 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorizing Items with Short and Noisy Descriptions using Ensembled Transferred Embeddings
Oct 21, 2021Item categorization is a machine learning task which aims at classifying e-commerce items, typically represented by textual attributes, to their most suitable category from a predefined set of categories. An accurate item categorization system is essential for improving both the user experience and the operational processes of the company. In this work, we focus on item categorization settings in which the textual attributes representing items are noisy and short, and labels (i.e., accurate classification of items into categories) are not available. In order to cope with such settings, we propose a novel learning framework, Ensembled Transferred Embeddings (ETE), which relies on two key ideas: 1) labeling a relatively small sample of the target dataset, in a semi-automatic process, and 2) leveraging other datasets from related domains or related tasks that are large-scale and labeled, to extract "transferable embeddings". Evaluation of ETE on a large-scale real-world dataset provided to us by PayPal, shows that it significantly outperforms traditional as well as state-of-the-art item categorization methods.
Fairness-Driven Private Collaborative Machine Learning
Sep 29, 2021



The performance of machine learning algorithms can be considerably improved when trained over larger datasets. In many domains, such as medicine and finance, larger datasets can be obtained if several parties, each having access to limited amounts of data, collaborate and share their data. However, such data sharing introduces significant privacy challenges. While multiple recent studies have investigated methods for private collaborative machine learning, the fairness of such collaborative algorithms was overlooked. In this work we suggest a feasible privacy-preserving pre-process mechanism for enhancing fairness of collaborative machine learning algorithms. Our experimentation with the proposed method shows that it is able to enhance fairness considerably with only a minor compromise in accuracy.
A Non-Parametric Subspace Analysis Approach with Application to Anomaly Detection Ensembles
Jan 13, 2021
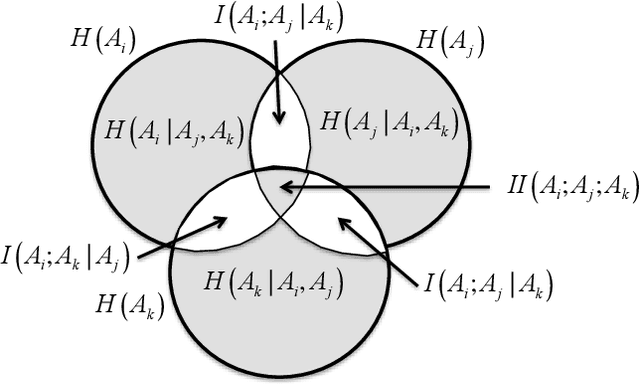

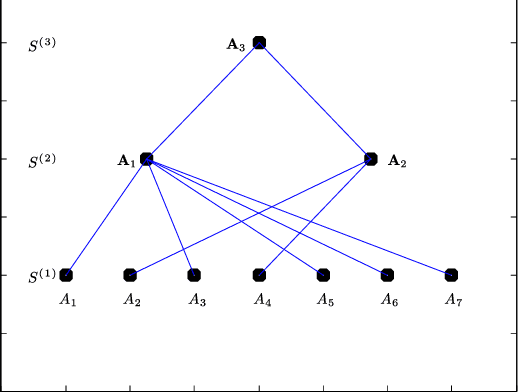
Identifying anomalies in multi-dimensional datasets is an important task in many real-world applications. A special case arises when anomalies are occluded in a small set of attributes, typically referred to as a subspace, and not necessarily over the entire data space. In this paper, we propose a new subspace analysis approach named Agglomerative Attribute Grouping (AAG) that aims to address this challenge by searching for subspaces that are comprised of highly correlative attributes. Such correlations among attributes represent a systematic interaction among the attributes that can better reflect the behavior of normal observations and hence can be used to improve the identification of two particularly interesting types of abnormal data samples: anomalies that are occluded in relatively small subsets of the attributes and anomalies that represent a new data class. AAG relies on a novel multi-attribute measure, which is derived from information theory measures of partitions, for evaluating the "information distance" between groups of data attributes. To determine the set of subspaces to use, AAG applies a variation of the well-known agglomerative clustering algorithm with the proposed multi-attribute measure as the underlying distance function. Finally, the set of subspaces is used in an ensemble for anomaly detection. Extensive evaluation demonstrates that, in the vast majority of cases, the proposed AAG method (i) outperforms classical and state-of-the-art subspace analysis methods when used in anomaly detection ensembles, and (ii) generates fewer subspaces with a fewer number of attributes each (on average), thus resulting in a faster training time for the anomaly detection ensemble. Furthermore, in contrast to existing methods, the proposed AAG method does not require any tuning of parameters.
