 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo No Harm: A Counterfactual Approach to Safe Reinforcement Learning
May 19, 2024



Reinforcement Learning (RL) for control has become increasingly popular due to its ability to learn rich feedback policies that take into account uncertainty and complex representations of the environment. When considering safety constraints, constrained optimization approaches, where agents are penalized for constraint violations, are commonly used. In such methods, if agents are initialized in, or must visit, states where constraint violation might be inevitable, it is unclear how much they should be penalized. We address this challenge by formulating a constraint on the counterfactual harm of the learned policy compared to a default, safe policy. In a philosophical sense this formulation only penalizes the learner for constraint violations that it caused; in a practical sense it maintains feasibility of the optimal control problem. We present simulation studies on a rover with uncertain road friction and a tractor-trailer parking environment that demonstrate our constraint formulation enables agents to learn safer policies than contemporary constrained RL methods.
Growing Q-Networks: Solving Continuous Control Tasks with Adaptive Control Resolution
Apr 05, 2024



Recent reinforcement learning approaches have shown surprisingly strong capabilities of bang-bang policies for solving continuous control benchmarks. The underlying coarse action space discretizations often yield favourable exploration characteristics while final performance does not visibly suffer in the absence of action penalization in line with optimal control theory. In robotics applications, smooth control signals are commonly preferred to reduce system wear and energy efficiency, but action costs can be detrimental to exploration during early training. In this work, we aim to bridge this performance gap by growing discrete action spaces from coarse to fine control resolution, taking advantage of recent results in decoupled Q-learning to scale our approach to high-dimensional action spaces up to dim(A) = 38. Our work indicates that an adaptive control resolution in combination with value decomposition yields simple critic-only algorithms that yield surprisingly strong performance on continuous control tasks.
OptFlow: Fast Optimization-based Scene Flow Estimation without Supervision
Jan 04, 2024



Scene flow estimation is a crucial component in the development of autonomous driving and 3D robotics, providing valuable information for environment perception and navigation. Despite the advantages of learning-based scene flow estimation techniques, their domain specificity and limited generalizability across varied scenarios pose challenges. In contrast, non-learning optimization-based methods, incorporating robust priors or regularization, offer competitive scene flow estimation performance, require no training, and show extensive applicability across datasets, but suffer from lengthy inference times. In this paper, we present OptFlow, a fast optimization-based scene flow estimation method. Without relying on learning or any labeled datasets, OptFlow achieves state-of-the-art performance for scene flow estimation on popular autonomous driving benchmarks. It integrates a local correlation weight matrix for correspondence matching, an adaptive correspondence threshold limit for nearest-neighbor search, and graph prior rigidity constraints, resulting in expedited convergence and improved point correspondence identification. Moreover, we demonstrate how integrating a point cloud registration function within our objective function bolsters accuracy and differentiates between static and dynamic points without relying on external odometry data. Consequently, OptFlow outperforms the baseline graph-prior method by approximately 20% and the Neural Scene Flow Prior method by 5%-7% in accuracy, all while offering the fastest inference time among all non-learning scene flow estimation methods.
Solving Continuous Control via Q-learning
Oct 22, 2022While there has been substantial success in applying actor-critic methods to continuous control, simpler critic-only methods such as Q-learning often remain intractable in the associated high-dimensional action spaces. However, most actor-critic methods come at the cost of added complexity: heuristics for stabilization, compute requirements as well as wider hyperparameter search spaces. We show that these issues can be largely alleviated via Q-learning by combining action discretization with value decomposition, framing single-agent control as cooperative multi-agent reinforcement learning (MARL). With bang-bang actions, performance of this critic-only approach matches state-of-the-art continuous actor-critic methods when learning from features or pixels. We extend classical bandit examples from cooperative MARL to provide intuition for how decoupled critics leverage state information to coordinate joint optimization, and demonstrate surprisingly strong performance across a wide variety of continuous control tasks.
Neighborhood Mixup Experience Replay: Local Convex Interpolation for Improved Sample Efficiency in Continuous Control Tasks
May 18, 2022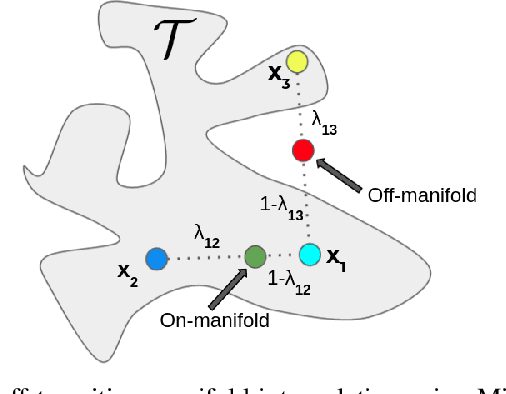
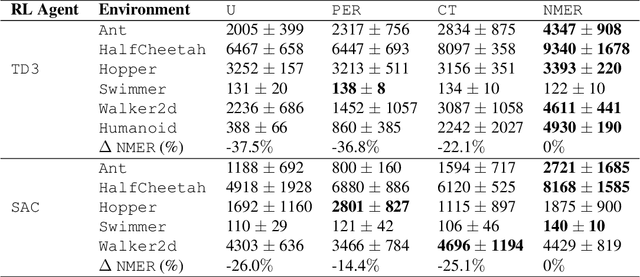
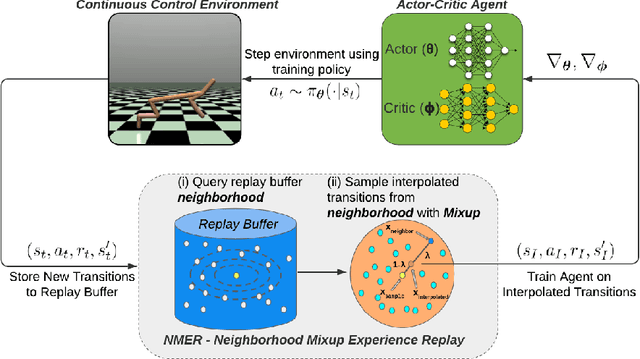

