 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
End-to-End Sensitivity-Based Filter Pruning
Apr 15, 2022
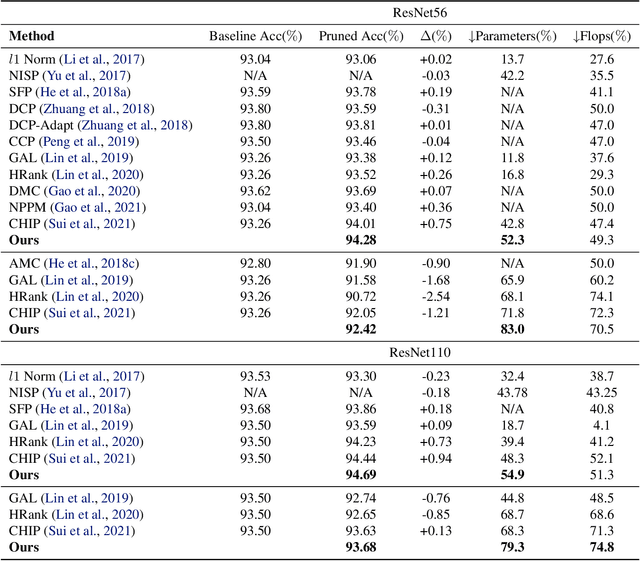


In this paper, we present a novel sensitivity-based filter pruning algorithm (SbF-Pruner) to learn the importance scores of filters of each layer end-to-end. Our method learns the scores from the filter weights, enabling it to account for the correlations between the filters of each layer. Moreover, by training the pruning scores of all layers simultaneously our method can account for layer interdependencies, which is essential to find a performant sparse sub-network. Our proposed method can train and generate a pruned network from scratch in a straightforward, one-stage training process without requiring a pretrained network. Ultimately, we do not need layer-specific hyperparameters and pre-defined layer budgets, since SbF-Pruner can implicitly determine the appropriate number of channels in each layer. Our experimental results on different network architectures suggest that SbF-Pruner outperforms advanced pruning methods. Notably, on CIFAR-10, without requiring a pretrained baseline network, we obtain 1.02% and 1.19% accuracy gain on ResNet56 and ResNet110, compared to the baseline reported for state-of-the-art pruning algorithms. This is while SbF-Pruner reduces parameter-count by 52.3% (for ResNet56) and 54% (for ResNet101), which is better than the state-of-the-art pruning algorithms with a high margin of 9.5% and 6.6%.
Compressing Neural Networks: Towards Determining the Optimal Layer-wise Decomposition
Jul 23, 2021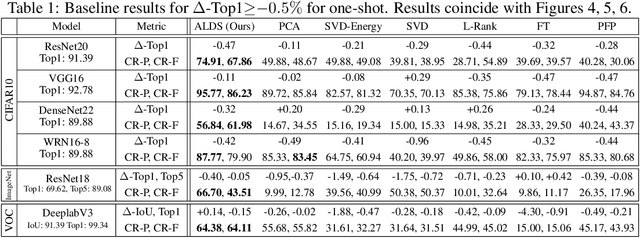
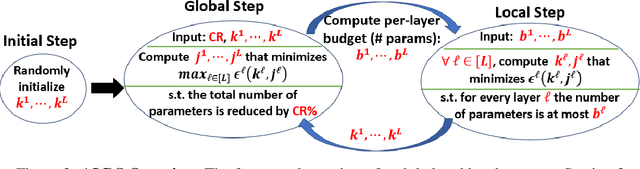
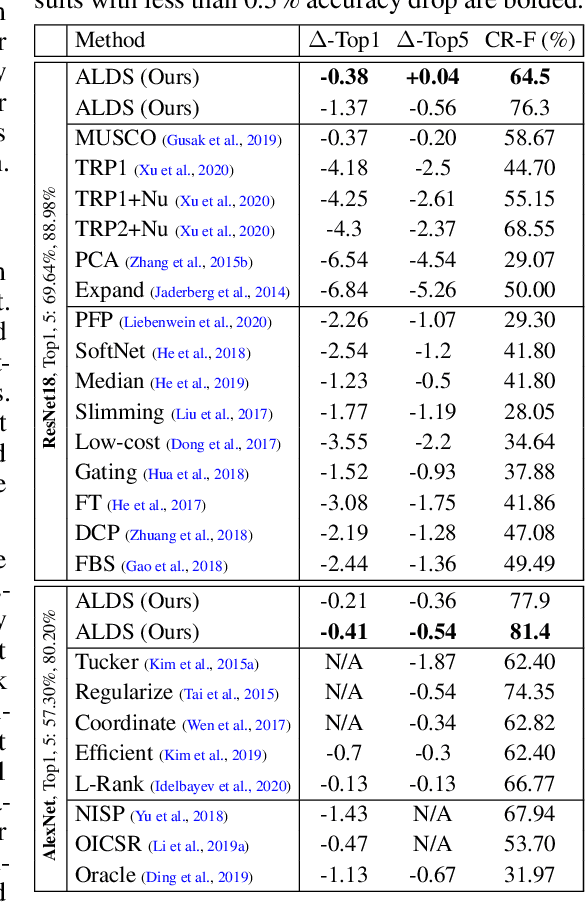
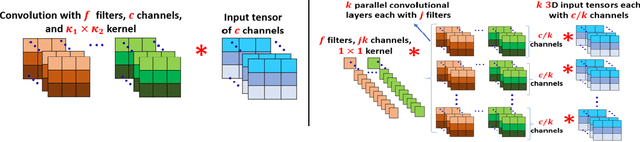
