 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed course allocation with asymmetric friendships
Sep 18, 2023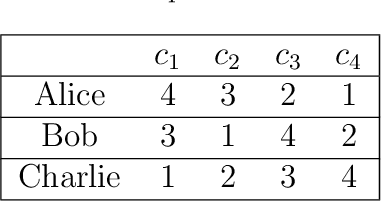

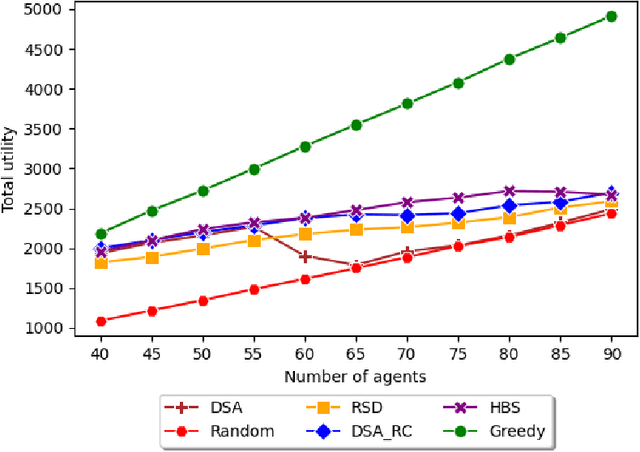
Students' decisions on whether to take a class are strongly affected by whether their friends plan to take the class with them. A student may prefer to be assigned to a course they likes less, just to be with their friends, rather than taking a more preferred class alone. It has been shown that taking classes with friends positively affects academic performance. Thus, academic institutes should prioritize friendship relations when assigning course seats. The introduction of friendship relations results in several non-trivial changes to current course allocation methods. This paper explores how course allocation mechanisms can account for friendships between students and provide a unique, distributed solution. In particular, we model the problem as an asymmetric distributed constraint optimization problem and develop a new dedicated algorithm. Our extensive evaluation includes both simulated data and data derived from a user study on 177 students' preferences over courses and friends. The results show that our algorithm obtains high utility for the students while keeping the solution fair and observing courses' seat capacity limitations.
Evaluation of Neural Networks Defenses and Attacks using NDCG and Reciprocal Rank Metrics
Jan 10, 2022
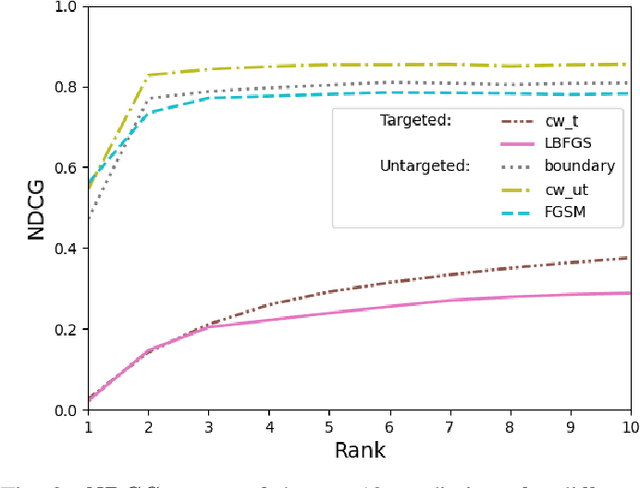
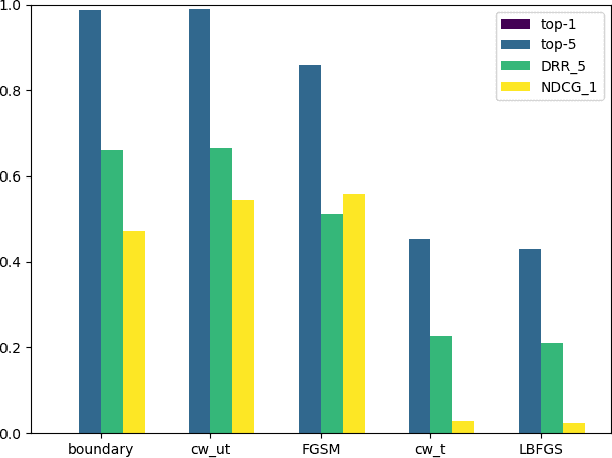
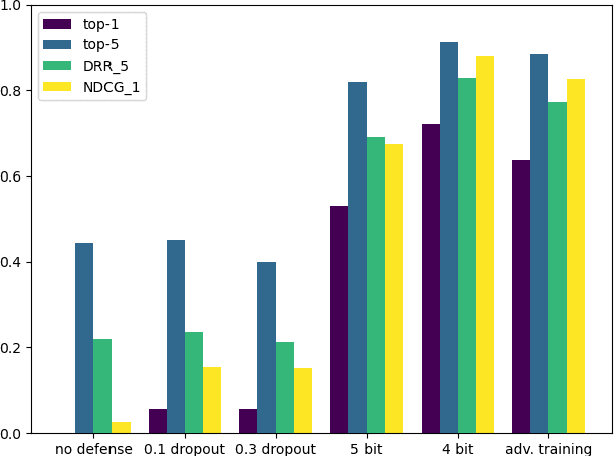
The problem of attacks on neural networks through input modification (i.e., adversarial examples) has attracted much attention recently. Being relatively easy to generate and hard to detect, these attacks pose a security breach that many suggested defenses try to mitigate. However, the evaluation of the effect of attacks and defenses commonly relies on traditional classification metrics, without adequate adaptation to adversarial scenarios. Most of these metrics are accuracy-based, and therefore may have a limited scope and low distinctive power. Other metrics do not consider the unique characteristics of neural networks functionality, or measure the effect of the attacks indirectly (e.g., through the complexity of their generation). In this paper, we present two metrics which are specifically designed to measure the effect of attacks, or the recovery effect of defenses, on the output of neural networks in multiclass classification tasks. Inspired by the normalized discounted cumulative gain and the reciprocal rank metrics used in information retrieval literature, we treat the neural network predictions as ranked lists of results. Using additional information about the probability of the rank enabled us to define novel metrics that are suited to the task at hand. We evaluate our metrics using various attacks and defenses on a pretrained VGG19 model and the ImageNet dataset. Compared to the common classification metrics, our proposed metrics demonstrate superior informativeness and distinctiveness.