Improving Label Ranking Ensembles using Boosting Techniques
Jan 21, 2020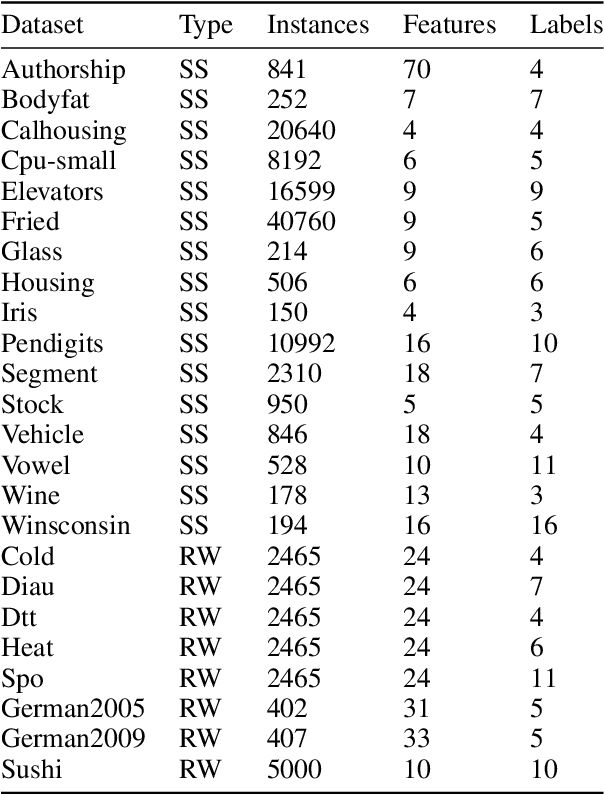
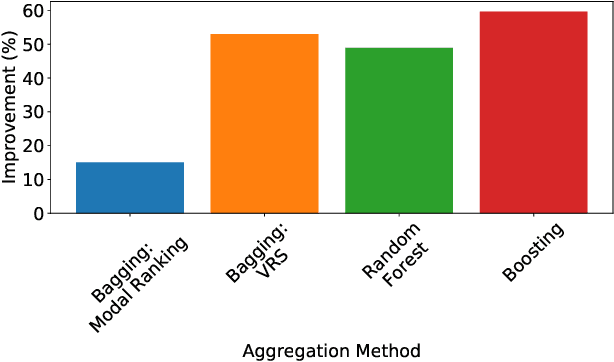
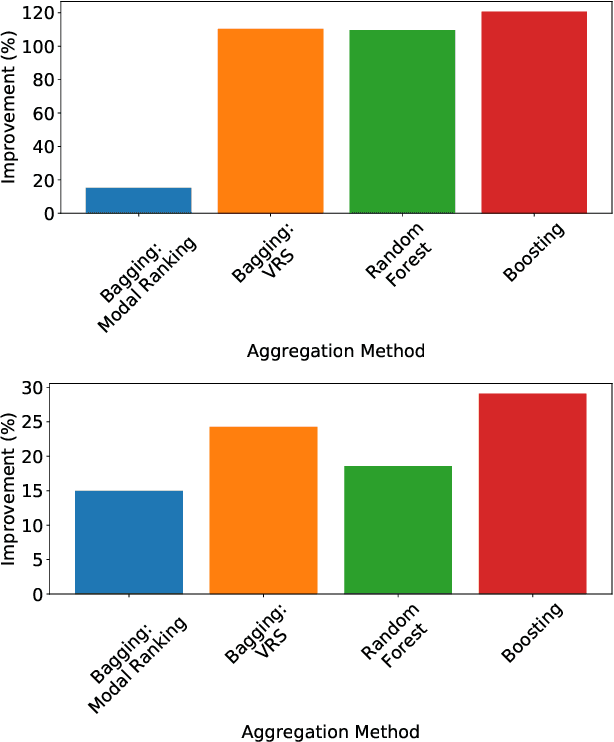

Label ranking is a prediction task which deals with learning a mapping between an instance and a ranking (i.e., order) of labels from a finite set, representing their relevance to the instance. Boosting is a well-known and reliable ensemble technique that was shown to often outperform other learning algorithms. While boosting algorithms were developed for a multitude of machine learning tasks, label ranking tasks were overlooked. In this paper, we propose a boosting algorithm which was specifically designed for label ranking tasks. Extensive evaluation of the proposed algorithm on 24 semi-synthetic and real-world label ranking datasets shows that it significantly outperforms existing state-of-the-art label ranking algorithms.
