 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo No Harm: A Counterfactual Approach to Safe Reinforcement Learning
May 19, 2024



Reinforcement Learning (RL) for control has become increasingly popular due to its ability to learn rich feedback policies that take into account uncertainty and complex representations of the environment. When considering safety constraints, constrained optimization approaches, where agents are penalized for constraint violations, are commonly used. In such methods, if agents are initialized in, or must visit, states where constraint violation might be inevitable, it is unclear how much they should be penalized. We address this challenge by formulating a constraint on the counterfactual harm of the learned policy compared to a default, safe policy. In a philosophical sense this formulation only penalizes the learner for constraint violations that it caused; in a practical sense it maintains feasibility of the optimal control problem. We present simulation studies on a rover with uncertain road friction and a tractor-trailer parking environment that demonstrate our constraint formulation enables agents to learn safer policies than contemporary constrained RL methods.
Planning on a Budget: Safe Non-Conservative Planning in Probabilistic Dynamic Environments
Jun 16, 2021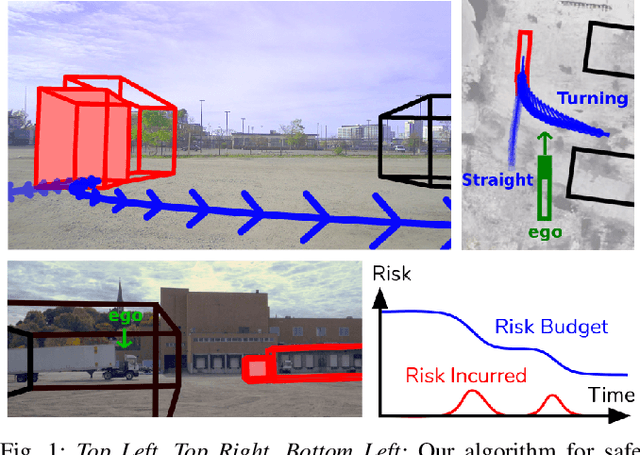
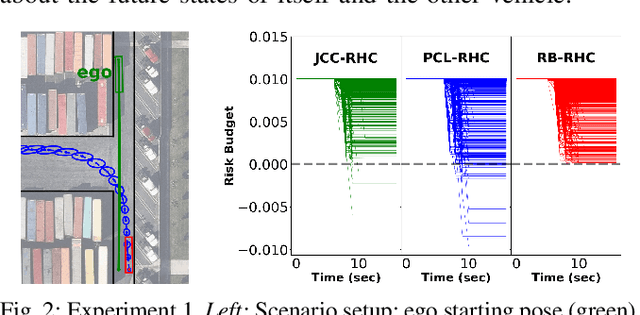
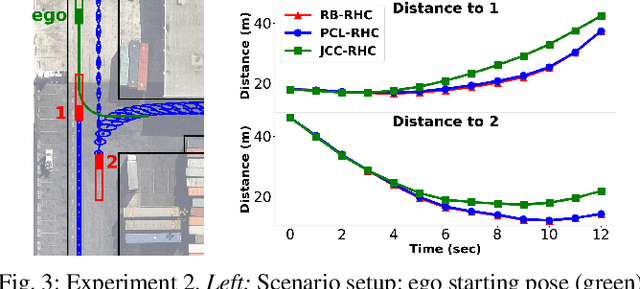
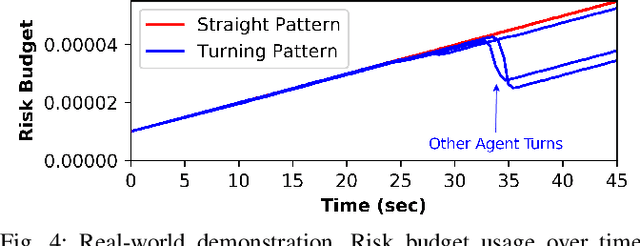
Planning in environments with other agents whose future actions are uncertain often requires compromise between safety and performance. Here our goal is to design efficient planning algorithms with guaranteed bounds on the probability of safety violation, which nonetheless achieve non-conservative performance. To quantify a system's risk, we define a natural criterion called interval risk bounds (IRBs), which provide a parametric upper bound on the probability of safety violation over a given time interval or task. We present a novel receding horizon algorithm, and prove that it can satisfy a desired IRB. Our algorithm maintains a dynamic risk budget which constrains the allowable risk at each iteration, and guarantees recursive feasibility by requiring a safe set to be reachable by a contingency plan within the budget. We empirically demonstrate that our algorithm is both safer and less conservative than strong baselines in two simulated autonomous driving experiments in scenarios involving collision avoidance with other vehicles, and additionally demonstrate our algorithm running on an autonomous class 8 truck.