We present a novel global compression framework for deep neural networks that automatically analyzes each layer to identify the optimal per-layer compression ratio, while simultaneously achieving the desired overall compression. Our algorithm hinges on the idea of compressing each convolutional (or fully-connected) layer by slicing its channels into multiple groups and decomposing each group via low-rank decomposition. At the core of our algorithm is the derivation of layer-wise error bounds from the Eckart Young Mirsky theorem. We then leverage these bounds to frame the compression problem as an optimization problem where we wish to minimize the maximum compression error across layers and propose an efficient algorithm towards a solution. Our experiments indicate that our method outperforms existing low-rank compression approaches across a wide range of networks and data sets. We believe that our results open up new avenues for future research into the global performance-size trade-offs of modern neural networks. Our code is available at https://github.com/lucaslie/torchprune.
Closed-form Continuous-Depth Models
Jun 25, 2021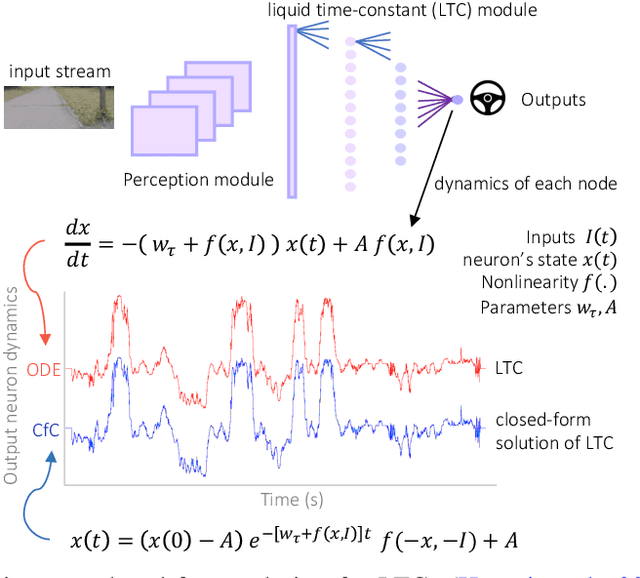
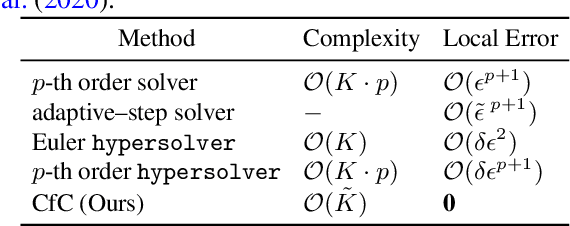
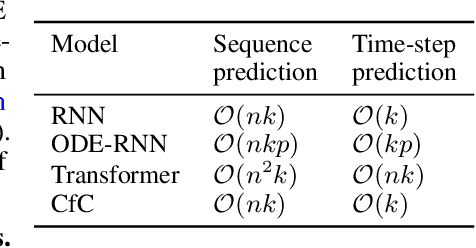
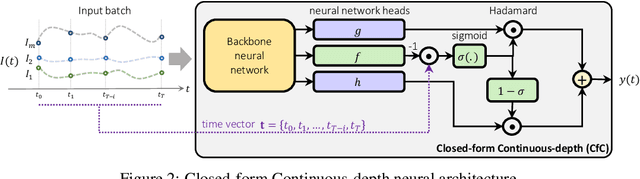
Continuous-depth neural models, where the derivative of the model's hidden state is defined by a neural network, have enabled strong sequential data processing capabilities. However, these models rely on advanced numerical differential equation (DE) solvers resulting in a significant overhead both in terms of computational cost and model complexity. In this paper, we present a new family of models, termed Closed-form Continuous-depth (CfC) networks, that are simple to describe and at least