Algorithmic Fairness
Jan 21, 2020



An increasing number of decisions regarding the daily lives of human beings are being controlled by artificial intelligence (AI) algorithms in spheres ranging from healthcare, transportation, and education to college admissions, recruitment, provision of loans and many more realms. Since they now touch on many aspects of our lives, it is crucial to develop AI algorithms that are not only accurate but also objective and fair. Recent studies have shown that algorithmic decision-making may be inherently prone to unfairness, even when there is no intention for it. This paper presents an overview of the main concepts of identifying, measuring and improving algorithmic fairness when using AI algorithms. The paper begins by discussing the causes of algorithmic bias and unfairness and the common definitions and measures for fairness. Fairness-enhancing mechanisms are then reviewed and divided into pre-process, in-process and post-process mechanisms. A comprehensive comparison of the mechanisms is then conducted, towards a better understanding of which mechanisms should be used in different scenarios. The paper then describes the most commonly used fairness-related datasets in this field. Finally, the paper ends by reviewing several emerging research sub-fields of algorithmic fairness.
Handwritten Signature Verification Using Hand-Worn Devices
Dec 19, 2016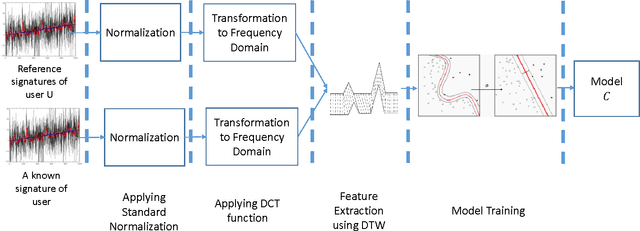
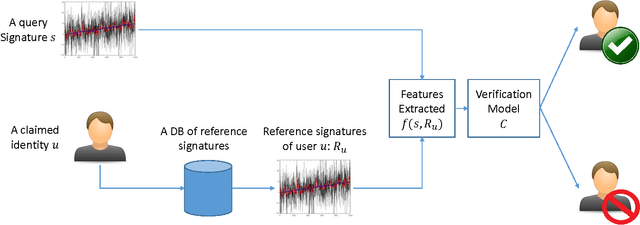
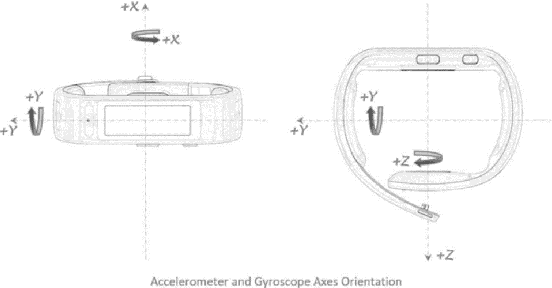
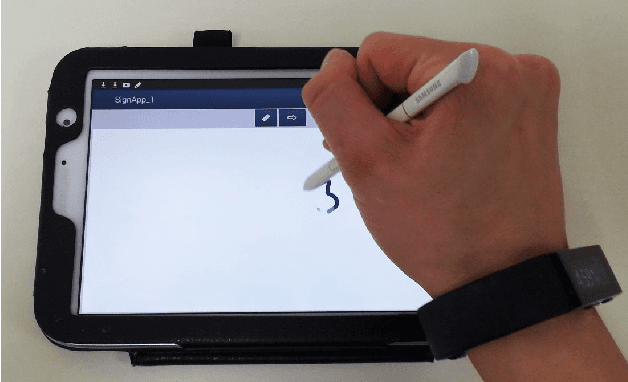
Online signature verification technologies, such as those available in banks and post offices, rely on dedicated digital devices such as tablets or smart pens to capture, analyze and verify signatures. In this paper, we suggest a novel method for online signature verification that relies on the increasingly available hand-worn devices, such as smartwatches or fitness trackers, instead of dedicated ad-hoc devices. Our method uses a set of known genuine and forged signatures, recorded using the motion sensors of a hand-worn device, to train a machine learning classifier. Then, given the recording of an unknown signature and a claimed identity, the classifier can determine whether the signature is genuine or forged. In order to validate our method, it was applied on 1980 recordings of genuine and forged signatures that we collected from 66 subjects in our institution. Using our method, we were able to successfully distinguish between genuine and forged signatures with a high degree of accuracy (0.98 AUC and 0.05 EER).
