 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiPPing Neural Networks: Sensitivity-informed Provable Pruning of Neural Networks
Paper and Code
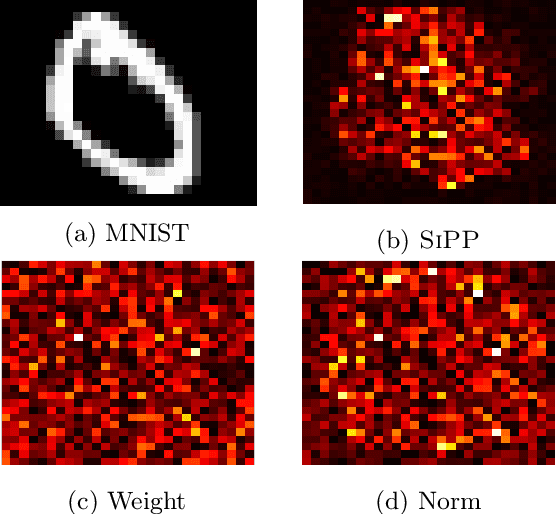
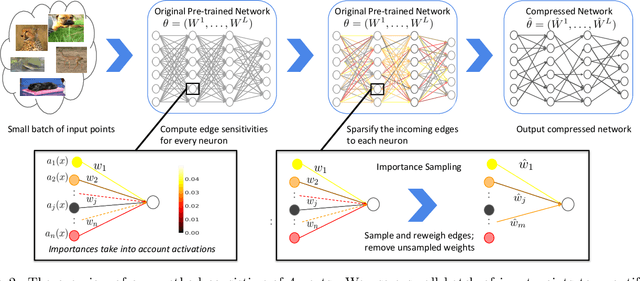
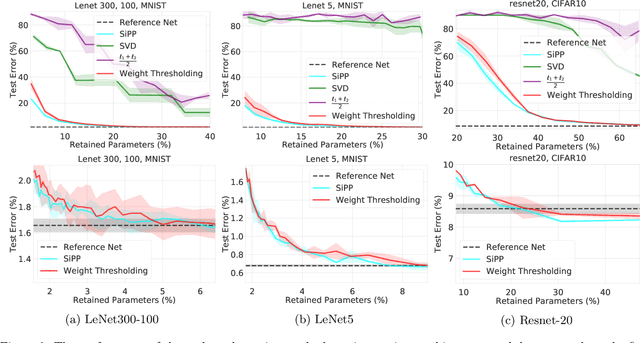
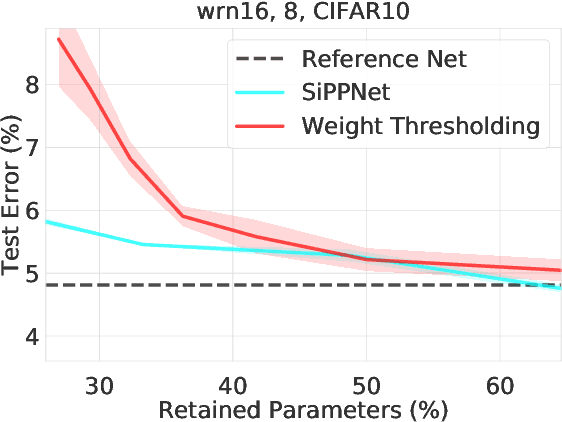
We introduce a pruning algorithm that provably sparsifies the parameters of a trained model in a way that approximately preserves the model's predictive accuracy. Our algorithm uses a small batch of input points to construct a data-informed importance sampling distribution over the network's parameters, and adaptively mixes a sampling-based and deterministic pruning procedure to discard redundant weights. Our pruning method is simultaneously computationally efficient, provably accurate, and broadly applicable to various network architectures and data distributions. Our empirical comparisons show that our algorithm reliably generates highly compressed networks that incur minimal loss in performance relative to that of the original network. We present experimental results that demonstrate our algorithm's potential to unearth essential network connections that can be trained successfully in isolation, which may be of independent interest.