one order of magnitude faster while exhibiting equally strong modeling abilities compared to their ODE-based counterparts. The models are hereby derived from the analytical closed-form solution of an expressive subset of time-continuous models, thus alleviating the need for complex DE solvers all together. In our experimental evaluations, we demonstrate that CfC networks outperform advanced, recurrent models over a diverse set of time-series prediction tasks, including those with long-term dependencies and irregularly sampled data. We believe our findings open new opportunities to train and deploy rich, continuous neural models in resource-constrained settings, which demand both performance and efficiency.
Sparse Flows: Pruning Continuous-depth Models
Jun 24, 2021
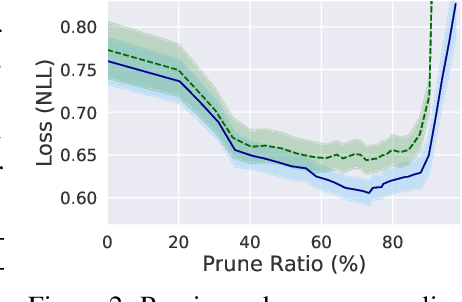
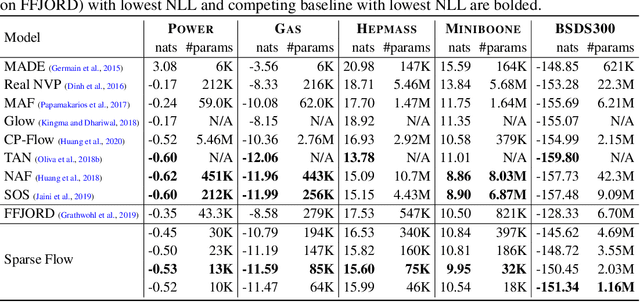
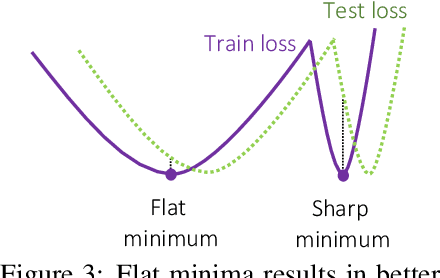
Continuous deep learning architectures enable learning of flexible probabilistic models for predictive modeling as neural ordinary differential equations (ODEs), and for generative modeling as continuous normalizing flows. In this work, we design a framework to decipher the internal dynamics of these continuous depth models by pruning their network architectures. Our empirical results suggest that pruning improves generalization for neural ODEs in generative modeling. Moreover, pruning finds minimal and efficient neural ODE representations with up to 98\% less parameters compared to the original network, without loss of accuracy. Finally, we show that by applying pruning we can obtain insightful information about the design of better neural ODEs.We hope our results will invigorate further research into the performance-size trade-offs of modern continuous-depth models.
