 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Deep Multiagent Reinforcement Learning
Paper and Code

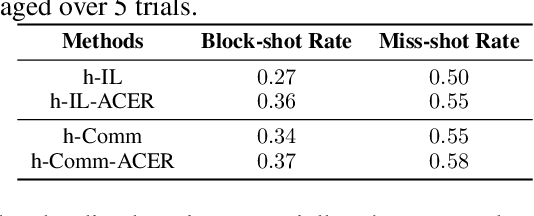
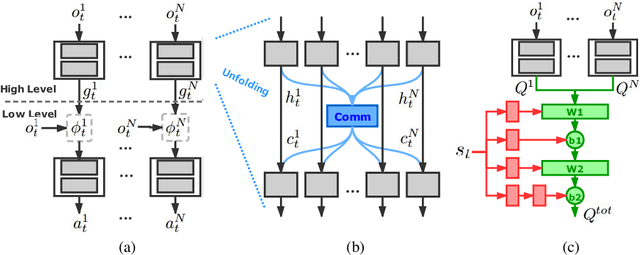
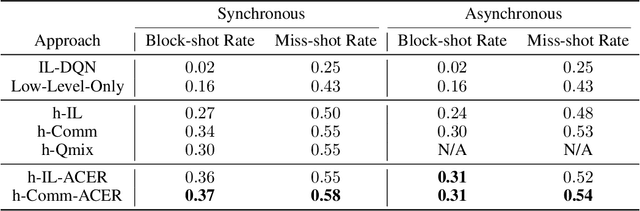
Despite deep reinforcement learning has recently achieved great successes, however in multiagent environments, a number of challenges still remain. Multiagent reinforcement learning (MARL) is commonly considered to suffer from the problem of non-stationary environments and exponentially increasing policy space. It would be even more challenging to learn effective policies in circumstances where the rewards are sparse and delayed over long trajectories. In this paper, we study Hierarchical Deep Multiagent Reinforcement Learning (hierarchical deep MARL) in cooperative multiagent problems with sparse and delayed rewards, where efficient multiagent learning methods are desperately needed. We decompose the original MARL problem into hierarchies and investigate how effective policies can be learned hierarchically in synchronous/asynchronous hierarchical MARL frameworks. Several hierarchical deep MARL architectures, i.e., Ind-hDQN, hCom and hQmix, are introduced for different learning paradigms. Moreover, to alleviate the issues of sparse experiences in high-level learning and non-stationarity in multiagent settings, we propose a new experience replay mechanism, named as Augmented Concurrent Experience Replay (ACER). We empirically demonstrate the effects and efficiency of our approaches in several classic Multiagent Trash Collection tasks, as well as in an extremely challenging team sports game, i.e., Fever Basketball Defense.