 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo No Harm: A Counterfactual Approach to Safe Reinforcement Learning
May 19, 2024



Reinforcement Learning (RL) for control has become increasingly popular due to its ability to learn rich feedback policies that take into account uncertainty and complex representations of the environment. When considering safety constraints, constrained optimization approaches, where agents are penalized for constraint violations, are commonly used. In such methods, if agents are initialized in, or must visit, states where constraint violation might be inevitable, it is unclear how much they should be penalized. We address this challenge by formulating a constraint on the counterfactual harm of the learned policy compared to a default, safe policy. In a philosophical sense this formulation only penalizes the learner for constraint violations that it caused; in a practical sense it maintains feasibility of the optimal control problem. We present simulation studies on a rover with uncertain road friction and a tractor-trailer parking environment that demonstrate our constraint formulation enables agents to learn safer policies than contemporary constrained RL methods.
Towards Provably Not-at-Fault Control of Autonomous Robots in Arbitrary Dynamic Environments
Feb 07, 2019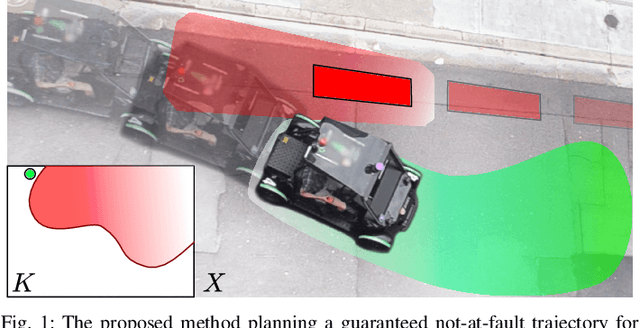

As autonomous robots increasingly become part of daily life, they will often encounter dynamic environments while only having limited information about their surroundings. Unfortunately, due to the possible presence of malicious dynamic actors, it is infeasible to develop an algorithm that can guarantee collision-free operation. Instead, one can attempt to design a control technique that guarantees the robot is not-at-fault in any collision. In the literature, making such guarantees in real time has been restricted to static environments or specific dynamic models. To ensure not-at-fault behavior, a robot must first correctly sense and predict the world around it within some sufficiently large sensor horizon (the prediction problem), then correctly control relative to the predictions (the control problem). This paper addresses the control problem by proposing Reachability-based Trajectory Design for Dynamic environments (RTD-D), which guarantees that a robot with an arbitrary nonlinear dynamic model correctly responds to predictions in arbitrary dynamic environments. RTD-D first computes a Forward Reachable Set (FRS) offline of the robot tracking parameterized desired trajectories that include fail-safe maneuvers. Then, for online receding-horizon planning, the method provides a way to discretize predictions of an arbitrary dynamic environment to enable real-time collision checking. The FRS is used to map these discretized predictions to trajectories that the robot can track while provably not-at-fault. One such trajectory is chosen at each iteration, or the robot executes the fail-safe maneuver from its previous trajectory which is guaranteed to be not at fault. RTD-D is shown to produce not-at-fault behavior over thousands of simulations and several real-world hardware demonstrations on two robots: a Segway, and a small electric vehicle.
Bridging the Gap Between Safety and Real-Time Performance in Receding-Horizon Trajectory Design for Mobile Robots
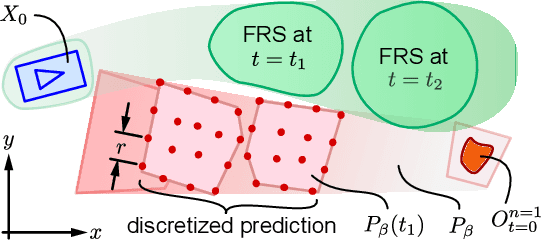
Sep 18, 2018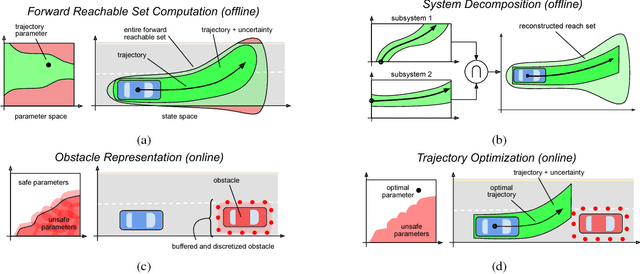
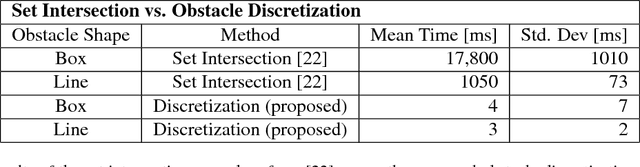

