 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Reward Design via Learning Motivation-Consistent Intrinsic Rewards
Jul 29, 2022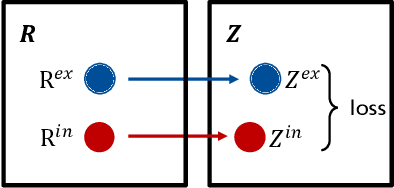


Reward design is a critical part of the application of reinforcement learning, the performance of which strongly depends on how well the reward signal frames the goal of the designer and how well the signal assesses progress in reaching that goal. In many cases, the extrinsic rewards provided by the environment (e.g., win or loss of a game) are very sparse and make it difficult to train agents directly. Researchers usually assist the learning of agents by adding some auxiliary rewards in practice. However, designing auxiliary rewards is often turned to a trial-and-error search for reward settings that produces acceptable results. In this paper, we propose to automatically generate goal-consistent intrinsic rewards for the agent to learn, by maximizing which the expected accumulative extrinsic rewards can be maximized. To this end, we introduce the concept of motivation which captures the underlying goal of maximizing certain rewards and propose the motivation based reward design method. The basic idea is to shape the intrinsic rewards by minimizing the distance between the intrinsic and extrinsic motivations. We conduct extensive experiments and show that our method performs better than the state-of-the-art methods in handling problems of delayed reward, exploration, and credit assignment.
DI-AA: An Interpretable White-box Attack for Fooling Deep Neural Networks
Oct 14, 2021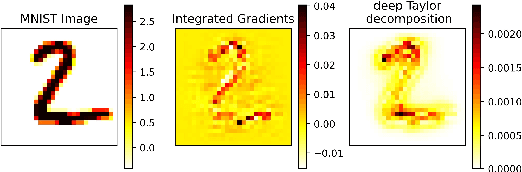
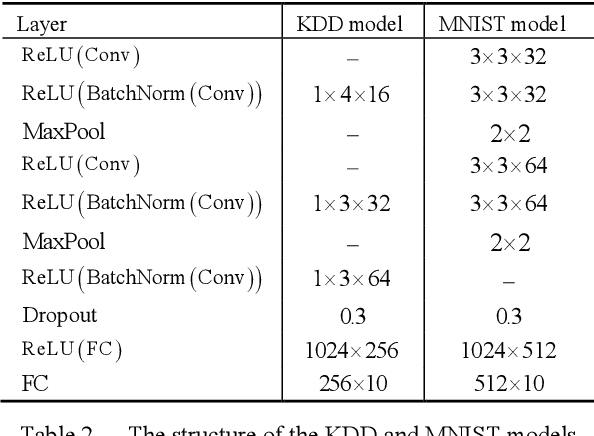
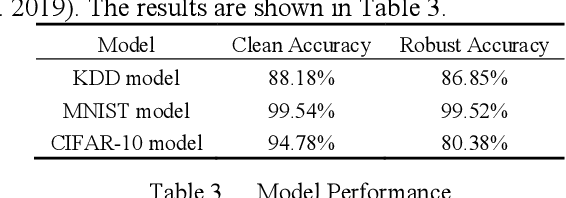
White-box Adversarial Example (AE) attacks towards Deep Neural Networks (DNNs) have a more powerful destructive capacity than black-box AE attacks in the fields of AE strategies. However, almost all the white-box approaches lack interpretation from the point of view of DNNs. That is, adversaries did not investigate the attacks from the perspective of interpretable features, and few of these approaches considered what features the DNN actually learns. In this paper, we propose an interpretable white-box AE attack approach, DI-AA, which explores the application of the interpretable approach of the deep Taylor decomposition in the selection of the most contributing features and adopts the Lagrangian relaxation optimization of the logit output and L_p norm to further decrease the perturbation. We compare DI-AA with six baseline attacks (including the state-of-the-art attack AutoAttack) on three datasets. Experimental results reveal that our proposed approach can 1) attack non-robust models with comparatively low perturbation, where the perturbation is closer to or lower than the AutoAttack approach; 2) break the TRADES adversarial training models with the highest success rate; 3) the generated AE can reduce the robust accuracy of the robust black-box models by 16% to 31% in the black-box transfer attack.
