 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Discounting of Training Time Attacks
Jan 05, 2024



Among the most insidious attacks on Reinforcement Learning (RL) solutions are training-time attacks (TTAs) that create loopholes and backdoors in the learned behaviour. Not limited to a simple disruption, constructive TTAs (C-TTAs) are now available, where the attacker forces a specific, target behaviour upon a training RL agent (victim). However, even state-of-the-art C-TTAs focus on target behaviours that could be naturally adopted by the victim if not for a particular feature of the environment dynamics, which C-TTAs exploit. In this work, we show that a C-TTA is possible even when the target behaviour is un-adoptable due to both environment dynamics as well as non-optimality with respect to the victim objective(s). To find efficient attacks in this context, we develop a specialised flavour of the DDPG algorithm, which we term gammaDDPG, that learns this stronger version of C-TTA. gammaDDPG dynamically alters the attack policy planning horizon based on the victim's current behaviour. This improves effort distribution throughout the attack timeline and reduces the effect of uncertainty the attacker has about the victim. To demonstrate the features of our method and better relate the results to prior research, we borrow a 3D grid domain from a state-of-the-art C-TTA for our experiments. Code is available at "bit.ly/github-rb-gDDPG".
Policy Resilience to Environment Poisoning Attacks on Reinforcement Learning
Apr 24, 2023



This paper investigates policy resilience to training-environment poisoning attacks on reinforcement learning (RL) policies, with the goal of recovering the deployment performance of a poisoned RL policy. Due to the fact that the policy resilience is an add-on concern to RL algorithms, it should be resource-efficient, time-conserving, and widely applicable without compromising the performance of RL algorithms. This paper proposes such a policy-resilience mechanism based on an idea of knowledge sharing. We summarize the policy resilience as three stages: preparation, diagnosis, recovery. Specifically, we design the mechanism as a federated architecture coupled with a meta-learning manner, pursuing an efficient extraction and sharing of the environment knowledge. With the shared knowledge, a poisoned agent can quickly identify the deployment condition and accordingly recover its policy performance. We empirically evaluate the resilience mechanism for both model-based and model-free RL algorithms, showing its effectiveness and efficiency in restoring the deployment performance of a poisoned policy.
Towards Skilled Population Curriculum for Multi-Agent Reinforcement Learning
Feb 07, 2023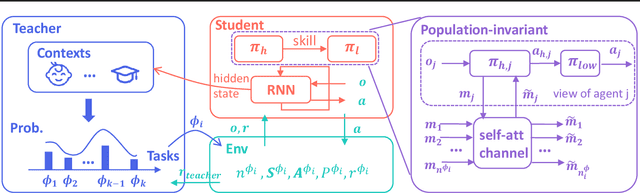


Recent advances in multi-agent reinforcement learning (MARL) allow agents to coordinate their behaviors in complex environments. However, common MARL algorithms still suffer from scalability and sparse reward issues. One promising approach to resolving them is automatic curriculum learning (ACL). ACL involves a student (curriculum learner) training on tasks of increasing difficulty controlled by a teacher (curriculum generator). Despite its success, ACL's applicability is limited by (1) the lack of a general student framework for dealing with the varying number of agents across tasks and the sparse reward problem, and (2) the non-stationarity of the teacher's task due to ever-changing student strategies. As a remedy for ACL, we introduce a novel automatic curriculum learning framework, Skilled Population Curriculum (SPC), which adapts curriculum learning to multi-agent coordination. Specifically, we endow the student with population-invariant communication and a hierarchical skill set, allowing it to learn cooperation and behavior skills from distinct tasks with varying numbers of agents. In addition, we model the teacher as a contextual bandit conditioned by student policies, enabling a team of agents to change its size while still retaining previously acquired skills. We also analyze the inherent non-stationarity of this multi-agent automatic curriculum teaching problem and provide a corresponding regret bound. Empirical results show that our method improves the performance, scalability and sample efficiency in several MARL environments.