Multi-label Ranking: Mining Multi-label and Label Ranking Data
Jan 03, 2021



We survey multi-label ranking tasks, specifically multi-label classification and label ranking classification. We highlight the unique challenges, and re-categorize the methods, as they no longer fit into the traditional categories of transformation and adaptation. We survey developments in the last demi-decade, with a special focus on state-of-the-art methods in deep learning multi-label mining, extreme multi-label classification and label ranking. We conclude by offering a few future research directions.
Improving Label Ranking Ensembles using Boosting Techniques
Jan 21, 2020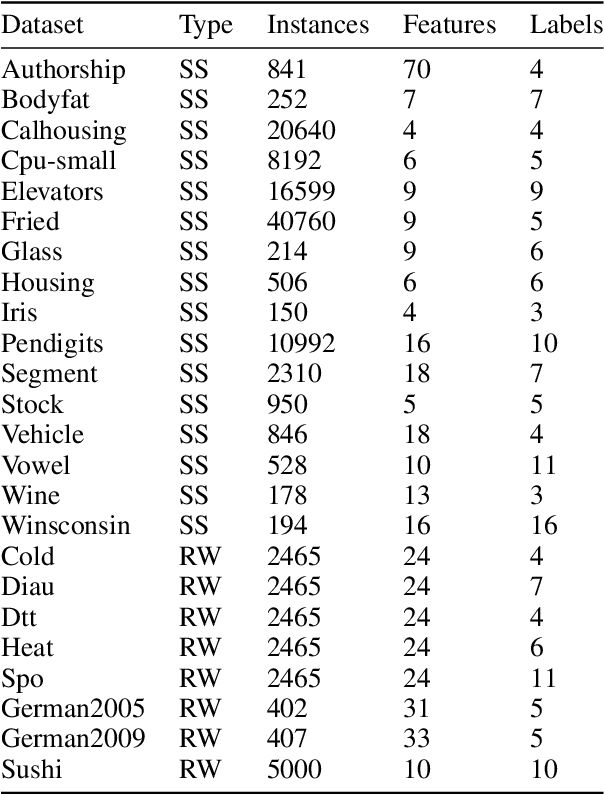
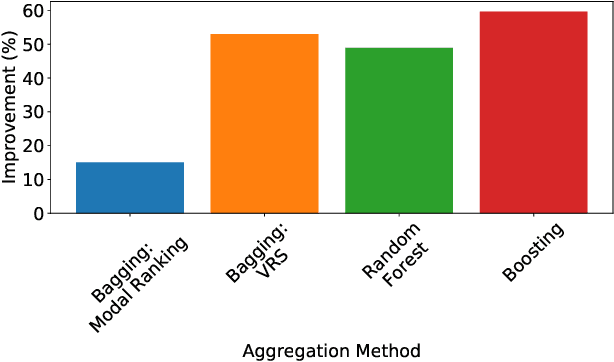
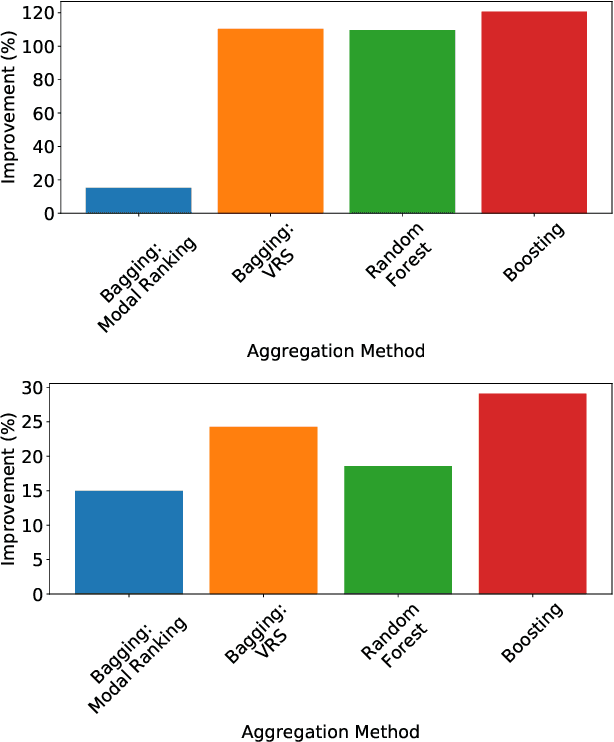

Label ranking is a prediction task which deals with learning a mapping between an instance and a ranking (i.e., order) of labels from a finite set, representing their relevance to the instance. Boosting is a well-known and reliable ensemble technique that was shown to often outperform other learning algorithms. While boosting algorithms were developed for a multitude of machine learning tasks, label ranking tasks were overlooked. In this paper, we propose a boosting algorithm which was specifically designed for label ranking tasks. Extensive evaluation of the proposed algorithm on 24 semi-synthetic and real-world label ranking datasets shows that it significantly outperforms existing state-of-the-art label ranking algorithms.
