 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: A Stealthy and Efficient Adversarial Attack Method for DRL-based Autonomous Driving Policies
Dec 04, 2024Despite significant advancements in deep reinforcement learning (DRL)-based autonomous driving policies, these policies still exhibit vulnerability to adversarial attacks. This vulnerability poses a formidable challenge to the practical deployment of these policies in autonomous driving. Designing effective adversarial attacks is an indispensable prerequisite for enhancing the robustness of these policies. In view of this, we present a novel stealthy and efficient adversarial attack method for DRL-based autonomous driving policies. Specifically, we introduce a DRL-based adversary designed to trigger safety violations (e.g., collisions) by injecting adversarial samples at critical moments. We model the attack as a mixed-integer optimization problem and formulate it as a Markov decision process. Then, we train the adversary to learn the optimal policy for attacking at critical moments without domain knowledge. Furthermore, we introduce attack-related information and a trajectory clipping method to enhance the learning capability of the adversary. Finally, we validate our method in an unprotected left-turn scenario across different traffic densities. The experimental results show that our method achieves more than 90% collision rate within three attacks in most cases. Furthermore, our method achieves more than 130% improvement in attack efficiency compared to the unlimited attack method.
CRS-FL: Conditional Random Sampling for Communication-Efficient and Privacy-Preserving Federated Learning
Jun 07, 2023


Federated Learning (FL), a privacy-oriented distributed ML paradigm, is being gaining great interest in Internet of Things because of its capability to protect participants data privacy. Studies have been conducted to address challenges existing in standard FL, including communication efficiency and privacy-preserving. But they cannot achieve the goal of making a tradeoff between communication efficiency and model accuracy while guaranteeing privacy. This paper proposes a Conditional Random Sampling (CRS) method and implements it into the standard FL settings (CRS-FL) to tackle the above-mentioned challenges. CRS explores a stochastic coefficient based on Poisson sampling to achieve a higher probability of obtaining zero-gradient unbiasedly, and then decreases the communication overhead effectively without model accuracy degradation. Moreover, we dig out the relaxation Local Differential Privacy (LDP) guarantee conditions of CRS theoretically. Extensive experiment results indicate that (1) in communication efficiency, CRS-FL performs better than the existing methods in metric accuracy per transmission byte without model accuracy reduction in more than 7% sampling ratio (# sampling size / # model size); (2) in privacy-preserving, CRS-FL achieves no accuracy reduction compared with LDP baselines while holding the efficiency, even exceeding them in model accuracy under more sampling ratio conditions.
Android Malware Detection using Feature Ranking of Permissions
Jan 20, 2022


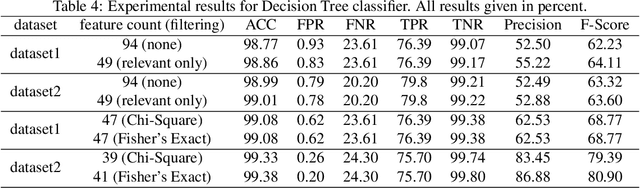
We investigate the use of Android permissions as the vehicle to allow for quick and effective differentiation between benign and malware apps. To this end, we extract all Android permissions, eliminating those that have zero impact, and apply two feature ranking algorithms namely Chi-Square test and Fisher's Exact test to rank and additionally filter them, resulting in a comparatively small set of relevant permissions. Then we use Decision Tree, Support Vector Machine, and Random Forest Classifier algorithms to detect malware apps. Our analysis indicates that this approach can result in better accuracy and F-score value than other reported approaches. In particular, when random forest is used as the classifier with the combination of Fisher's Exact test, we achieve 99.34\% in accuracy and 92.17\% in F-score with the false positive rate of 0.56\% for the dataset in question, with results improving to 99.82\% in accuracy and 95.28\% in F-score with the false positive rate as low as 0.05\% when only malware from three most popular malware families are considered.
IWA: Integrated Gradient based White-box Attacks for Fooling Deep Neural Networks
Feb 03, 2021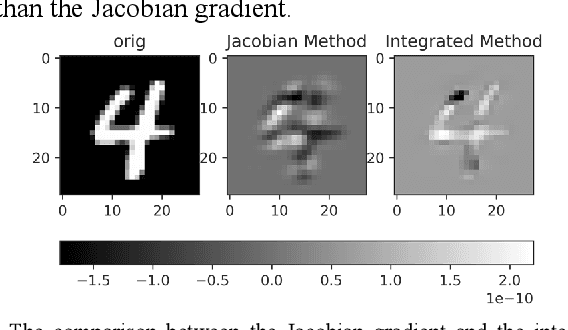
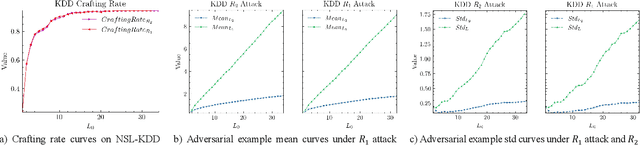
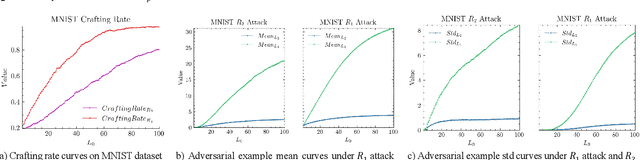
The widespread application of deep neural network (DNN) techniques is being challenged by adversarial examples, the legitimate input added with imperceptible and well-designed perturbations that can fool DNNs easily in the DNN testing/deploying stage. Previous adversarial example generation algorithms for adversarial white-box attacks used Jacobian gradient information to add perturbations. This information is too imprecise and inexplicit, which will cause unnecessary perturbations when generating adversarial examples. This paper aims to address this issue. We first propose to apply a more informative and distilled gradient information, namely integrated gradient, to generate adversarial examples. To further make the perturbations more imperceptible, we propose to employ the restriction combination of $L_0$ and $L_1/L_2$ secondly, which can restrict the total perturbations and perturbation points simultaneously. Meanwhile, to address the non-differentiable problem of $L_1$, we explore a proximal operation of $L_1$ thirdly. Based on these three works, we propose two Integrated gradient based White-box Adversarial example generation algorithms (IWA): IFPA and IUA. IFPA is suitable for situations where there are a determined number of points to be perturbed. IUA is suitable for situations where no perturbation point number is preset in order to obtain more adversarial examples. We verify the effectiveness of the proposed algorithms on both structured and unstructured datasets, and we compare them with five baseline generation algorithms. The results show that our proposed algorithms do craft adversarial examples with more imperceptible perturbations and satisfactory crafting rate. $L_2$ restriction is more suitable for unstructured dataset and $L_1$ restriction performs better in structured dataset.