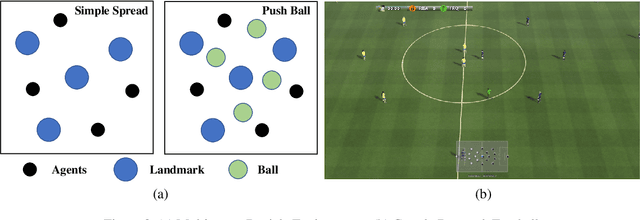
Off-Beat Multi-Agent Reinforcement Learning
May 27, 2022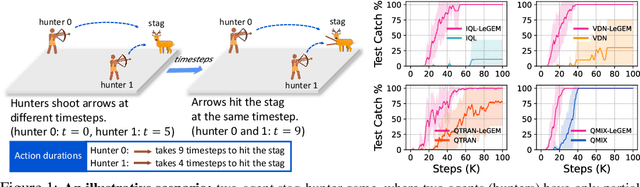

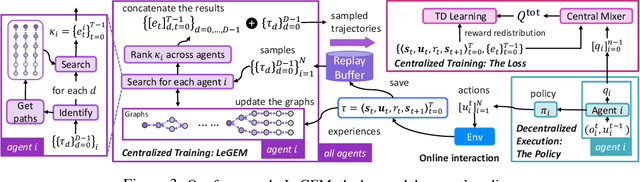
We investigate model-free multi-agent reinforcement learning (MARL) in environments where off-beat actions are prevalent, i.e., all actions have pre-set execution durations. During execution durations, the environment changes are influenced by, but not synchronised with, action execution. Such a setting is ubiquitous in many real-world problems. However, most MARL methods assume actions are executed immediately after inference, which is often unrealistic and can lead to catastrophic failure for multi-agent coordination with off-beat actions. In order to fill this gap, we develop an algorithmic framework for MARL with off-beat actions. We then propose a novel episodic memory, LeGEM, for model-free MARL algorithms. LeGEM builds agents' episodic memories by utilizing agents' individual experiences. It boosts multi-agent learning by addressing the challenging temporal credit assignment problem raised by the off-beat actions via our novel reward redistribution scheme, alleviating the issue of non-Markovian reward. We evaluate LeGEM on various multi-agent scenarios with off-beat actions, including Stag-Hunter Game, Quarry Game, Afforestation Game, and StarCraft II micromanagement tasks. Empirical results show that LeGEM significantly boosts multi-agent coordination and achieves leading performance and improved sample efficiency.
Mis-spoke or mis-lead: Achieving Robustness in Multi-Agent Communicative Reinforcement Learning
Aug 09, 2021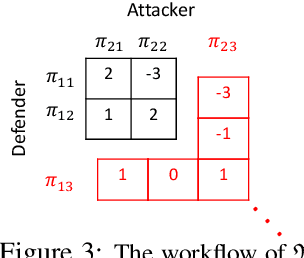
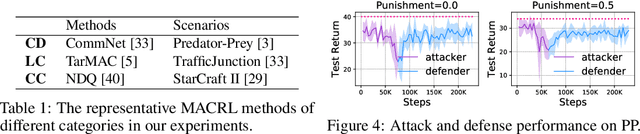
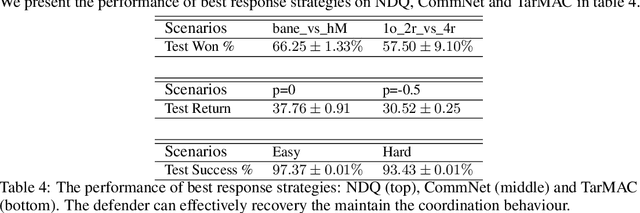

Recent studies in multi-agent communicative reinforcement learning (MACRL) demonstrate that multi-agent coordination can be significantly improved when communication between agents is allowed. Meanwhile, advances in adversarial machine learning (ML) have shown that ML and reinforcement learning (RL) models are vulnerable to a variety of attacks that significantly degrade the performance of learned behaviours. However, despite the obvious and growing importance, the combination of adversarial ML and MACRL remains largely uninvestigated. In this paper, we make the first step towards conducting message attacks on MACRL methods. In our formulation, one agent in the cooperating group is taken over by an adversary and can send malicious messages to disrupt a deployed MACRL-based coordinated strategy during the deployment phase. We further our study by developing a defence method via message reconstruction. Finally, we address the resulting arms race, i.e., we consider the ability of the malicious agent to adapt to the changing and improving defensive communicative policies of the benign agents. Specifically, we model the adversarial MACRL problem as a two-player zero-sum game and then utilize Policy-Space Response Oracle to achieve communication robustness. Empirically, we demonstrate that MACRL methods are vulnerable to message attacks while our defence method the game-theoretic framework can effectively improve the robustness of MACRL.