Foster Strengths and Circumvent Weaknesses: a Speech Enhancement Framework with Two-branch Collaborative Learning
Oct 12, 2021
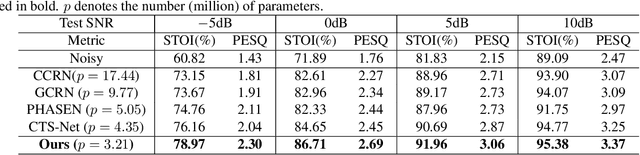
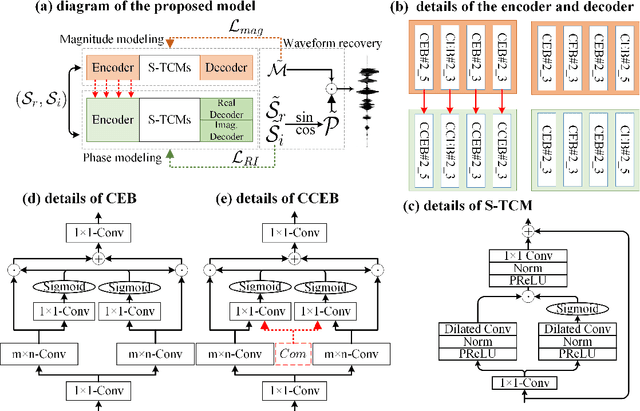
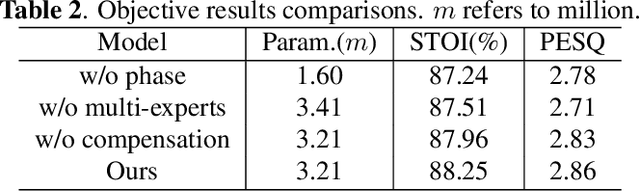
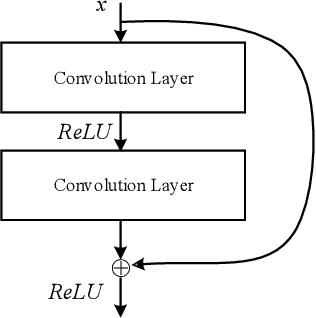
Recent single-channel speech enhancement methods usually convert waveform to the time-frequency domain and use magnitude/complex spectrum as the optimizing target. However, both magnitude-spectrum-based methods and complex-spectrum-based methods have their respective pros and cons. In this paper, we propose a unified two-branch framework to foster strengths and circumvent weaknesses of different paradigms. The proposed framework could take full advantage of the apparent spectral regularity in magnitude spectrogram and break the bottleneck that magnitude-based methods have suffered. Within each branch, we use collaborative expert block and its variants as substitutes for regular convolution layers. Experiments on TIMIT benchmark demonstrate that our method is superior to existing state-of-the-art ones.
