 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluencing Flock Formation in Low-Density Settings
Apr 23, 2018


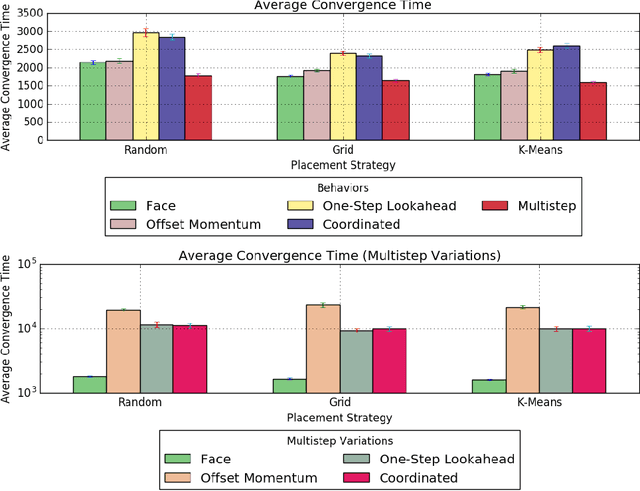
Flocking is a coordinated collective behavior that results from local sensing between individual agents that have a tendency to orient towards each other. Flocking is common among animal groups and might also be useful in robotic swarms. In the interest of learning how to control flocking behavior, recent work in the multiagent systems literature has explored the use of influencing agents for guiding flocking agents to face a target direction. The existing work in this domain has focused on simulation settings of small areas with toroidal shapes. In such settings, agent density is high, so interactions are common, and flock formation occurs easily. In our work, we study new environments with lower agent density, wherein interactions are more rare. We study the efficacy of placement strategies and influencing agent behaviors drawn from the literature, and find that the behaviors that have been shown to work well in high-density conditions tend to be much less effective in lower density environments. The source of this ineffectiveness is that the influencing agents explored in prior work tended to face directions optimized for maximal influence, but which actually separate the influencing agents from the flock. We find that in low-density conditions maintaining a connection to the flock is more important than rushing to orient towards the desired direction. We use these insights to propose new influencing agent behaviors, which we dub "follow-then-influence"; agents act like normal members of the flock to achieve positions that allow for control and then exert their influence. This strategy overcomes the difficulties posed by low density environments.
A Distributed Learning Dynamics in Social Groups
May 08, 2017We study a distributed learning process observed in human groups and other social animals. This learning process appears in settings in which each individual in a group is trying to decide over time, in a distributed manner, which option to select among a shared set of options. Specifically, we consider a stochastic dynamics in a group in which every individual selects an option in the following two-step process: (1) select a random individual and observe the option that individual chose in the previous time step, and (2) adopt that option if its stochastic quality was good at that time step. Various instantiations of such distributed learning appear in nature, and have also been studied in the social science literature. From the perspective of an individual, an attractive feature of this learning process is that it is a simple heuristic that requires extremely limited computational capacities. But what does it mean for the group -- could such a simple, distributed and essentially memoryless process lead the group as a whole to perform optimally? We show that the answer to this question is yes -- this distributed learning is highly effective at identifying the best option and is close to optimal for the group overall. Our analysis also gives quantitative bounds that show fast convergence of these stochastic dynamics. Prior to our work the only theoretical work related to such learning dynamics has been either in deterministic special cases or in the asymptotic setting. Finally, we observe that our infinite population dynamics is a stochastic variant of the classic multiplicative weights update (MWU) method. Consequently, we arrive at the following interesting converse: the learning dynamics on a finite population considered here can be viewed as a novel distributed and low-memory implementation of the classic MWU method.
Human collective intelligence as distributed Bayesian inference
Aug 05, 2016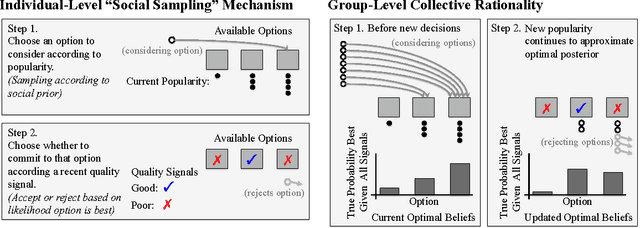
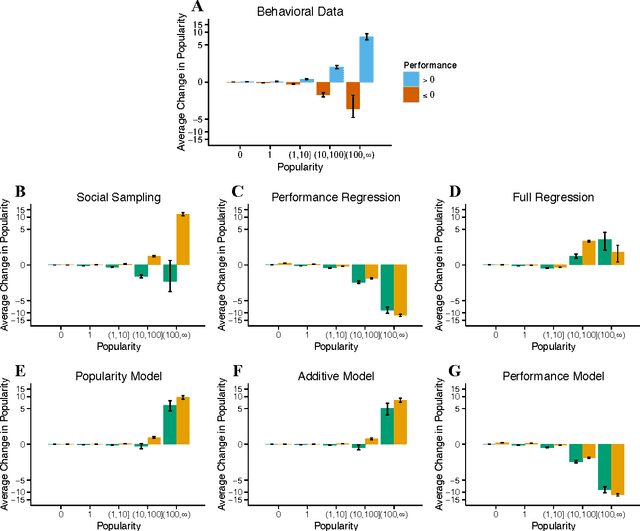
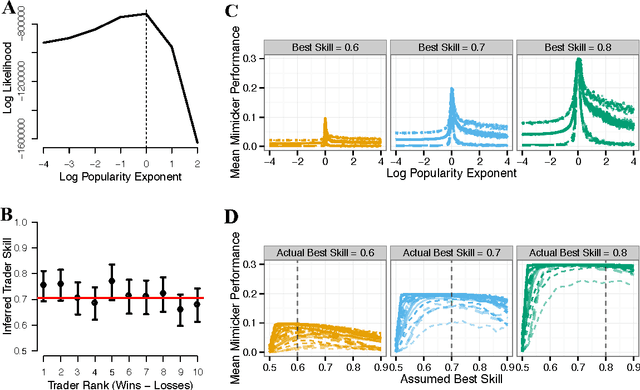
Collective intelligence is believed to underly the remarkable success of human society. The formation of accurate shared beliefs is one of the key components of human collective intelligence. How are accurate shared beliefs formed in groups of fallible individuals? Answering this question requires a multiscale analysis. We must understand both the individual decision mechanisms people use, and the properties and dynamics of those mechanisms in the aggregate. As of yet, mathematical tools for such an approach have been lacking. To address this gap, we introduce a new analytical framework: We propose that groups arrive at accurate shared beliefs via distributed Bayesian inference. Distributed inference occurs through information processing at the individual level, and yields rational belief formation at the group level. We instantiate this framework in a new model of human social decision-making, which we validate using a dataset we collected of over 50,000 users of an online social trading platform where investors mimic each others' trades using real money in foreign exchange and other asset markets. We find that in this setting people use a decision mechanism in which popularity is treated as a prior distribution for which decisions are best to make. This mechanism is boundedly rational at the individual level, but we prove that in the aggregate implements a type of approximate "Thompson sampling"---a well-known and highly effective single-agent Bayesian machine learning algorithm for sequential decision-making. The perspective of distributed Bayesian inference therefore reveals how collective rationality emerges from the boundedly rational decision mechanisms people use.
Sequential Voting Promotes Collective Discovery in Social Recommendation Systems
Mar 14, 2016