RMIX: Learning Risk-Sensitive Policies for Cooperative Reinforcement Learning Agents
Feb 17, 2021
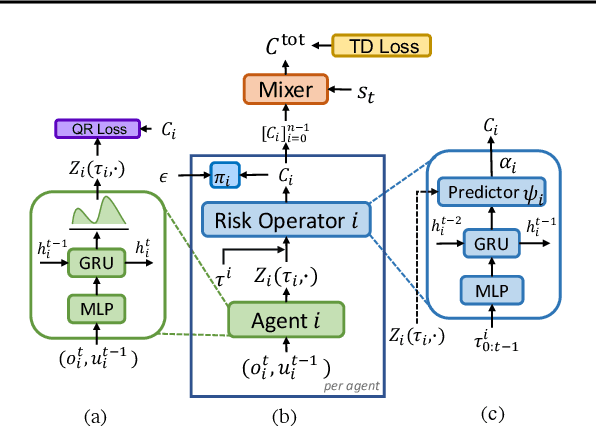
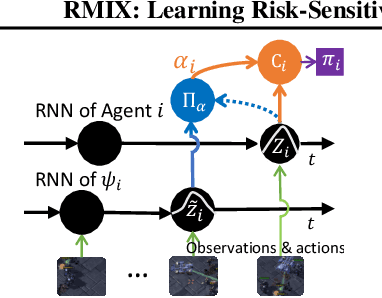
Current value-based multi-agent reinforcement learning methods optimize individual Q values to guide individuals' behaviours via centralized training with decentralized execution (CTDE). However, such expected, i.e., risk-neutral, Q value is not sufficient even with CTDE due to the randomness of rewards and the uncertainty in environments, which causes the failure of these methods to train coordinating agents in complex environments. To address these issues, we propose RMIX, a novel cooperative MARL method with the Conditional Value at Risk (CVaR) measure over the learned distributions of individuals' Q values. Specifically, we first learn the return distributions of individuals to analytically calculate CVaR for decentralized execution. Then, to handle the temporal nature of the stochastic outcomes during executions, we propose a dynamic risk level predictor for risk level tuning. Finally, we optimize the CVaR policies with CVaR values used to estimate the target in TD error during centralized training and the CVaR values are used as auxiliary local rewards to update the local distribution via Quantile Regression loss. Empirically, we show that our method significantly outperforms state-of-the-art methods on challenging StarCraft II tasks, demonstrating enhanced coordination and improved sample efficiency.