IWA: Integrated Gradient based White-box Attacks for Fooling Deep Neural Networks
Feb 03, 2021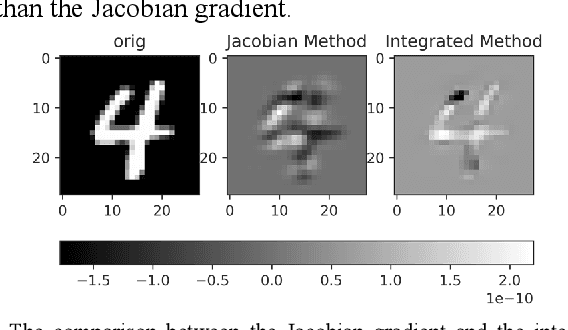
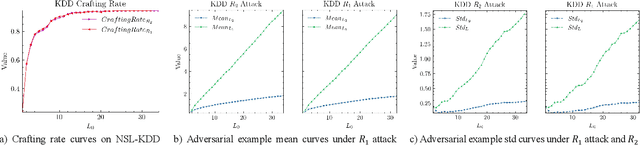
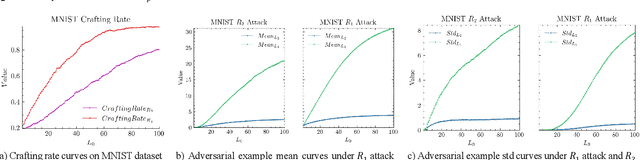
The widespread application of deep neural network (DNN) techniques is being challenged by adversarial examples, the legitimate input added with imperceptible and well-designed perturbations that can fool DNNs easily in the DNN testing/deploying stage. Previous adversarial example generation algorithms for adversarial white-box attacks used Jacobian gradient information to add perturbations. This information is too imprecise and inexplicit, which will cause unnecessary perturbations when generating adversarial examples. This paper aims to address this issue. We first propose to apply a more informative and distilled gradient information, namely integrated gradient, to generate adversarial examples. To further make the perturbations more imperceptible, we propose to employ the restriction combination of $L_0$ and $L_1/L_2$ secondly, which can restrict the total perturbations and perturbation points simultaneously. Meanwhile, to address the non-differentiable problem of $L_1$, we explore a proximal operation of $L_1$ thirdly. Based on these three works, we propose two Integrated gradient based White-box Adversarial example generation algorithms (IWA): IFPA and IUA. IFPA is suitable for situations where there are a determined number of points to be perturbed. IUA is suitable for situations where no perturbation point number is preset in order to obtain more adversarial examples. We verify the effectiveness of the proposed algorithms on both structured and unstructured datasets, and we compare them with five baseline generation algorithms. The results show that our proposed algorithms do craft adversarial examples with more imperceptible perturbations and satisfactory crafting rate. $L_2$ restriction is more suitable for unstructured dataset and $L_1$ restriction performs better in structured dataset.
Generalizing Adversarial Examples by AdaBelief Optimizer
Jan 25, 2021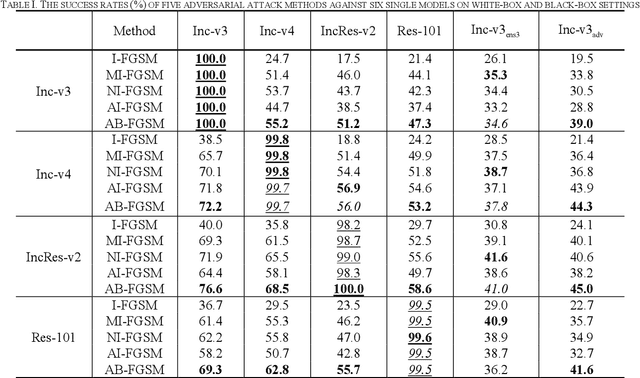
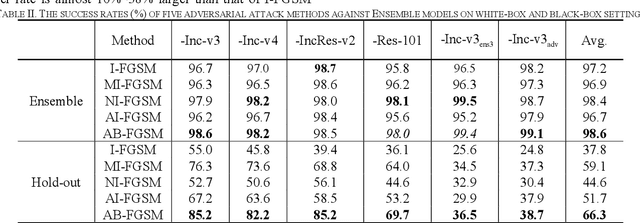
Recent research has proved that deep neural networks (DNNs) are vulnerable to adversarial examples, the legitimate input added with imperceptible and well-designed perturbations can fool DNNs easily in the testing stage. However, most of the existing adversarial attacks are difficult to fool adversarially trained models. To solve this issue, we propose an AdaBelief iterative Fast Gradient Sign Method (AB-FGSM) to generalize adversarial examples. By integrating AdaBelief optimization algorithm to I-FGSM, we believe that the generalization of adversarial examples will be improved, relying on the strong generalization of AdaBelief optimizer. To validate the effectiveness and transferability of adversarial examples generated by our proposed AB-FGSM, we conduct the white-box and black-box attacks on various single models and ensemble models. Compared with state-of-the-art attack methods, our proposed method can generate adversarial examples effectively in the white-box setting, and the transfer rate is 7%-21% higher than latest attack methods.
Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping
Nov 05, 2020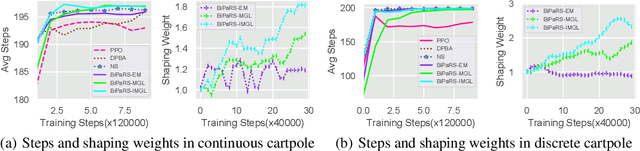
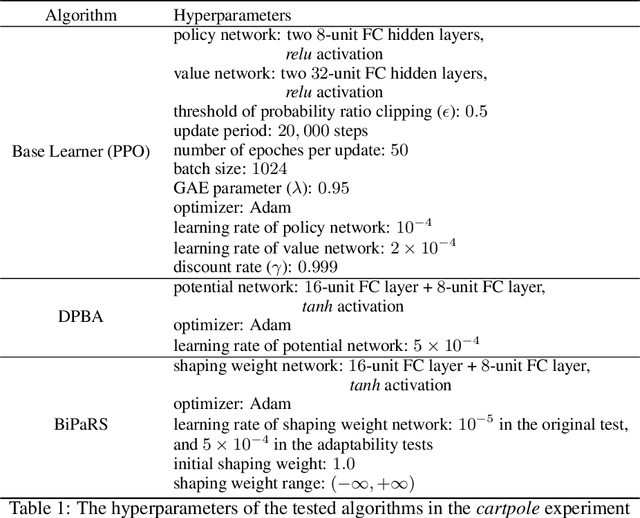
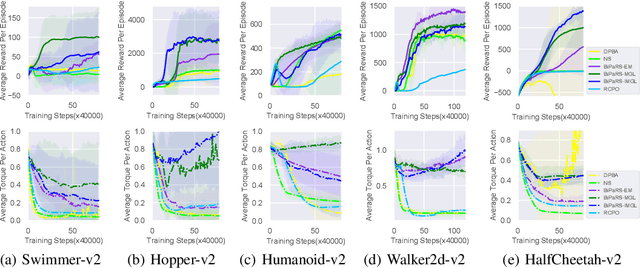

Reward shaping is an effective technique for incorporating domain knowledge into reinforcement learning (RL). Existing approaches such as potential-based reward shaping normally make full use of a given shaping reward function. However, since the transformation of human knowledge into numeric reward values is often imperfect due to reasons such as human cognitive bias, completely utilizing the shaping reward function may fail to improve the performance of RL algorithms. In this paper, we consider the problem of adaptively utilizing a given shaping reward function. We formulate the utilization of shaping rewards as a bi-level optimization problem, where the lower level is to optimize policy using the shaping rewards and the upper level is to optimize a parameterized shaping weight function for true reward maximization. We formally derive the gradient of the expected true reward with respect to the shaping weight function parameters and accordingly propose three learning algorithms based on different assumptions. Experiments in sparse-reward cartpole and MuJoCo environments show that our algorithms can fully exploit beneficial shaping rewards, and meanwhile ignore unbeneficial shaping rewards or even transform them into beneficial ones.
