 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Adversarial Examples by AdaBelief Optimizer
Paper and Code
Jan 25, 2021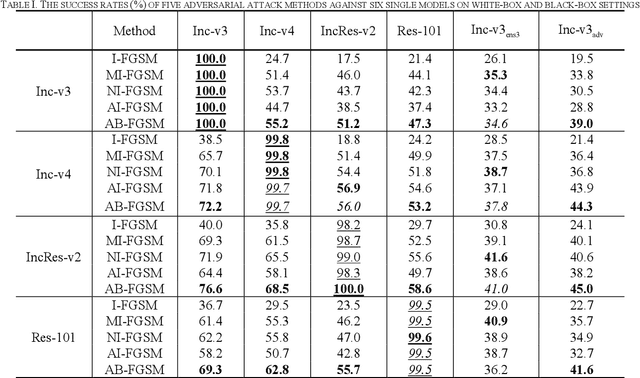
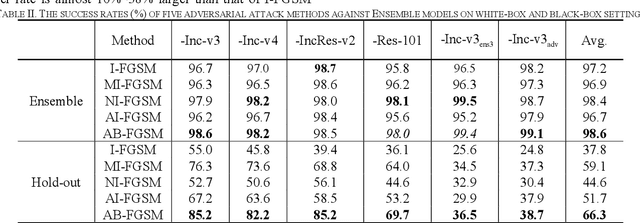
Recent research has proved that deep neural networks (DNNs) are vulnerable to adversarial examples, the legitimate input added with imperceptible and well-designed perturbations can fool DNNs easily in the testing stage. However, most of the existing adversarial attacks are difficult to fool adversarially trained models. To solve this issue, we propose an AdaBelief iterative Fast Gradient Sign Method (AB-FGSM) to generalize adversarial examples. By integrating AdaBelief optimization algorithm to I-FGSM, we believe that the generalization of adversarial examples will be improved, relying on the strong generalization of AdaBelief optimizer. To validate the effectiveness and transferability of adversarial examples generated by our proposed AB-FGSM, we conduct the white-box and black-box attacks on various single models and ensemble models. Compared with state-of-the-art attack methods, our proposed method can generate adversarial examples effectively in the white-box setting, and the transfer rate is 7%-21% higher than latest attack methods.