Experience replay plays a crucial role in improving the sample efficiency of deep reinforcement learning agents. Recent advances in experience replay propose using Mixup (Zhang et al., 2018) to further improve sample efficiency via synthetic sample generation. We build upon this technique with Neighborhood Mixup Experience Replay (NMER), a geometrically-grounded replay buffer that interpolates transitions with their closest neighbors in state-action space. NMER preserves a locally linear approximation of the transition manifold by only applying Mixup between transitions with vicinal state-action features. Under NMER, a given transition's set of state action neighbors is dynamic and episode agnostic, in turn encouraging greater policy generalizability via inter-episode interpolation. We combine our approach with recent off-policy deep reinforcement learning algorithms and evaluate on continuous control environments. We observe that NMER improves sample efficiency by an average 94% (TD3) and 29% (SAC) over baseline replay buffers, enabling agents to effectively recombine previous experiences and learn from limited data.
Deep Interactive Motion Prediction and Planning: Playing Games with Motion Prediction Models
Apr 05, 2022


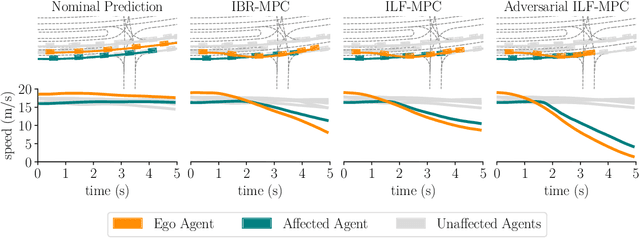
In most classical Autonomous Vehicle (AV) stacks, the prediction and planning layers are separated, limiting the planner to react to predictions that are not informed by the planned trajectory of the AV. This work presents a module that tightly couples these layers via a game-theoretic Model Predictive Controller (MPC) that uses a novel interactive multi-agent neural network policy as part of its predictive model. In our setting, the MPC planner considers all the surrounding agents by informing the multi-agent policy with the planned state sequence. Fundamental to the success of our method is the design of a novel multi-agent policy network that can steer a vehicle given the state of the surrounding agents and the map information. The policy network is trained implicitly with ground-truth observation data using backpropagation through time and a differentiable dynamics model to roll out the trajectory forward in time. Finally, we show that our multi-agent policy network learns to drive while interacting with the environment, and, when combined with the game-theoretic MPC planner, can successfully generate interactive behaviors.
Learning Interactive Driving Policies via Data-driven Simulation
Nov 23, 2021