Low-Regret Active learning
Apr 06, 2021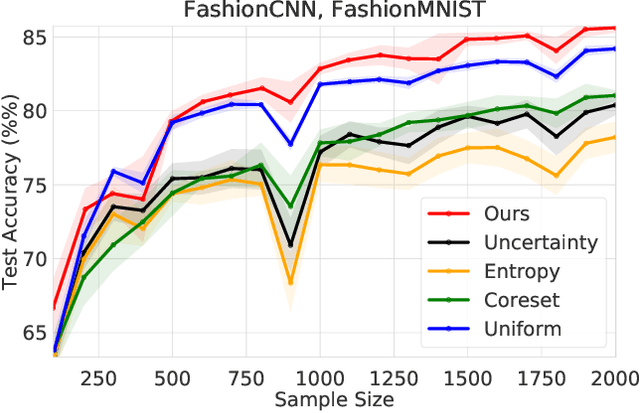

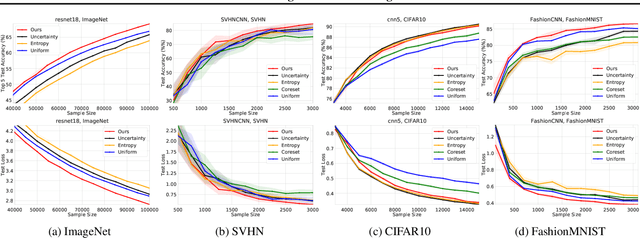

We develop an online learning algorithm for identifying unlabeled data points that are most informative for training (i.e., active learning). By formulating the active learning problem as the prediction with sleeping experts problem, we provide a framework for identifying informative data with respect to any given definition of informativeness. At the core of our work is an efficient algorithm for sleeping experts that is tailored to achieve low regret on predictable (easy) instances while remaining resilient to adversarial ones. This stands in contrast to state-of-the-art active learning methods that are overwhelmingly based on greedy selection, and hence cannot ensure good performance across varying problem instances. We present empirical results demonstrating that our method (i) instantiated with an informativeness measure consistently outperforms its greedy counterpart and (ii) reliably outperforms uniform sampling on real-world data sets and models.
Lost in Pruning: The Effects of Pruning Neural Networks beyond Test Accuracy
Mar 04, 2021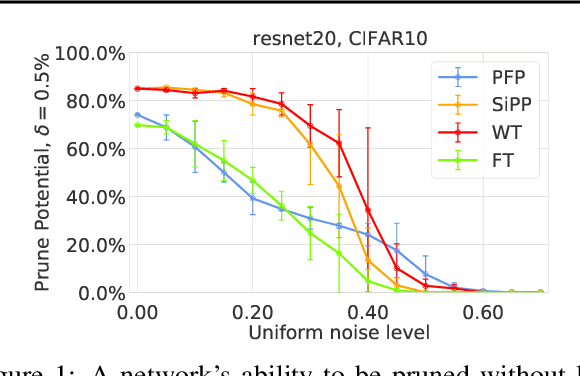

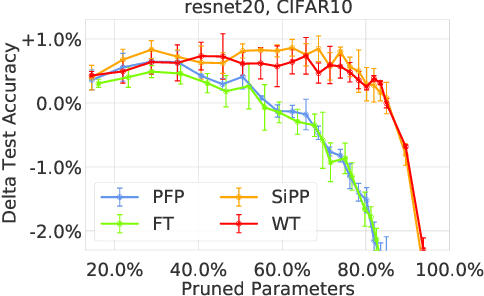
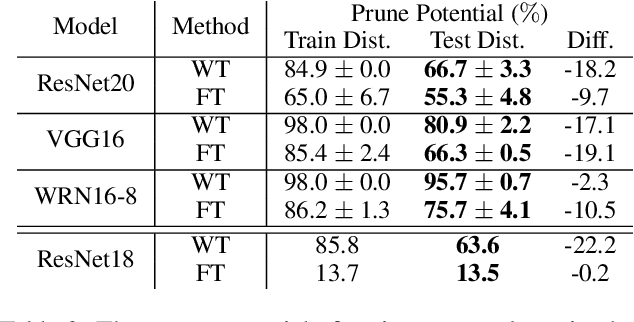
Neural network pruning is a popular technique used to reduce the inference costs of modern, potentially overparameterized, networks. Starting from a pre-trained network, the process is as follows: remove redundant parameters, retrain, and repeat while maintaining the same test accuracy. The result is a model that is a fraction of the size of the original with comparable predictive performance (test accuracy). Here, we reassess and