 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith Measured Words: Simple Sentence Selection for Black-Box Optimization of Sentence Compression Algorithms
Jan 25, 2021
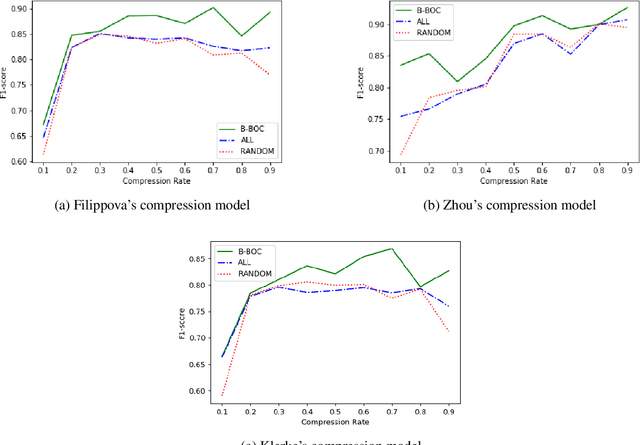
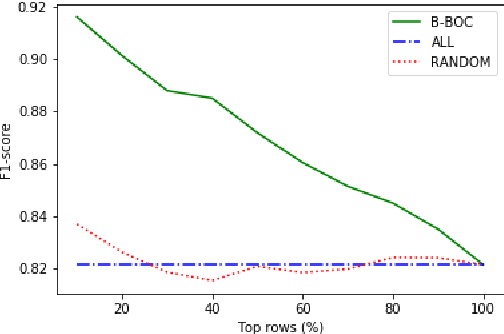
Sentence Compression is the task of generating a shorter, yet grammatical version of a given sentence, preserving the essence of the original sentence. This paper proposes a Black-Box Optimizer for Compression (B-BOC): given a black-box compression algorithm and assuming not all sentences need be compressed -- find the best candidates for compression in order to maximize both compression rate and quality. Given a required compression ratio, we consider two scenarios: (i) single-sentence compression, and (ii) sentences-sequence compression. In the first scenario, our optimizer is trained to predict how well each sentence could be compressed while meeting the specified ratio requirement. In the latter, the desired compression ratio is applied to a sequence of sentences (e.g., a paragraph) as a whole, rather than on each individual sentence. To achieve that, we use B-BOC to assign an optimal compression ratio to each sentence, then cast it as a Knapsack problem, which we solve using bounded dynamic programming. We evaluate B-BOC on both scenarios on three datasets, demonstrating that our optimizer improves both accuracy and Rouge-F1-score compared to direct application of other compression algorithms.