Data-driven simulators promise high data-efficiency for driving policy learning. When used for modelling interactions, this data-efficiency becomes a bottleneck: Small underlying datasets often lack interesting and challenging edge cases for learning interactive driving. We address this challenge by proposing a simulation method that uses in-painted ado vehicles for learning robust driving policies. Thus, our approach can be used to learn policies that involve multi-agent interactions and allows for training via state-of-the-art policy learning methods. We evaluate the approach for learning standard interaction scenarios in driving. In extensive experiments, our work demonstrates that the resulting policies can be directly transferred to a full-scale autonomous vehicle without making use of any traditional sim-to-real transfer techniques such as domain randomization.
VISTA 2.0: An Open, Data-driven Simulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles
Nov 23, 2021



Simulation has the potential to transform the development of robust algorithms for mobile agents deployed in safety-critical scenarios. However, the poor photorealism and lack of diverse sensor modalities of existing simulation engines remain key hurdles towards realizing this potential. Here, we present VISTA, an open source, data-driven simulator that integrates multiple types of sensors for autonomous vehicles. Using high fidelity, real-world datasets, VISTA represents and simulates RGB cameras, 3D LiDAR, and event-based cameras, enabling the rapid generation of novel viewpoints in simulation and thereby enriching the data available for policy learning with corner cases that are difficult to capture in the physical world. Using VISTA, we demonstrate the ability to train and test perception-to-control policies across each of the sensor types and showcase the power of this approach via deployment on a full scale autonomous vehicle. The policies learned in VISTA exhibit sim-to-real transfer without modification and greater robustness than those trained exclusively on real-world data.
Is Bang-Bang Control All You Need? Solving Continuous Control with Bernoulli Policies
Nov 03, 2021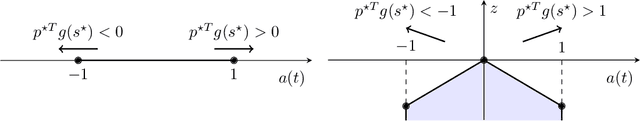