PODDP: Partially Observable Differential Dynamic Programming for Latent Belief Space Planning
Dec 14, 2019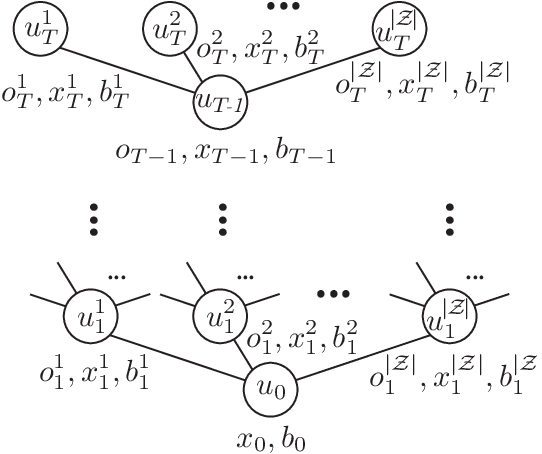
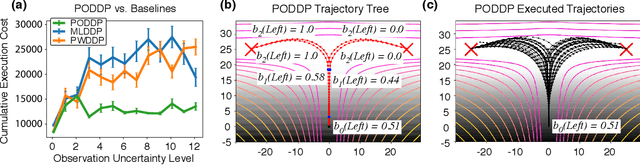
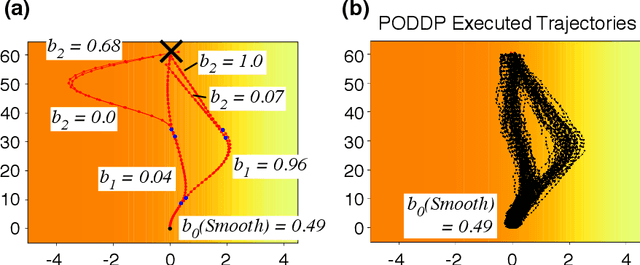
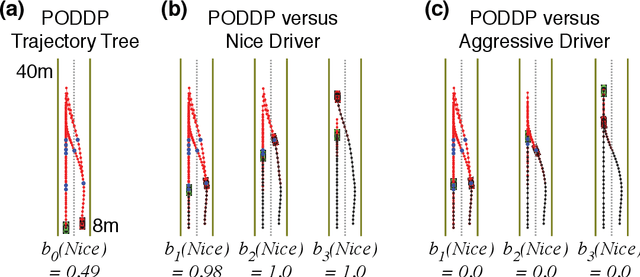
Autonomous agents are limited in their ability to observe the world state. Partially observable Markov decision processes (POMDPs) formally model the problem of planning under world state uncertainty, but POMDPs with continuous actions and nonlinear dynamics suitable for robotics applications are challenging to solve. In this paper, we present an efficient differential dynamic programming (DDP) algorithm for belief space planning in POMDPs with uncertainty over a discrete latent state, and continuous states, actions, observations, and nonlinear dynamics. This representation allows planning of dynamic trajectories which are sensitive to structured uncertainty over discrete latent world states. We develop dynamic programming techniques to optimize a contingency plan over a tree of possible observations and belief space trajectories, and also derive a hierarchical version of the algorithm. Our method is applicable to problems with uncertainty over the cost or reward function (e.g., the configuration of goals or obstacles), uncertainty over the dynamics (e.g., the dynamical mode of a hybrid system), and uncertainty about interactions, where other agents' behavior is conditioned on latent intentions. Benchmarks show that our algorithm outperforms popular heuristic approaches to planning under uncertainty, and results from an autonomous lane changing task demonstrate that our algorithm can synthesize robust interactive trajectories.