evaluate whether the use of test accuracy alone in the terminating condition is sufficient to ensure that the resulting model performs well across a wide spectrum of "harder" metrics such as generalization to out-of-distribution data and resilience to noise. Across evaluations on varying architectures and data sets, we find that pruned networks effectively approximate the unpruned model, however, the prune ratio at which pruned networks achieve commensurate performance varies significantly across tasks. These results call into question the extent of \emph{genuine} overparameterization in deep learning and raise concerns about the practicability of deploying pruned networks, specifically in the context of safety-critical systems, unless they are widely evaluated beyond test accuracy to reliably predict their performance. Our code is available at https://github.com/lucaslie/torchprune.
Deep Latent Competition: Learning to Race Using Visual Control Policies in Latent Space
Feb 19, 2021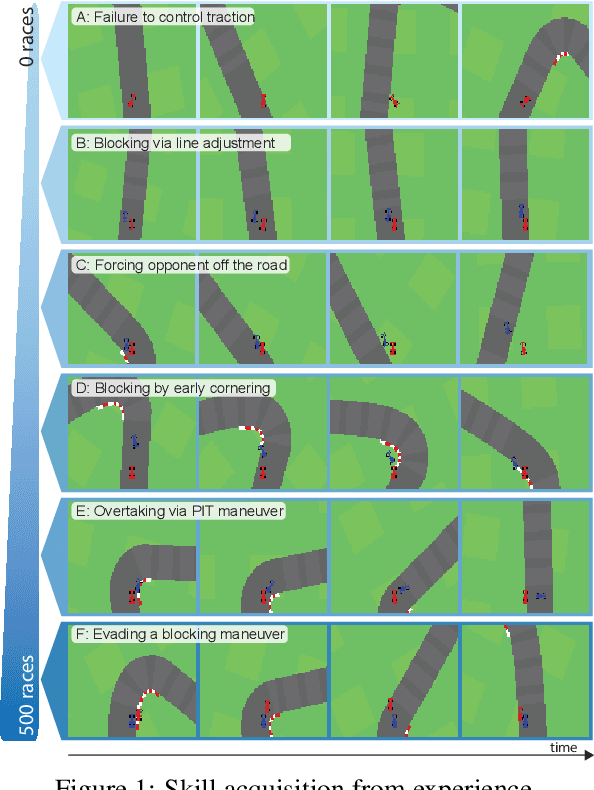
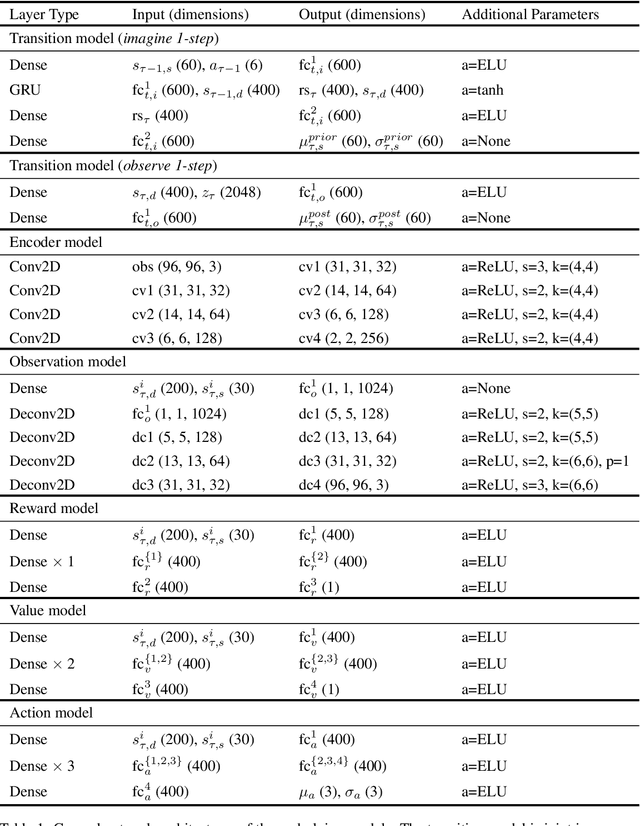
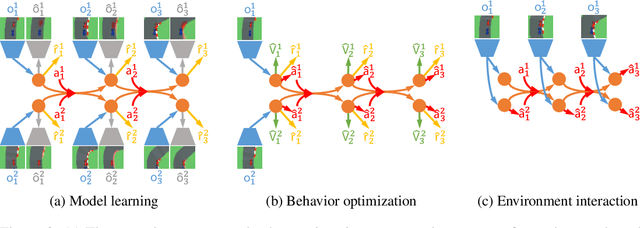
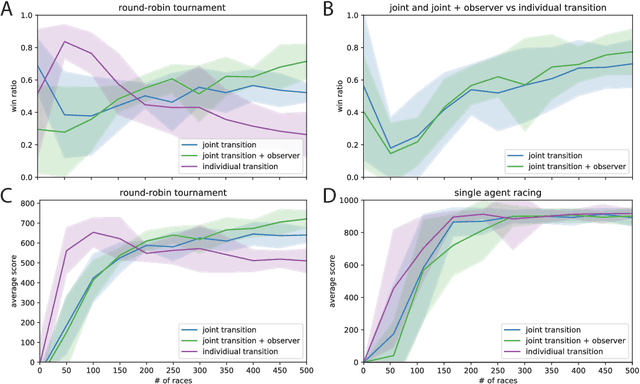
Learning competitive behaviors in multi-agent settings such as racing requires long-term reasoning about potential adversarial interactions. This paper presents Deep Latent Competition (DLC), a novel reinforcement learning algorithm that learns competitive visual control policies through self-play in imagination. The DLC agent imagines multi-agent interaction sequences in the compact latent space of a learned world model that combines a joint transition function with opponent viewpoint prediction. Imagined self-play reduces costly sample generation in the real world, while