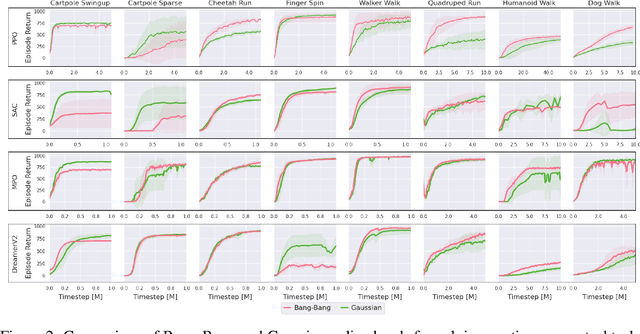
Reinforcement learning (RL) for continuous control typically employs distributions whose support covers the entire action space. In this work, we investigate the colloquially known phenomenon that trained agents often prefer actions at the boundaries of that space. We draw theoretical connections to the emergence of bang-bang behavior in optimal control, and provide extensive empirical evaluation across a variety of recent RL algorithms. We replace the normal Gaussian by a Bernoulli distribution that solely considers the extremes along each action dimension - a bang-bang controller. Surprisingly, this achieves state-of-the-art performance on several continuous control benchmarks - in contrast to robotic hardware, where energy and maintenance cost affect controller choices. Since exploration, learning,and the final solution are entangled in RL, we provide additional imitation learning experiments to reduce the impact of exploration on our analysis. Finally, we show that our observations generalize to environments that aim to model real-world challenges and evaluate factors to mitigate the emergence of bang-bang solutions. Our findings emphasize challenges for benchmarking continuous control algorithms, particularly in light of potential real-world applications.
Deep Latent Competition: Learning to Race Using Visual Control Policies in Latent Space
Feb 19, 2021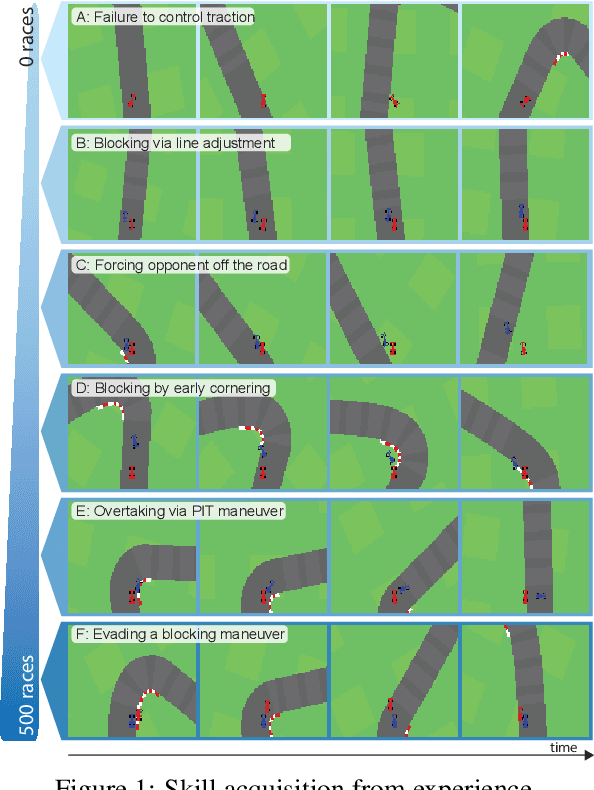
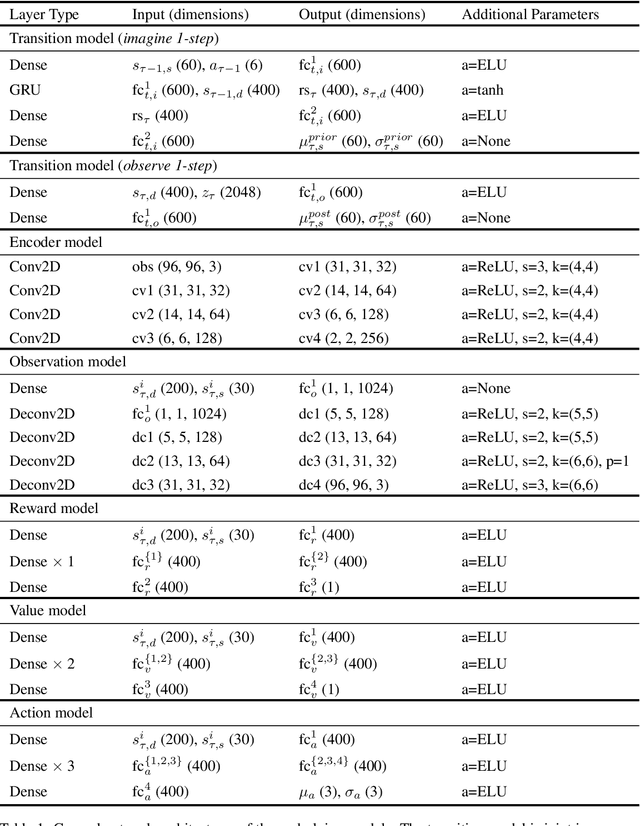
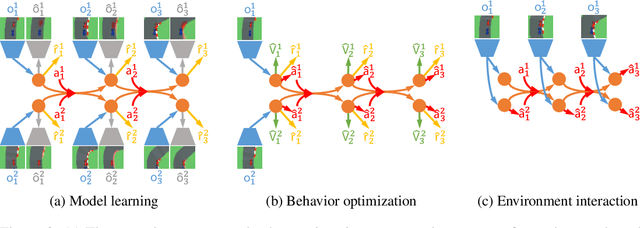
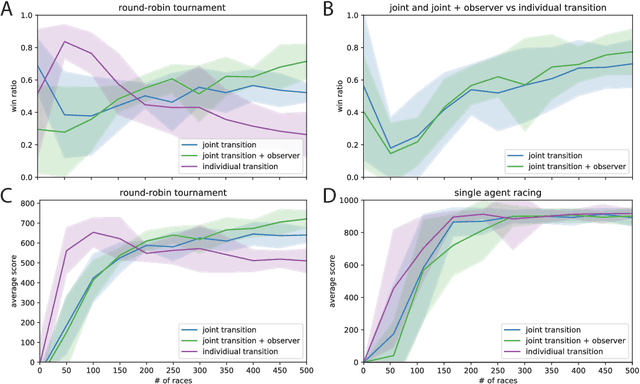
Learning competitive behaviors in multi-agent settings such as racing requires long-term reasoning about potential adversarial interactions. This paper presents Deep Latent Competition (DLC), a novel reinforcement learning algorithm that learns competitive visual control policies through self-play in imagination. The DLC agent imagines multi-agent interaction sequences in the compact latent space of a learned world model that combines a joint transition function with opponent viewpoint prediction. Imagined self-play reduces costly sample generation in the real world, while the latent representation enables planning to scale gracefully with observation dimensionality. We demonstrate the effectiveness of our algorithm in learning competitive behaviors on a novel multi-agent racing benchmark that requires planning from image observations. Code and videos available at https://sites.google.com/view/deep-latent-competition.