Modeling Human Ad Hoc Coordination
Feb 11, 2016

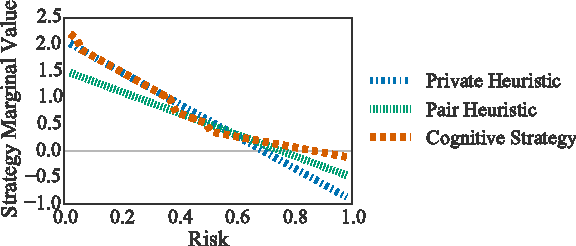
Whether in groups of humans or groups of computer agents, collaboration is most effective between individuals who have the ability to coordinate on a joint strategy for collective action. However, in general a rational actor will only intend to coordinate if that actor believes the other group members have the same intention. This circular dependence makes rational coordination difficult in uncertain environments if communication between actors is unreliable and no prior agreements have been made. An important normative question with regard to coordination in these ad hoc settings is therefore how one can come to believe that other actors will coordinate, and with regard to systems involving humans, an important empirical question is how humans arrive at these expectations. We introduce an exact algorithm for computing the infinitely recursive hierarchy of graded beliefs required for rational coordination in uncertain environments, and we introduce a novel mechanism for multiagent coordination that uses it. Our algorithm is valid in any environment with a finite state space, and extensions to certain countably infinite state spaces are likely possible. We test our mechanism for multiagent coordination as a model for human decisions in a simple coordination game using existing experimental data. We then explore via simulations whether modeling humans in this way may improve human-agent collaboration.
Modeling Human Understanding of Complex Intentional Action with a Bayesian Nonparametric Subgoal Model
Dec 03, 2015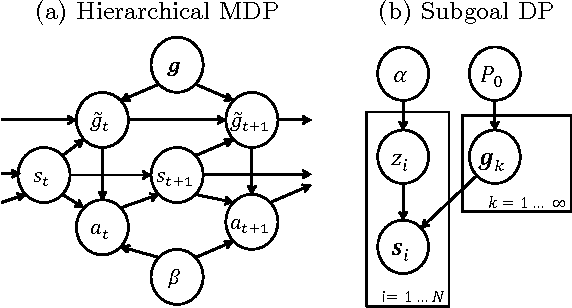

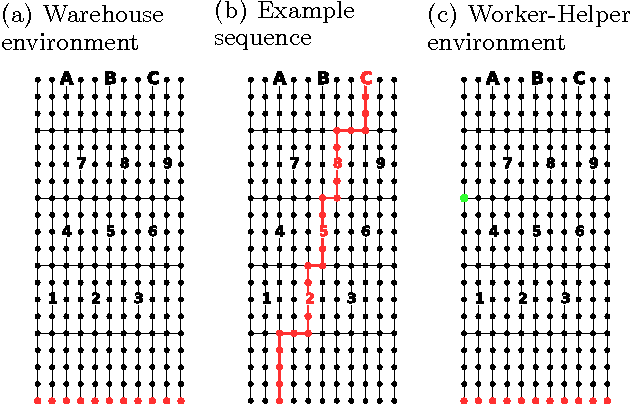
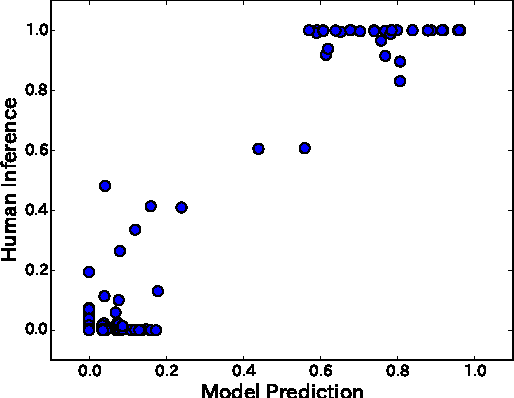
Most human behaviors consist of multiple parts, steps, or subtasks. These structures guide our action planning and execution, but when we observe others, the latent structure of their actions is typically unobservable, and must be inferred in order to learn new skills by demonstration, or to assist others in completing their tasks. For example, an assistant who has learned the subgoal structure of a colleague's task can more rapidly recognize and support their actions as they unfold. Here we model how humans infer subgoals from observations of complex action sequences using a nonparametric Bayesian model, which assumes that observed actions are generated by approximately rational planning over unknown subgoal sequences. We test this model with a behavioral experiment in which humans observed different series of goal-directed actions, and inferred both the number and composition of the subgoal sequences associated with each goal. The Bayesian model predicts human subgoal inferences with high accuracy, and significantly better than several alternative models and straightforward heuristics. Motivated by this result, we simulate how learning and inference of subgoals can improve performance in an artificial user assistance task. The Bayesian model learns the correct subgoals from fewer observations, and better assists users by more rapidly and accurately inferring the goal of their actions than alternative approaches.
* Accepted at AAAI 16