Learning Efficient Multi-agent Communication: An Information Bottleneck Approach
Nov 16, 2019
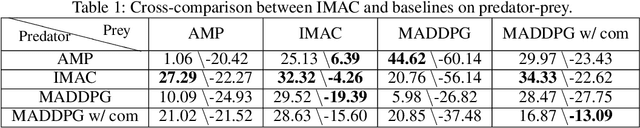
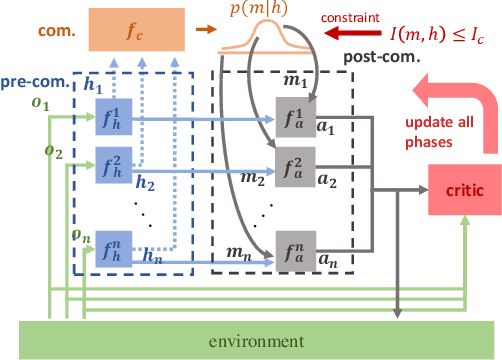
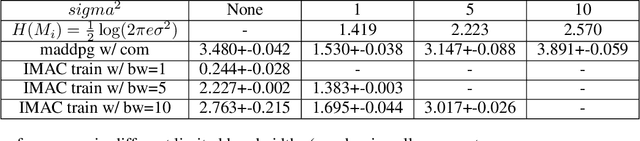
Many real-world multi-agent reinforcement learning applications require agents to communicate, assisted by a communication protocol. These applications face a common and critical issue of communication's limited bandwidth that constrains agents' ability to cooperate successfully. In this paper, rather than proposing a fixed communication protocol, we develop an Informative Multi-Agent Communication (IMAC) method to learn efficient communication protocols. Our contributions are threefold. First, we notice a fact that a limited bandwidth translates into a constraint on the communicated message entropy, thus paving the way of controlling the bandwidth. Second, we introduce a customized batch-norm layer, which controls the messages' entropy to simulate the limited bandwidth constraint. Third, we apply the information bottleneck method to discover the optimal communication protocol, which can satisfy a bandwidth constraint via training with the prior distribution in the method. To demonstrate the efficacy of our method, we conduct extensive experiments in various cooperative and competitive multi-agent tasks across two dimensions: the number of agents and different bandwidths. We show that IMAC converges fast, and leads to efficient communication among agents under the limited-bandwidth constraint as compared to many baseline methods.
Lie on the Fly: Strategic Voting in an Iterative Preference Elicitation Process
May 13, 2019
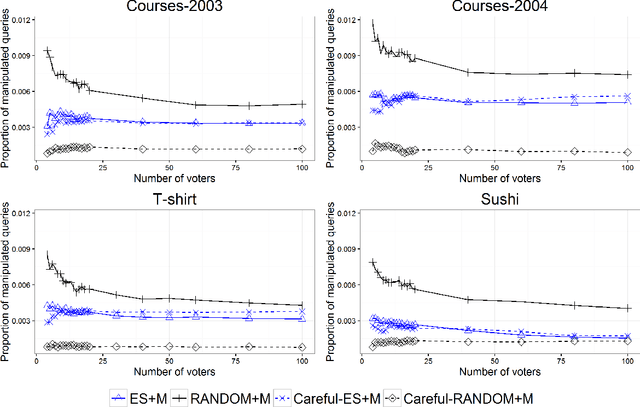
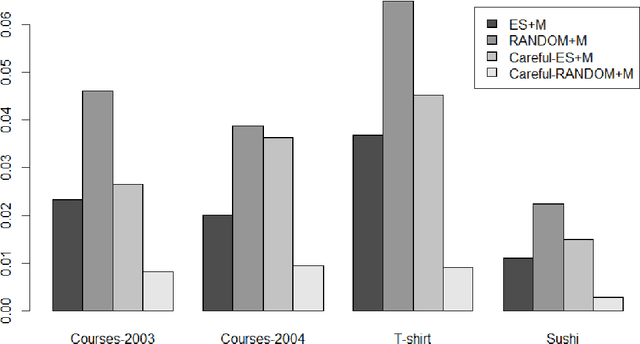
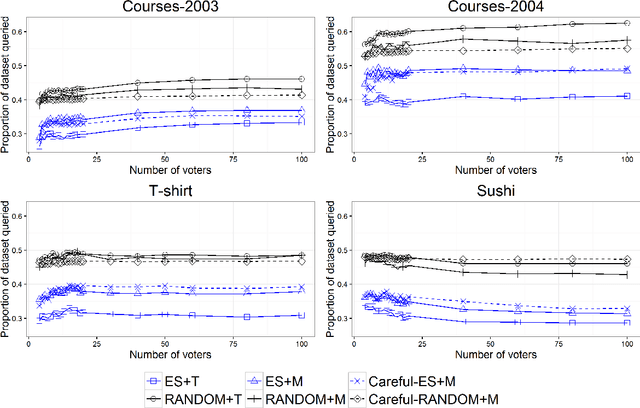
A voting center is in charge of collecting and aggregating voter preferences. In an iterative process, the center sends comparison queries to voters, requesting them to submit their preference between two items. Voters might discuss the candidates among themselves, figuring out during the elicitation process which candidates stand a chance of winning and which do not. Consequently, strategic voters might attempt to manipulate by deviating from their true preferences and instead submit a different response in order to attempt to maximize their profit. We provide a practical algorithm for strategic voters which computes the best manipulative vote and maximizes the voter's selfish outcome when such a vote exists. We also provide a careful voting center which is aware of the possible manipulations and avoids manipulative queries when possible. In an empirical study on four real-world domains, we show that in practice manipulation occurs in a low percentage of settings and has a low impact on the final outcome. The careful voting center reduces manipulation even further, thus allowing for a non-distorted group decision process to take place. We thus provide a core technology study of a voting process that can be adopted in opinion or information aggregation systems and in crowdsourcing applications, e.g., peer grading in Massive Open Online Courses (MOOCs).