One goal of online social recommendation systems is to harness the wisdom of crowds in order to identify high quality content. Yet the sequential voting mechanisms that are commonly used by these systems are at odds with existing theoretical and empirical literature on optimal aggregation. This literature suggests that sequential voting will promote herding---the tendency for individuals to copy the decisions of others around them---and hence lead to suboptimal content recommendation. Is there a problem with our practice, or a problem with our theory? Previous attempts at answering this question have been limited by a lack of objective measurements of content quality. Quality is typically defined endogenously as the popularity of content in absence of social influence. The flaw of this metric is its presupposition that the preferences of the crowd are aligned with underlying quality. Domains in which content quality can be defined exogenously and measured objectively are thus needed in order to better assess the design choices of social recommendation systems. In this work, we look to the domain of education, where content quality can be measured via how well students are able to learn from the material presented to them. Through a behavioral experiment involving a simulated massive open online course (MOOC) run on Amazon Mechanical Turk, we show that sequential voting systems can surface better content than systems that elicit independent votes.
Modeling Human Ad Hoc Coordination
Feb 11, 2016

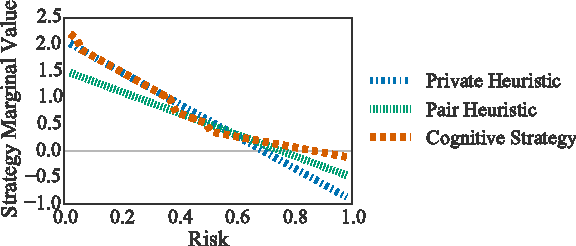
Whether in groups of humans or groups of computer agents, collaboration is most effective between individuals who have the ability to coordinate on a joint strategy for collective action. However, in general a rational actor will only intend to coordinate if that actor believes the other group members have the same intention. This circular dependence makes rational coordination difficult in uncertain environments if communication between actors is unreliable and no prior agreements have been made. An important normative question with regard to coordination in these ad hoc settings is therefore how one can come to believe that other actors will coordinate, and with regard to systems involving humans, an important empirical question is how humans arrive at these expectations. We introduce an exact algorithm for computing the infinitely recursive hierarchy of graded beliefs required for rational coordination in uncertain environments, and we introduce a novel mechanism for multiagent coordination that uses it. Our algorithm is valid in any environment with a finite state space, and extensions to certain countably infinite state spaces are likely possible. We test our mechanism for multiagent coordination as a model for human decisions in a simple coordination game using existing experimental data. We then explore via simulations whether modeling humans in this way may improve human-agent collaboration.