 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Behavioral and Response Diversity for Open-ended Learning in Zero-sum Games
Jun 10, 2021

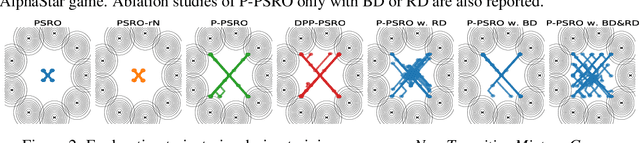

Measuring and promoting policy diversity is critical for solving games with strong non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). With that in mind, maintaining a pool of diverse policies via open-ended learning is an attractive solution, which can generate auto-curricula to avoid being exploited. However, in conventional open-ended learning algorithms, there are no widely accepted definitions for diversity, making it hard to construct and evaluate the diverse policies. In this work, we summarize previous concepts of diversity and work towards offering a unified measure of diversity in multi-agent open-ended learning to include all elements in Markov games, based on both Behavioral Diversity (BD) and Response Diversity (RD). At the trajectory distribution level, we re-define BD in the state-action space as the discrepancies of occupancy measures. For the reward dynamics, we propose RD to characterize diversity through the responses of policies when encountering different opponents. We also show that many current diversity measures fall in one of the categories of BD or RD but not both. With this unified diversity measure, we design the corresponding diversity-promoting objective and population effectivity when seeking the best responses in open-ended learning. We validate our methods in both relatively simple games like matrix game, non-transitive mixture model, and the complex \textit{Google Research Football} environment. The population found by our methods reveals the lowest exploitability, highest population effectivity in matrix game and non-transitive mixture model, as well as the largest goal difference when interacting with opponents of various levels in \textit{Google Research Football}.
Fever Basketball: A Complex, Flexible, and Asynchronized Sports Game Environment for Multi-agent Reinforcement Learning
Dec 06, 2020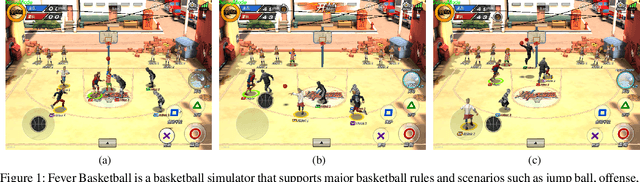
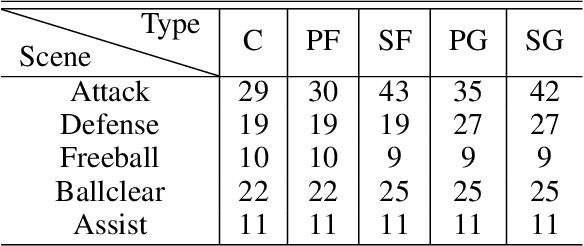
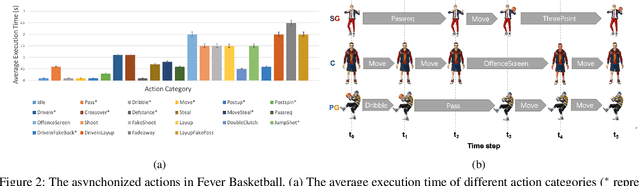

The development of deep reinforcement learning (DRL) has benefited from the emergency of a variety type of game environments where new challenging problems are proposed and new algorithms can be tested safely and quickly, such as Board games, RTS, FPS, and MOBA games. However, many existing environments lack complexity and flexibility and assume the actions are synchronously executed in multi-agent settings, which become less valuable. We introduce the Fever Basketball game, a novel reinforcement learning environment where agents are trained to play basketball game. It is a complex and challenging environment that supports multiple characters, multiple positions, and both the single-agent and multi-agent player control modes. In addition, to better simulate real-world basketball games, the execution time of actions differs among players, which makes Fever Basketball a novel asynchronized environment. We evaluate commonly used multi-agent algorithms of both independent learners and joint-action learners in three game scenarios with varying difficulties, and heuristically propose two baseline methods to diminish the extra non-stationarity brought by asynchronism in Fever Basketball Benchmarks. Besides, we propose an integrated curricula training (ICT) framework to better handle Fever Basketball problems, which includes several game-rule based cascading curricula learners and a coordination curricula switcher focusing on enhancing coordination within the team. The results show that the game remains challenging and can be used as a benchmark environment for studies like long-time horizon, sparse rewards, credit assignment, and non-stationarity, etc. in multi-agent settings.
Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping
Nov 05, 2020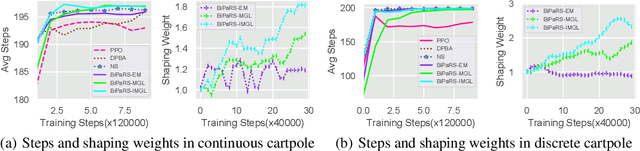
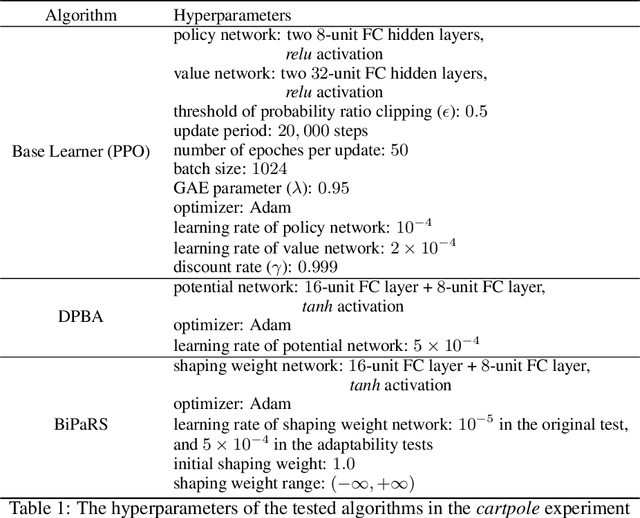
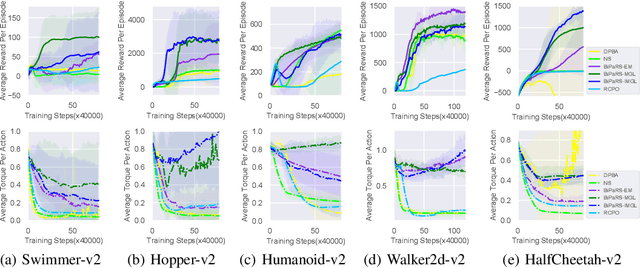