Multi-Agent Deep Reinforcement Learning with Adaptive Policies
Nov 28, 2019
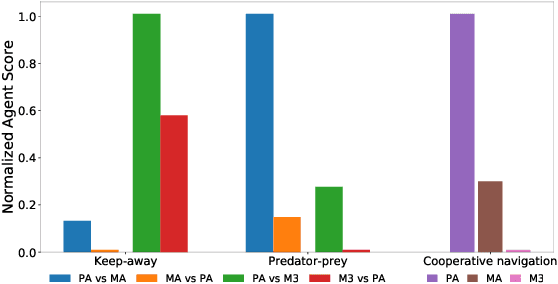
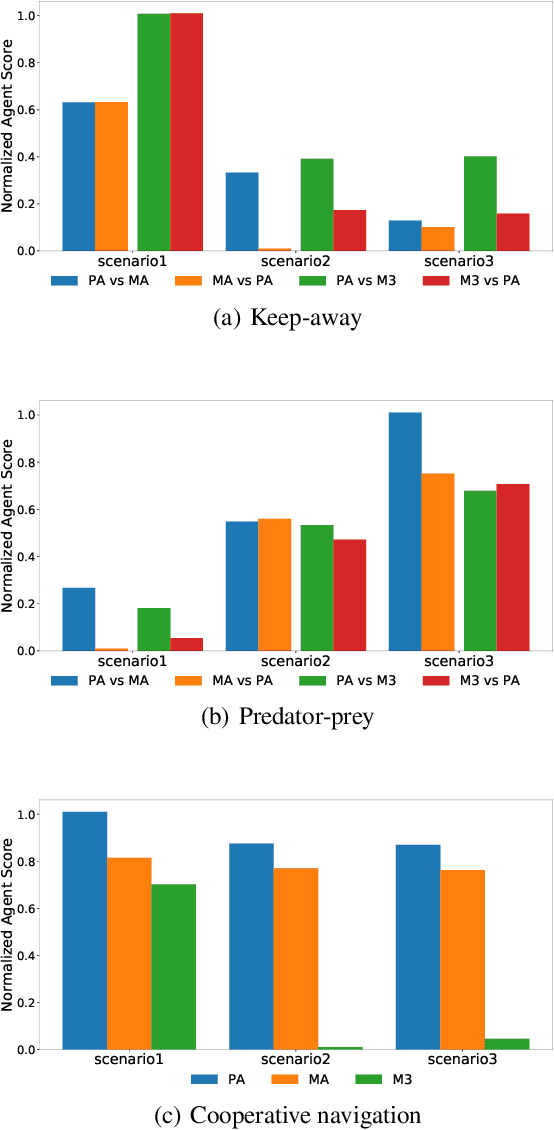
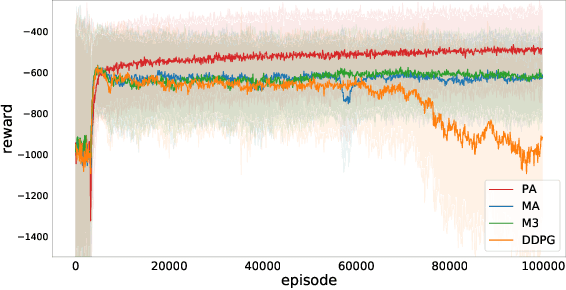
We propose a novel approach to address one aspect of the non-stationarity problem in multi-agent reinforcement learning (RL), where the other agents may alter their policies due to environment changes during execution. This violates the Markov assumption that governs most single-agent RL methods and is one of the key challenges in multi-agent RL. To tackle this, we propose to train multiple policies for each agent and postpone the selection of the best policy at execution time. Specifically, we model the environment non-stationarity with a finite set of scenarios and train policies fitting each scenario. In addition to multiple policies, each agent also learns a policy predictor to determine which policy is the best with its local information. By doing so, each agent is able to adapt its policy when the environment changes and consequentially the other agents alter their policies during execution. We empirically evaluated our method on a variety of common benchmark problems proposed for multi-agent deep RL in the literature. Our experimental results show that the agents trained by our algorithm have better adaptiveness in changing environments and outperform the state-of-the-art methods in all the tested environments.