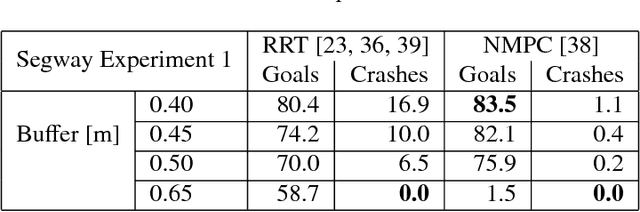
Autonomous mobile robots must operate with limited sensor horizons in unpredictable environments. To do so, they use a receding-horizon strategy to plan trajectories, by executing a short plan while creating the next plan. However, creating safe, dynamically-feasible trajectories in real time is challenging; and, planners must ensure that they are persistently feasible, meaning that a new trajectory is always available before the previous one has finished executing. Existing approaches make a tradeoff between model complexity and planning speed, which can require sacrificing guarantees of safety and dynamic feasibility. This work presents the Reachability-based Trajectory Design (RTD) method for trajectory planning. RTD begins with an offline Forward Reachable Set (FRS) computation of a robot's motion while it tracks parameterized trajectories; the FRS also provably bounds tracking error. At runtime, the FRS is used to map obstacles to the space of parameterized trajectories, which allows RTD to select a safe trajectory at every planning iteration. RTD prescribes a method of representing obstacles to ensure that these constraints can be created and evaluated in real time while maintaining provable safety. Persistent feasibility is achieved by prescribing a minimum duration of planned trajectories, and a minimum sensor horizon. A system decomposition approach is used to increase the dimension of the parameterized trajectories in the FRS, allowing for RTD to create more complex plans at runtime. RTD is compared in simulation with Rapidly-exploring Random Trees (RRT) and Nonlinear Model-Predictive Control (NMPC). RTD is also demonstrated on two hardware platforms in randomly-crafted environments: a differential-drive Segway, and a car-like Rover. The proposed method is shown as safe and persistently feasible across thousands of simulations and dozens of hardware demos.
Safe Trajectory Synthesis for Autonomous Driving in Unforeseen Environments
Apr 28, 2017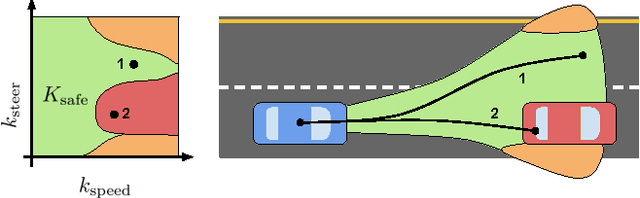
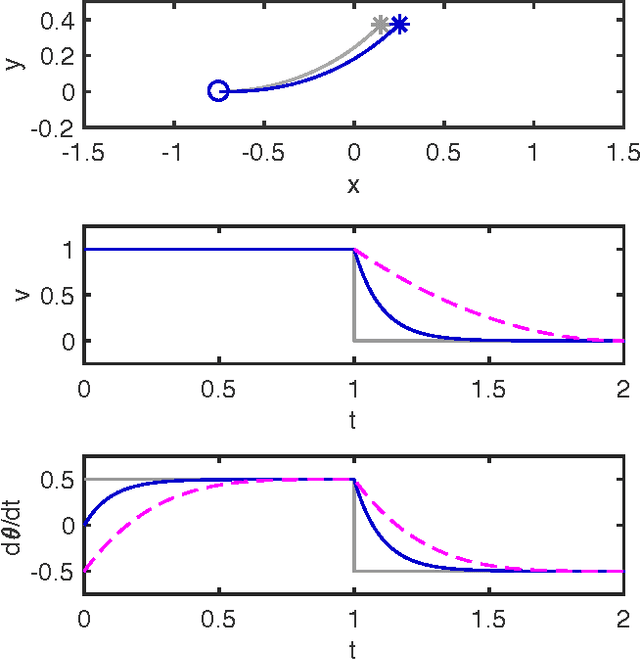
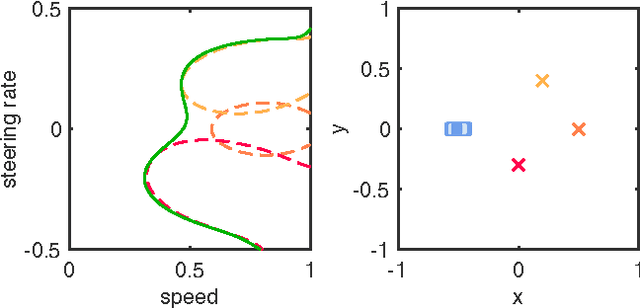
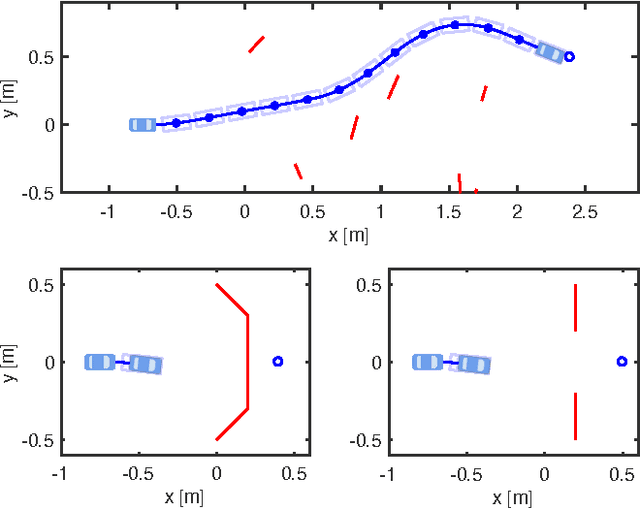
Path planning for autonomous vehicles in arbitrary environments requires a guarantee of safety, but this can be impractical to ensure in real-time when the vehicle is described with a high-fidelity model. To address this problem, this paper develops a method to perform trajectory design by considering a low-fidelity model that accounts for model mismatch. The presented method begins by computing a conservative Forward Reachable Set (FRS) of a high-fidelity model's trajectories produced when tracking trajectories of a low-fidelity model over a finite time horizon. At runtime, the vehicle intersects this FRS with obstacles in the environment to eliminate trajectories that can lead to a collision, then selects an optimal plan from the remaining safe set. By bounding the time for this set intersection and subsequent path selection, this paper proves a lower bound for the FRS time horizon and sensing horizon to guarantee safety. This method is demonstrated in simulation using a kinematic Dubin's car as the low-fidelity model and a dynamic unicycle as the high-fidelity model.