 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDI-AA: An Interpretable White-box Attack for Fooling Deep Neural Networks
Oct 14, 2021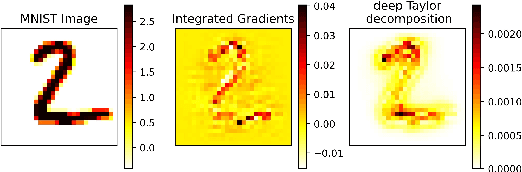
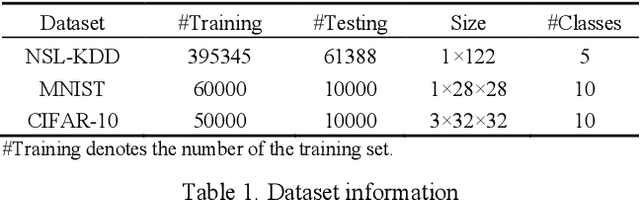
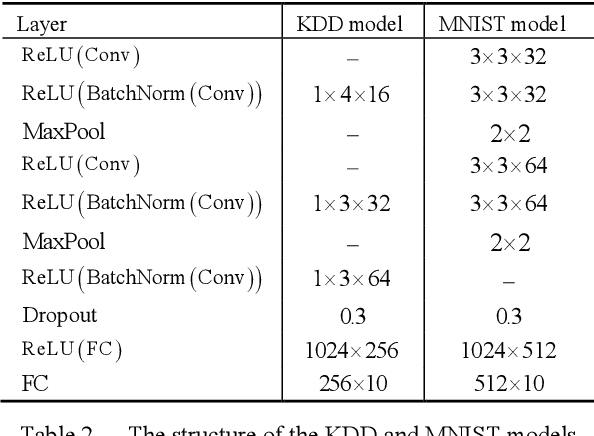
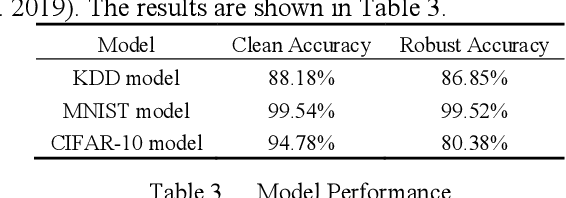
White-box Adversarial Example (AE) attacks towards Deep Neural Networks (DNNs) have a more powerful destructive capacity than black-box AE attacks in the fields of AE strategies. However, almost all the white-box approaches lack interpretation from the point of view of DNNs. That is, adversaries did not investigate the attacks from the perspective of interpretable features, and few of these approaches considered what features the DNN actually learns. In this paper, we propose an interpretable white-box AE attack approach, DI-AA, which explores the application of the interpretable approach of the deep Taylor decomposition in the selection of the most contributing features and adopts the Lagrangian relaxation optimization of the logit output and L_p norm to further decrease the perturbation. We compare DI-AA with six baseline attacks (including the state-of-the-art attack AutoAttack) on three datasets. Experimental results reveal that our proposed approach can 1) attack non-robust models with comparatively low perturbation, where the perturbation is closer to or lower than the AutoAttack approach; 2) break the TRADES adversarial training models with the highest success rate; 3) the generated AE can reduce the robust accuracy of the robust black-box models by 16% to 31% in the black-box transfer attack.