Human collective intelligence as distributed Bayesian inference
Aug 05, 2016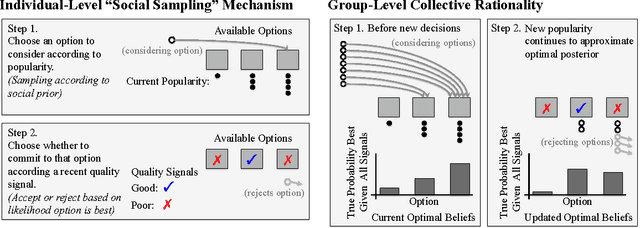
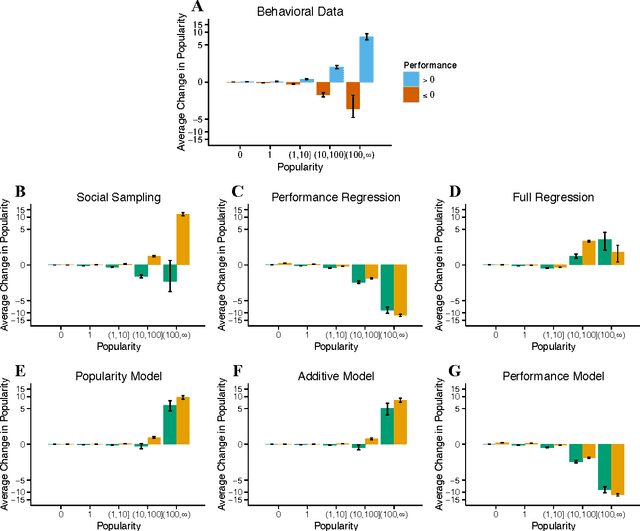
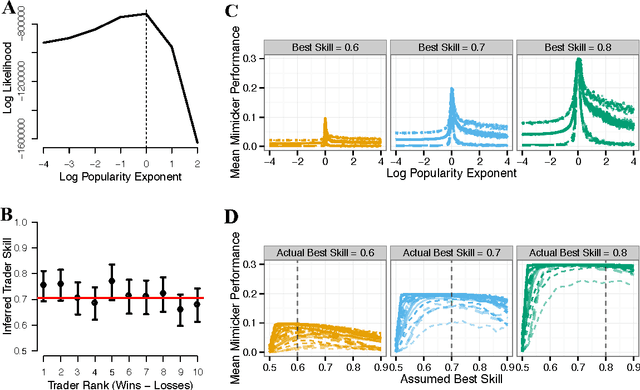
Collective intelligence is believed to underly the remarkable success of human society. The formation of accurate shared beliefs is one of the key components of human collective intelligence. How are accurate shared beliefs formed in groups of fallible individuals? Answering this question requires a multiscale analysis. We must understand both the individual decision mechanisms people use, and the properties and dynamics of those mechanisms in the aggregate. As of yet, mathematical tools for such an approach have been lacking. To address this gap, we introduce a new analytical framework: We propose that groups arrive at accurate shared beliefs via distributed Bayesian inference. Distributed inference occurs through information processing at the individual level, and yields rational belief formation at the group level. We instantiate this framework in a new model of human social decision-making, which we validate using a dataset we collected of over 50,000 users of an online social trading platform where investors mimic each others' trades using real money in foreign exchange and other asset markets. We find that in this setting people use a decision mechanism in which popularity is treated as a prior distribution for which decisions are best to make. This mechanism is boundedly rational at the individual level, but we prove that in the aggregate implements a type of approximate "Thompson sampling"---a well-known and highly effective single-agent Bayesian machine learning algorithm for sequential decision-making. The perspective of distributed Bayesian inference therefore reveals how collective rationality emerges from the boundedly rational decision mechanisms people use.