Autosploit: A Fully Automated Framework for Evaluating the Exploitability of Security Vulnerabilities
Jun 30, 2020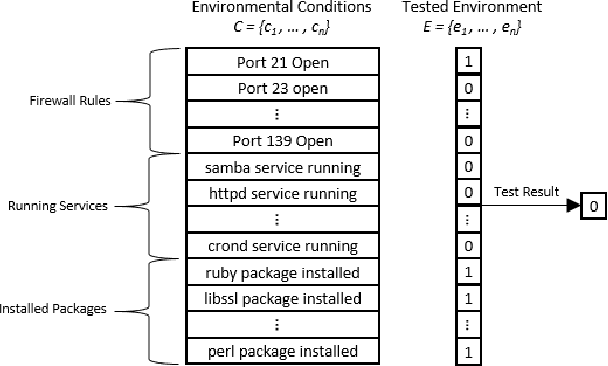
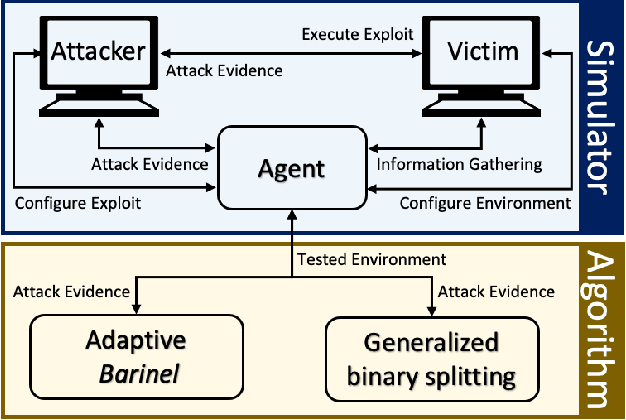
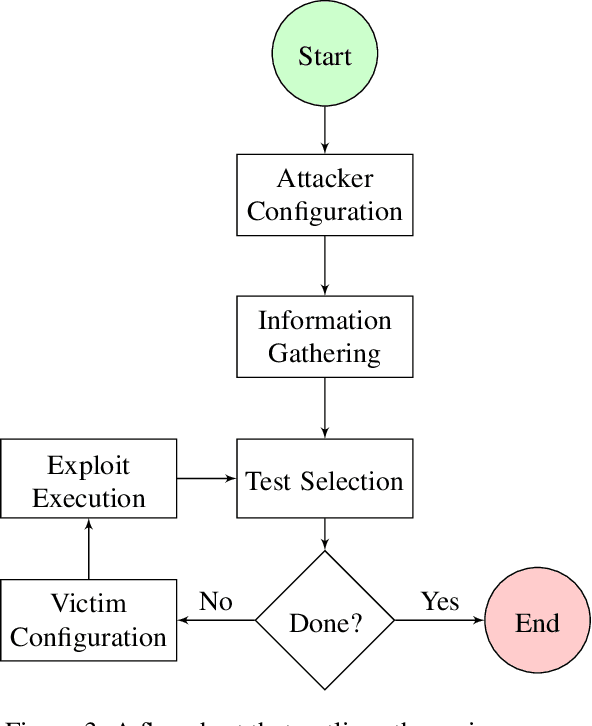
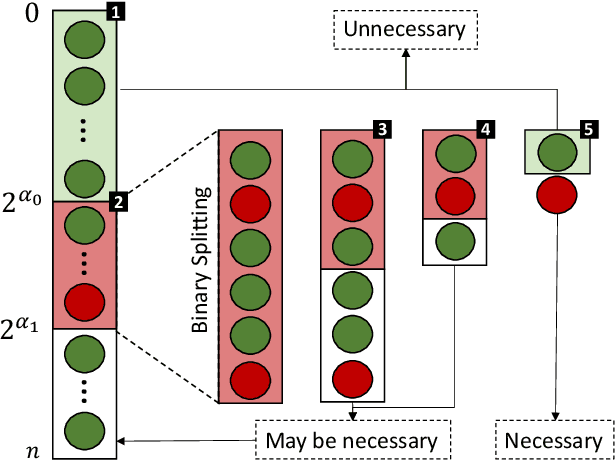
The existence of a security vulnerability in a system does not necessarily mean that it can be exploited. In this research, we introduce Autosploit -- an automated framework for evaluating the exploitability of vulnerabilities. Given a vulnerable environment and relevant exploits, Autosploit will automatically test the exploits on different configurations of the environment in order to identify the specific properties necessary for successful exploitation of the existing vulnerabilities. Since testing all possible system configurations is infeasible, we introduce an efficient approach for testing and searching through all possible configurations of the environment. The efficient testing process implemented by Autosploit is based on two algorithms: generalized binary splitting and Barinel, which are used for noiseless and noisy environments respectively. We implemented the proposed framework and evaluated it using real vulnerabilities. The results show that Autosploit is able to automatically identify the system properties that affect the ability to exploit a vulnerability in both noiseless and noisy environments. These important results can be utilized for more accurate and effective risk assessment.
