 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Point-Supervised Signal Reconstruction: A Human-Annotation-Free Framework for Weak Moving Target Detection
Jul 23, 2025In low-altitude surveillance and early warning systems, detecting weak moving targets remains a significant challenge due to low signal energy, small spatial extent, and complex background clutter. Existing methods struggle with extracting robust features and suffer from the lack of reliable annotations. To address these limitations, we propose a novel Temporal Point-Supervised (TPS) framework that enables high-performance detection of weak targets without any manual annotations.Instead of conventional frame-based detection, our framework reformulates the task as a pixel-wise temporal signal modeling problem, where weak targets manifest as short-duration pulse-like responses. A Temporal Signal Reconstruction Network (TSRNet) is developed under the TPS paradigm to reconstruct these transient signals.TSRNet adopts an encoder-decoder architecture and integrates a Dynamic Multi-Scale Attention (DMSAttention) module to enhance its sensitivity to diverse temporal patterns. Additionally, a graph-based trajectory mining strategy is employed to suppress false alarms and ensure temporal consistency.Extensive experiments on a purpose-built low-SNR dataset demonstrate that our framework outperforms state-of-the-art methods while requiring no human annotations. It achieves strong detection performance and operates at over 1000 FPS, underscoring its potential for real-time deployment in practical scenarios.
Fever Basketball: A Complex, Flexible, and Asynchronized Sports Game Environment for Multi-agent Reinforcement Learning
Dec 06, 2020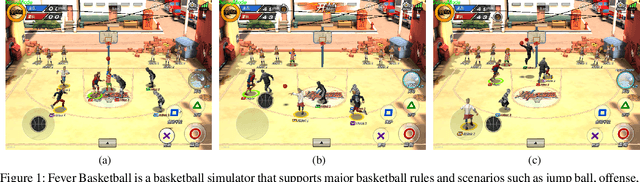
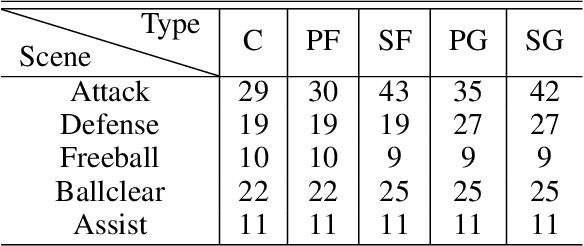
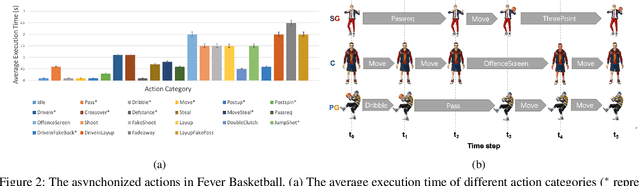

The development of deep reinforcement learning (DRL) has benefited from the emergency of a variety type of game environments where new challenging problems are proposed and new algorithms can be tested safely and quickly, such as Board games, RTS, FPS, and MOBA games. However, many existing environments lack complexity and flexibility and assume the actions are synchronously executed in multi-agent settings, which become less valuable. We introduce the Fever Basketball game, a novel reinforcement learning environment where agents are trained to play basketball game. It is a complex and challenging environment that supports multiple characters, multiple positions, and both the single-agent and multi-agent player control modes. In addition, to better simulate real-world basketball games, the execution time of actions differs among players, which makes Fever Basketball a novel asynchronized environment. We evaluate commonly used multi-agent algorithms of both independent learners and joint-action learners in three game scenarios with varying difficulties, and heuristically propose two baseline methods to diminish the extra non-stationarity brought by asynchronism in Fever Basketball Benchmarks. Besides, we propose an integrated curricula training (ICT) framework to better handle Fever Basketball problems, which includes several game-rule based cascading curricula learners and a coordination curricula switcher focusing on enhancing coordination within the team. The results show that the game remains challenging and can be used as a benchmark environment for studies like long-time horizon, sparse rewards, credit assignment, and non-stationarity, etc. in multi-agent settings.
Hierarchical Deep Multiagent Reinforcement Learning
Sep 25, 2018
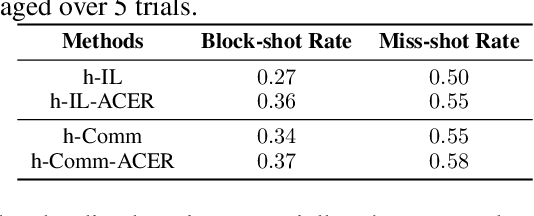
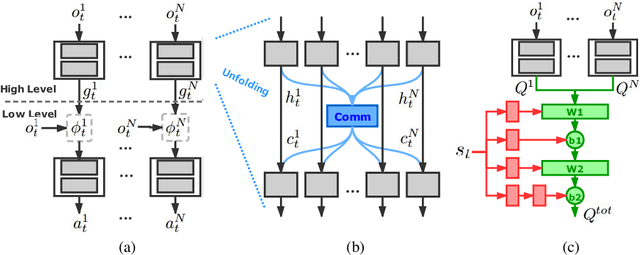
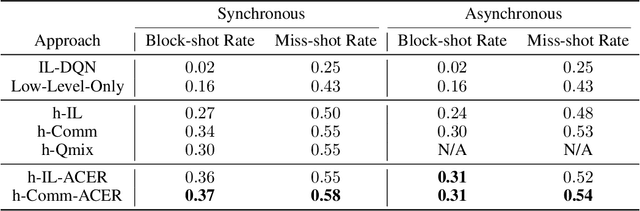
Despite deep reinforcement learning has recently achieved great successes, however in multiagent environments, a number of challenges still remain. Multiagent reinforcement learning (MARL) is commonly considered to suffer from the problem of non-stationary environments and exponentially increasing policy space. It would be even more challenging to learn effective policies in circumstances where the rewards are sparse and delayed over long trajectories. In this paper, we study Hierarchical Deep Multiagent Reinforcement Learning (hierarchical deep MARL) in cooperative multiagent problems with sparse and delayed rewards, where efficient multiagent learning methods are desperately needed. We decompose the original MARL problem into hierarchies and investigate how effective policies can be learned hierarchically in synchronous/asynchronous hierarchical MARL frameworks. Several hierarchical deep MARL architectures, i.e., Ind-hDQN, hCom and hQmix, are introduced for different learning paradigms. Moreover, to alleviate the issues of sparse experiences in high-level learning and non-stationarity in multiagent settings, we propose a new experience replay mechanism, named as Augmented Concurrent Experience Replay (ACER). We empirically demonstrate the effects and efficiency of our approaches in several classic Multiagent Trash Collection tasks, as well as in an extremely challenging team sports game, i.e., Fever Basketball Defense.