Security Games with Information Leakage: Modeling and Computation
May 04, 2015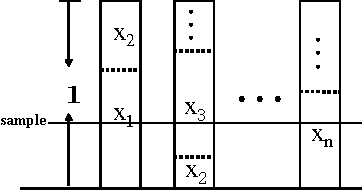
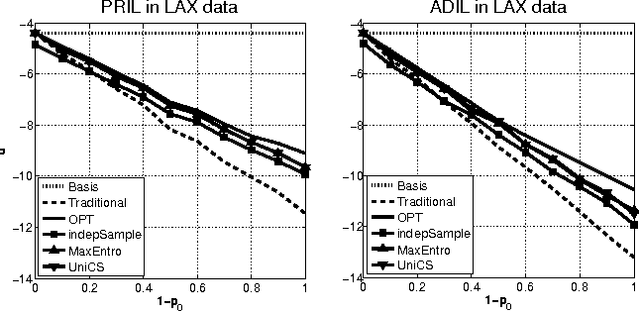
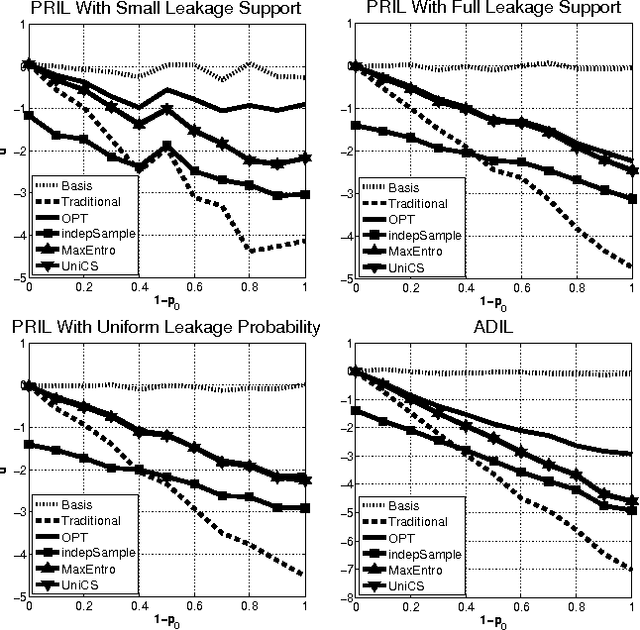
Most models of Stackelberg security games assume that the attacker only knows the defender's mixed strategy, but is not able to observe (even partially) the instantiated pure strategy. Such partial observation of the deployed pure strategy -- an issue we refer to as information leakage -- is a significant concern in practical applications. While previous research on patrolling games has considered the attacker's real-time surveillance, our settings, therefore models and techniques, are fundamentally different. More specifically, after describing the information leakage model, we start with an LP formulation to compute the defender's optimal strategy in the presence of leakage. Perhaps surprisingly, we show that a key subproblem to solve this LP (more precisely, the defender oracle) is NP-hard even for the simplest of security game models. We then approach the problem from three possible directions: efficient algorithms for restricted cases, approximation algorithms, and heuristic algorithms for sampling that improves upon the status quo. Our experiments confirm the necessity of handling information leakage and the advantage of our algorithms.