 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompose Yourself: Average-Velocity Flow Matching for One-Step Speech Enhancement
Sep 19, 2025Diffusion and flow matching (FM) models have achieved remarkable progress in speech enhancement (SE), yet their dependence on multi-step generation is computationally expensive and vulnerable to discretization errors. Recent advances in one-step generative modeling, particularly MeanFlow, provide a promising alternative by reformulating dynamics through average velocity fields. In this work, we present COSE, a one-step FM framework tailored for SE. To address the high training overhead of Jacobian-vector product (JVP) computations in MeanFlow, we introduce a velocity composition identity to compute average velocity efficiently, eliminating expensive computation while preserving theoretical consistency and achieving competitive enhancement quality. Extensive experiments on standard benchmarks show that COSE delivers up to 5x faster sampling and reduces training cost by 40%, all without compromising speech quality. Code is available at https://github.com/ICDM-UESTC/COSE.
Motif-Consistent Counterfactuals with Adversarial Refinement for Graph-Level Anomaly Detection
Jul 18, 2024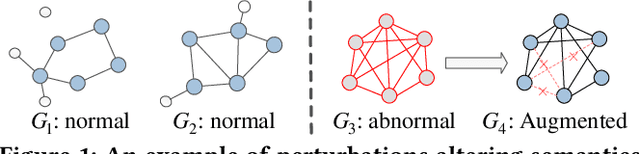
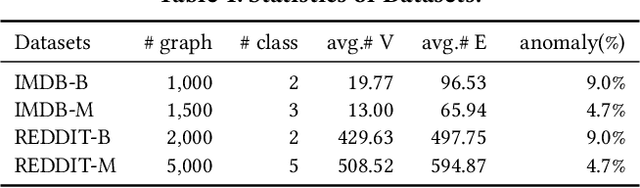
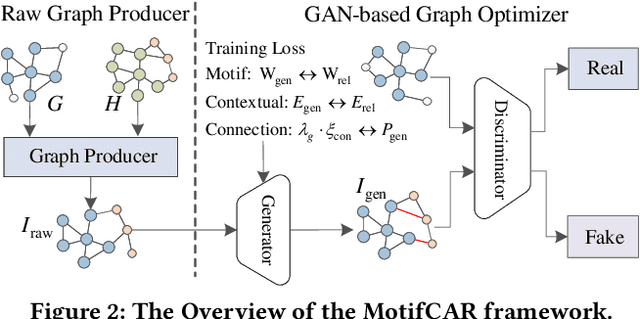
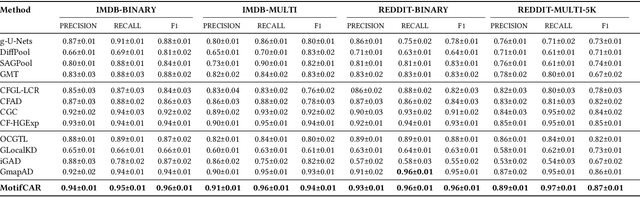
Graph-level anomaly detection is significant in diverse domains. To improve detection performance, counterfactual graphs have been exploited to benefit the generalization capacity by learning causal relations. Most existing studies directly introduce perturbations (e.g., flipping edges) to generate counterfactual graphs, which are prone to alter the semantics of generated examples and make them off the data manifold, resulting in sub-optimal performance. To address these issues, we propose a novel approach, Motif-consistent Counterfactuals with Adversarial Refinement (MotifCAR), for graph-level anomaly detection. The model combines the motif of one graph, the core subgraph containing the identification (category) information, and the contextual subgraph (non-motif) of another graph to produce a raw counterfactual graph. However, the produced raw graph might be distorted and cannot satisfy the important counterfactual properties: Realism, Validity, Proximity and Sparsity. Towards that, we present a Generative Adversarial Network (GAN)-based graph optimizer to refine the raw counterfactual graphs. It adopts the discriminator to guide the generator to generate graphs close to realistic data, i.e., meet the property Realism. Further, we design the motif consistency to force the motif of the generated graphs to be consistent with the realistic graphs, meeting the property Validity. Also, we devise the contextual loss and connection loss to control the contextual subgraph and the newly added links to meet the properties Proximity and Sparsity. As a result, the model can generate high-quality counterfactual graphs. Experiments demonstrate the superiority of MotifCAR.
Foster Strengths and Circumvent Weaknesses: a Speech Enhancement Framework with Two-branch Collaborative Learning
Oct 12, 2021
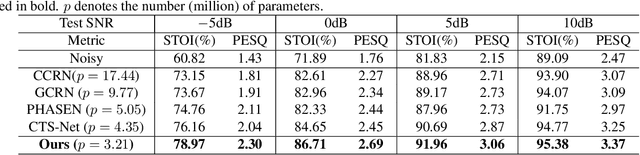
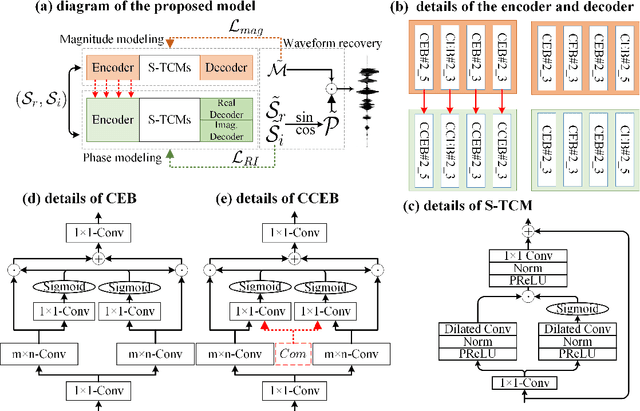
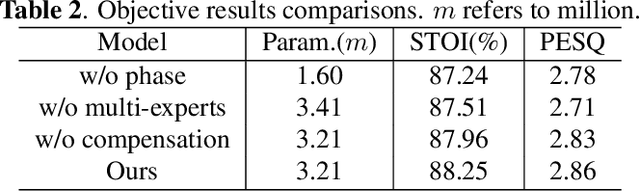
Recent single-channel speech enhancement methods usually convert waveform to the time-frequency domain and use magnitude/complex spectrum as the optimizing target. However, both magnitude-spectrum-based methods and complex-spectrum-based methods have their respective pros and cons. In this paper, we propose a unified two-branch framework to foster strengths and circumvent weaknesses of different paradigms. The proposed framework could take full advantage of the apparent spectral regularity in magnitude spectrogram and break the bottleneck that magnitude-based methods have suffered. Within each branch, we use collaborative expert block and its variants as substitutes for regular convolution layers. Experiments on TIMIT benchmark demonstrate that our method is superior to existing state-of-the-art ones.