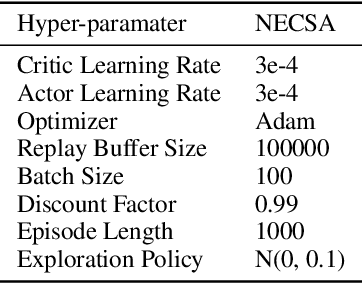

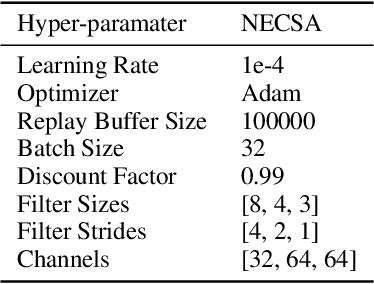
Existing Deep Reinforcement Learning (DRL) algorithms suffer from sample inefficiency. Generally, episodic control-based approaches are solutions that leverage highly-rewarded past experiences to improve sample efficiency of DRL algorithms. However, previous episodic control-based approaches fail to utilize the latent information from the historical behaviors (e.g., state transitions, topological similarities, etc.) and lack scalability during DRL training. This work introduces Neural Episodic Control with State Abstraction (NECSA), a simple but effective state abstraction-based episodic control containing a more comprehensive episodic memory, a novel state evaluation, and a multi-step state analysis. We evaluate our approach to the MuJoCo and Atari tasks in OpenAI gym domains. The experimental results indicate that NECSA achieves higher sample efficiency than the state-of-the-art episodic control-based approaches. Our data and code are available at the project website\footnote{\url{https://sites.google.com/view/drl-necsa}}.
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Oct 04, 2022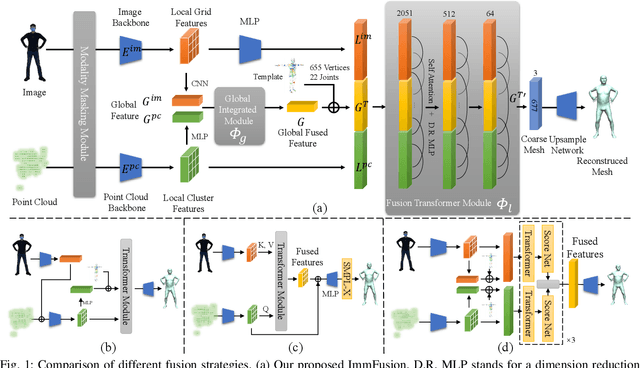
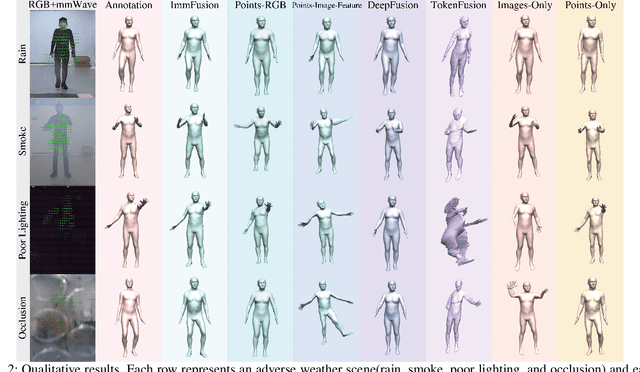