Lie on the Fly: Strategic Voting in an Iterative Preference Elicitation Process
May 13, 2019
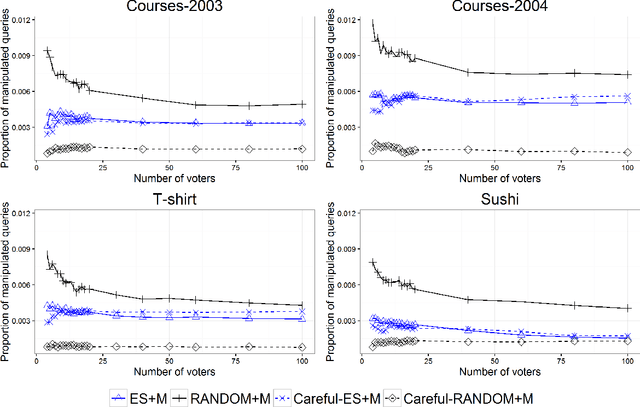
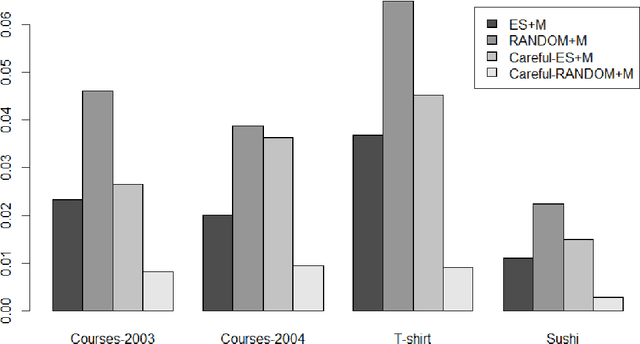
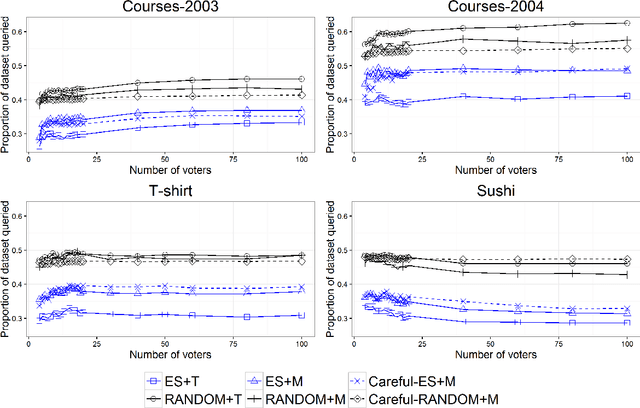
A voting center is in charge of collecting and aggregating voter preferences. In an iterative process, the center sends comparison queries to voters, requesting them to submit their preference between two items. Voters might discuss the candidates among themselves, figuring out during the elicitation process which candidates stand a chance of winning and which do not. Consequently, strategic voters might attempt to manipulate by deviating from their true preferences and instead submit a different response in order to attempt to maximize their profit. We provide a practical algorithm for strategic voters which computes the best manipulative vote and maximizes the voter's selfish outcome when such a vote exists. We also provide a careful voting center which is aware of the possible manipulations and avoids manipulative queries when possible. In an empirical study on four real-world domains, we show that in practice manipulation occurs in a low percentage of settings and has a low impact on the final outcome. The careful voting center reduces manipulation even further, thus allowing for a non-distorted group decision process to take place. We thus provide a core technology study of a voting process that can be adopted in opinion or information aggregation systems and in crowdsourcing applications, e.g., peer grading in Massive Open Online Courses (MOOCs).