Lie on the Fly: Strategic Voting in an Iterative Preference Elicitation Process
May 13, 2019
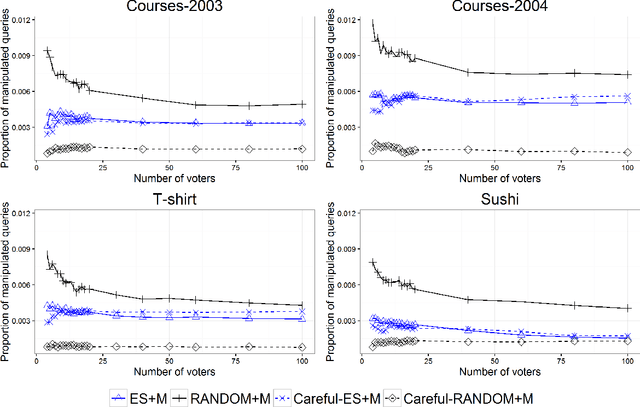
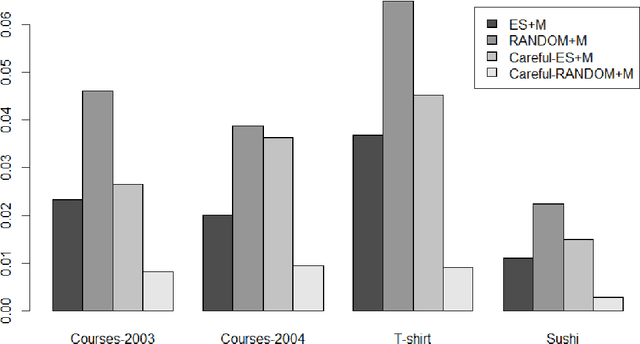
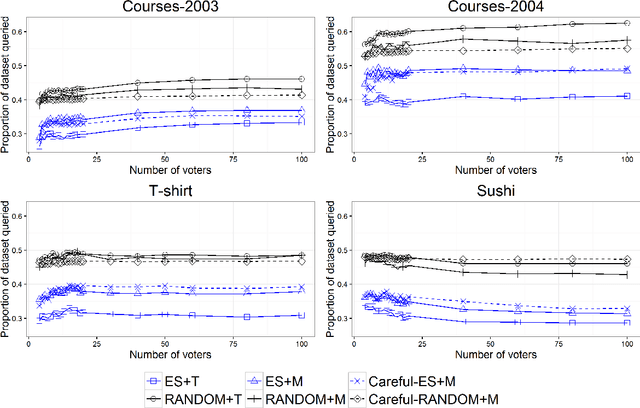
A voting center is in charge of collecting and aggregating voter preferences. In an iterative process, the center sends comparison queries to voters, requesting them to submit their preference between two items. Voters might discuss the candidates among themselves, figuring out during the elicitation process which candidates stand a chance of winning and which do not. Consequently, strategic voters might attempt to manipulate by deviating from their true preferences and instead submit a different response in order to attempt to maximize their profit. We provide a practical algorithm for strategic voters which computes the best manipulative vote and maximizes the voter's selfish outcome when such a vote exists. We also provide a careful voting center which is aware of the possible manipulations and avoids manipulative queries when possible. In an empirical study on four real-world domains, we show that in practice manipulation occurs in a low percentage of settings and has a low impact on the final outcome. The careful voting center reduces manipulation even further, thus allowing for a non-distorted group decision process to take place. We thus provide a core technology study of a voting process that can be adopted in opinion or information aggregation systems and in crowdsourcing applications, e.g., peer grading in Massive Open Online Courses (MOOCs).
Sequential Plan Recognition
Mar 03, 2017



Plan recognition algorithms infer agents' plans from their observed actions. Due to imperfect knowledge about the agent's behavior and the environment, it is often the case that there are multiple hypotheses about an agent's plans that are consistent with the observations, though only one of these hypotheses is correct. This paper addresses the problem of how to disambiguate between hypotheses, by querying the acting agent about whether a candidate plan in one of the hypotheses matches its intentions. This process is performed sequentially and used to update the set of possible hypotheses during the recognition process. The paper defines the sequential plan recognition process (SPRP), which seeks to reduce the number of hypotheses using a minimal number of queries. We propose a number of policies for the SPRP which use maximum likelihood and information gain to choose which plan to query. We show this approach works well in practice on two domains from the literature, significantly reducing the number of hypotheses using fewer queries than a baseline approach. Our results can inform the design of future plan recognition systems that interleave the recognition process with intelligent interventions of their users.