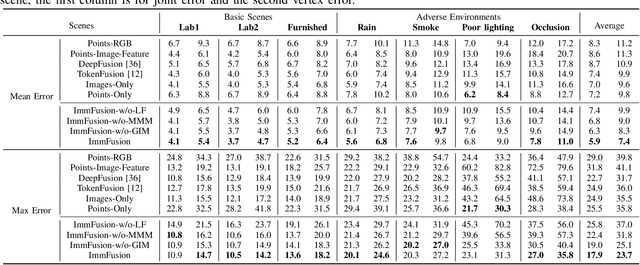
3D human reconstruction from RGB images achieves decent results in good weather conditions but degrades dramatically in rough weather. Complementary, mmWave radars have been employed to reconstruct 3D human joints and meshes in rough weather. However, combining RGB and mmWave signals for robust all-weather 3D human reconstruction is still an open challenge, given the sparse nature of mmWave and the vulnerability of RGB images. In this paper, we present ImmFusion, the first mmWave-RGB fusion solution to reconstruct 3D human bodies in all weather conditions robustly. Specifically, our ImmFusion consists of image and point backbones for token feature extraction and a Transformer module for token fusion. The image and point backbones refine global and local features from original data, and the Fusion Transformer Module aims for effective information fusion of two modalities by dynamically selecting informative tokens. Extensive experiments on a large-scale dataset, mmBody, captured in various environments demonstrate that ImmFusion can efficiently utilize the information of two modalities to achieve a robust 3D human body reconstruction in all weather conditions. In addition, our method's accuracy is significantly superior to that of state-of-the-art Transformer-based LiDAR-camera fusion methods.
EUCLID: Towards Efficient Unsupervised Reinforcement Learning with Multi-choice Dynamics Model
Oct 02, 2022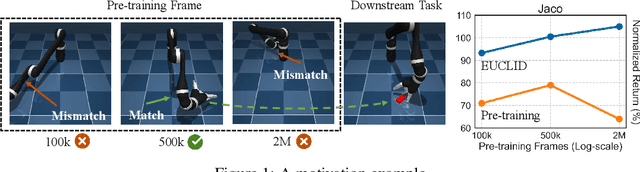
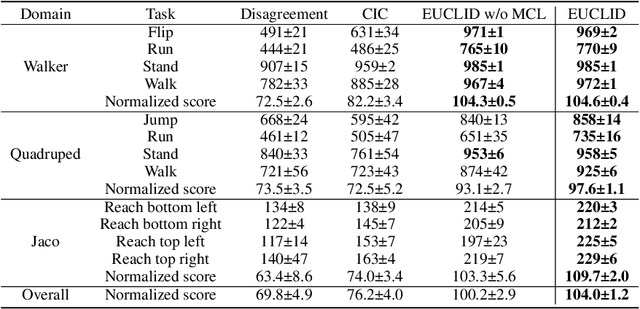
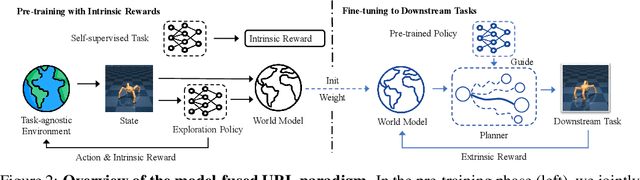
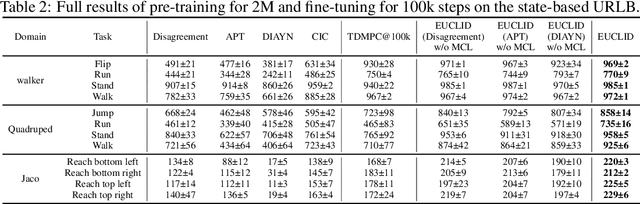
Unsupervised reinforcement learning (URL) poses a promising paradigm to learn useful behaviors in a task-agnostic environment without the guidance of extrinsic rewards to facilitate the fast adaptation of various downstream tasks. Previous works focused on the pre-training in a model-free manner while lacking the study of transition dynamics modeling that leaves a large space for the improvement of sample efficiency in downstream tasks. To this end, we propose an Efficient Unsupervised Reinforcement Learning Framework with Multi-choice Dynamics model (EUCLID), which introduces a novel model-fused paradigm to jointly pre-train the dynamics model and unsupervised exploration policy in the pre-training phase, thus better leveraging the environmental samples and improving the downstream task sampling efficiency. However, constructing a generalizable model which captures the local dynamics under different behaviors remains a challenging problem. We introduce the multi-choice dynamics model that covers different local dynamics under different behaviors concurrently, which uses different heads to learn the state transition under different behaviors during unsupervised pre-training and selects the most appropriate head for prediction in the downstream task. Experimental results in the manipulation and locomotion domains demonstrate that EUCLID achieves state-of-the-art performance with high sample efficiency, basically solving the state-based URLB benchmark and reaching a mean normalized score of 104.0$\pm$1.2$\%$ in downstream tasks with 100k fine-tuning steps, which is equivalent to DDPG's performance at 2M interactive steps with 20x more data.
Distributed Multi-Robot Obstacle Avoidance via Logarithmic Map-based Deep Reinforcement Learning
Sep 14, 2022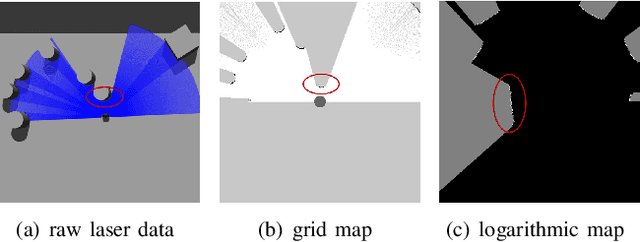

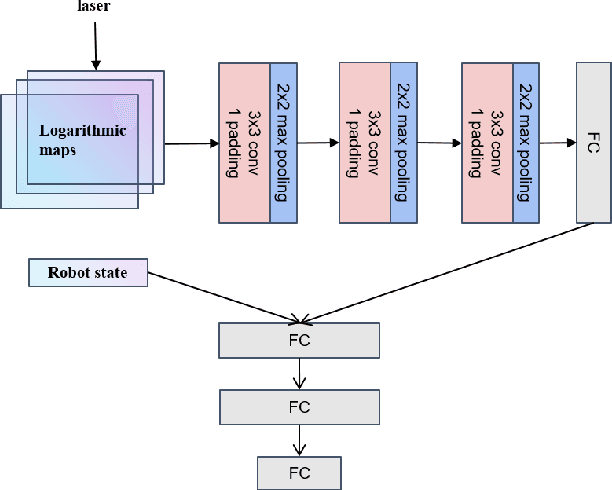
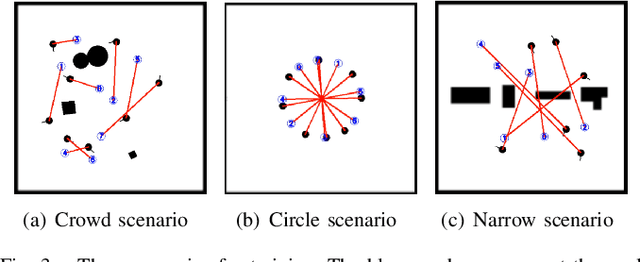
Developing a safe, stable, and efficient obstacle avoidance policy in crowded and narrow scenarios for multiple robots is challenging. Most existing studies either use centralized control or need communication with other robots. In this paper, we propose a novel logarithmic map-based deep reinforcement learning method for obstacle avoidance in complex and communication-free multi-robot scenarios. In particular, our method converts laser information into a logarithmic map. As a step toward improving training speed and generalization performance, our policies will be trained in two specially designed multi-robot scenarios. Compared to other methods, the logarithmic map can represent obstacles more accurately and improve the success rate of obstacle avoidance. We finally evaluate our approach under a variety of simulation and real-world scenarios. The results show that our method provides a more stable and effective navigation solution for robots in complex multi-robot scenarios and pedestrian scenarios. Videos are available at https://youtu.be/r0EsUXe6MZE.