Reward shaping is an effective technique for incorporating domain knowledge into reinforcement learning (RL). Existing approaches such as potential-based reward shaping normally make full use of a given shaping reward function. However, since the transformation of human knowledge into numeric reward values is often imperfect due to reasons such as human cognitive bias, completely utilizing the shaping reward function may fail to improve the performance of RL algorithms. In this paper, we consider the problem of adaptively utilizing a given shaping reward function. We formulate the utilization of shaping rewards as a bi-level optimization problem, where the lower level is to optimize policy using the shaping rewards and the upper level is to optimize a parameterized shaping weight function for true reward maximization. We formally derive the gradient of the expected true reward with respect to the shaping weight function parameters and accordingly propose three learning algorithms based on different assumptions. Experiments in sparse-reward cartpole and MuJoCo environments show that our algorithms can fully exploit beneficial shaping rewards, and meanwhile ignore unbeneficial shaping rewards or even transform them into beneficial ones.
Hierarchical Deep Multiagent Reinforcement Learning
Sep 25, 2018
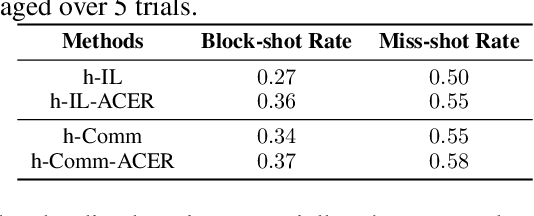
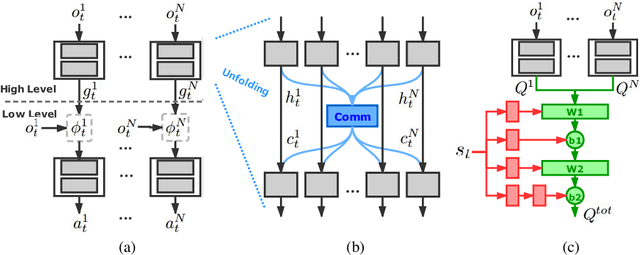
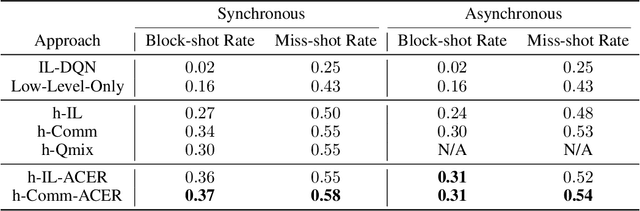
Despite deep reinforcement learning has recently achieved great successes, however in multiagent environments, a number of challenges still remain. Multiagent reinforcement learning (MARL) is commonly considered to suffer from the problem of non-stationary environments and exponentially increasing policy space. It would be even more challenging to learn effective policies in circumstances where the rewards are sparse and delayed over long trajectories. In this paper, we study Hierarchical Deep Multiagent Reinforcement Learning (hierarchical deep MARL) in cooperative multiagent problems with sparse and delayed rewards, where efficient multiagent learning methods are desperately needed. We decompose the original MARL problem into hierarchies and investigate how effective policies can be learned hierarchically in synchronous/asynchronous hierarchical MARL frameworks. Several hierarchical deep MARL architectures, i.e., Ind-hDQN, hCom and hQmix, are introduced for different learning paradigms. Moreover, to alleviate the issues of sparse experiences in high-level learning and non-stationarity in multiagent settings, we propose a new experience replay mechanism, named as Augmented Concurrent Experience Replay (ACER). We empirically demonstrate the effects and efficiency of our approaches in several classic Multiagent Trash Collection tasks, as well as in an extremely challenging team sports game, i.e., Fever Basketball Defense.