the latent representation enables planning to scale gracefully with observation dimensionality. We demonstrate the effectiveness of our algorithm in learning competitive behaviors on a novel multi-agent racing benchmark that requires planning from image observations. Code and videos available at https://sites.google.com/view/deep-latent-competition.
Machine Learning-based Estimation of Forest Carbon Stocks to increase Transparency of Forest Preservation Efforts
Dec 17, 2019

An increasing amount of companies and cities plan to become CO2-neutral, which requires them to invest in renewable energies and carbon emission offsetting solutions. One of the cheapest carbon offsetting solutions is preventing deforestation in developing nations, a major contributor in global greenhouse gas emissions. However, forest preservation projects historically display an issue of trust and transparency, which drives companies to invest in transparent, but expensive air carbon capture facilities. Preservation projects could conduct accurate forest inventories (tree diameter, species, height etc.) to transparently estimate the biomass and amount of stored carbon. However, current rainforest inventories are too inaccurate, because they are often based on a few expensive ground-based samples and/or low-resolution satellite imagery. LiDAR-based solutions, used in US forests, are accurate, but cost-prohibitive, and hardly-accessible in the Amazon rainforest. We propose accurate and cheap forest inventory analyses through Deep Learning-based processing of drone imagery. The more transparent estimation of stored carbon will create higher transparency towards clients and thereby increase trust and investment into forest preservation projects.