 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLaM: Student-Label Mixing for Semi-Supervised Knowledge Distillation
Feb 08, 2023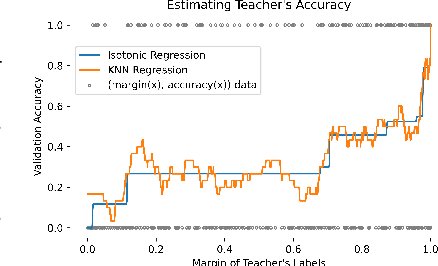
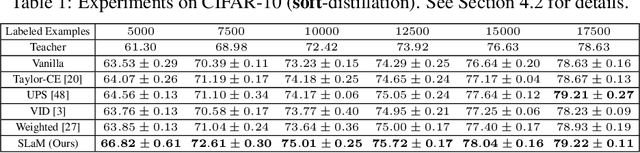
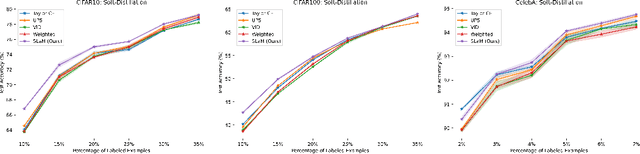

Semi-supervised knowledge distillation is a powerful training paradigm for generating compact and lightweight student models in settings where the amount of labeled data is limited but one has access to a large pool of unlabeled data. The idea is that a large teacher model is utilized to generate ``smoothed'' pseudo-labels for the unlabeled dataset which are then used for training the student model. Despite its success in a wide variety of applications, a shortcoming of this approach is that the teacher's pseudo-labels are often noisy, leading to impaired student performance. In this paper, we present a principled method for semi-supervised knowledge distillation that we call Student-Label Mixing (SLaM) and we show that it consistently improves over prior approaches by evaluating it on several standard benchmarks. Finally, we show that SLaM comes with theoretical guarantees; along the way we give an algorithm improving the best-known sample complexity for learning halfspaces with margin under random classification noise, and provide the first convergence analysis for so-called ``forward loss-adjustment" methods.
The Power of External Memory in Increasing Predictive Model Capacity
Jan 31, 2023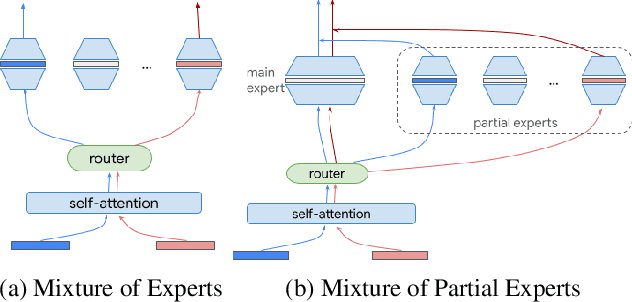
One way of introducing sparsity into deep networks is by attaching an external table of parameters that is sparsely looked up at different layers of the network. By storing the bulk of the parameters in the external table, one can increase the capacity of the model without necessarily increasing the inference time. Two crucial questions in this setting are then: what is the lookup function for accessing the table and how are the contents of the table consumed? Prominent methods for accessing the table include 1) using words/wordpieces token-ids as table indices, 2) LSH hashing the token vector in each layer into a table of buckets, and 3) learnable softmax style routing to a table entry. The ways to consume the contents include adding/concatenating to input representation, and using the contents as expert networks that specialize to different inputs. In this work, we conduct rigorous experimental evaluations of existing ideas and their combinations. We also introduce a new method, alternating updates, that enables access to an increased token dimension without increasing the computation time, and demonstrate its effectiveness in language modeling.
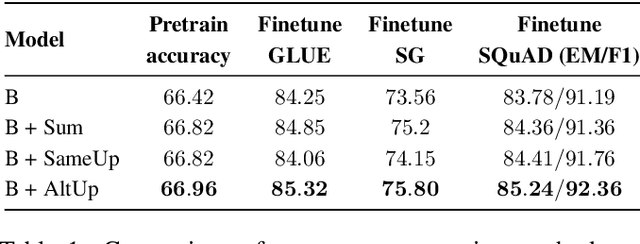
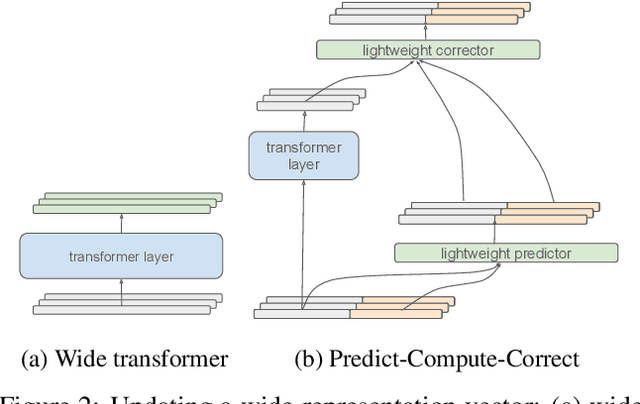
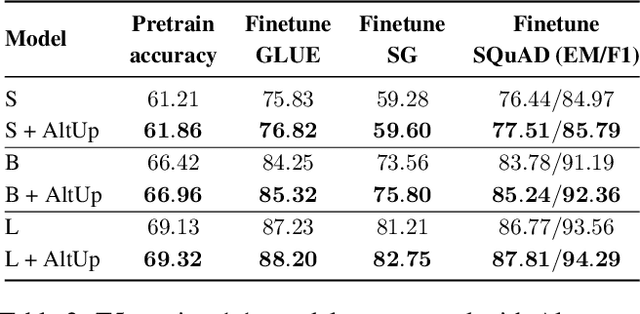
Alternating Updates for Efficient Transformers
Jan 30, 2023



It is well established that increasing scale in deep transformer networks leads to improved quality and performance. This increase in scale often comes with an increase in compute cost and inference latency. Consequently, research into methods which help realize the benefits of increased scale without leading to an increase in the compute cost becomes important. We introduce Alternating Updates (AltUp), a simple-to-implement method to increase a model's capacity without the computational burden. AltUp enables the widening of the learned representation without increasing the computation time by working on a subblock of the representation at each layer. Our experiments on various transformer models and language tasks demonstrate the consistent effectiveness of alternating updates on a diverse set of benchmarks. Finally, we present extensions of AltUp to the sequence dimension, and demonstrate how AltUp can be synergistically combined with existing approaches, such as Sparse Mixture-of-Experts models, to obtain efficient models with even higher capacity.
Weighted Distillation with Unlabeled Examples
Oct 13, 2022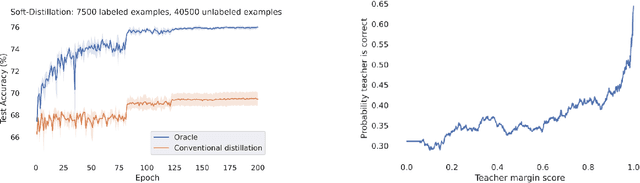
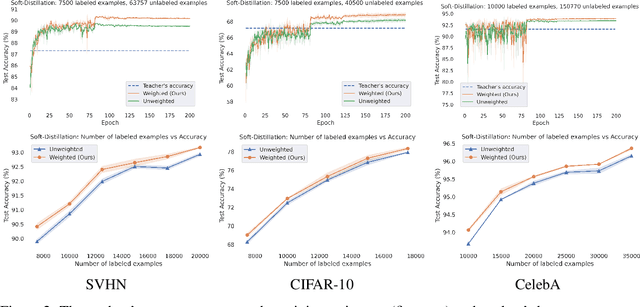
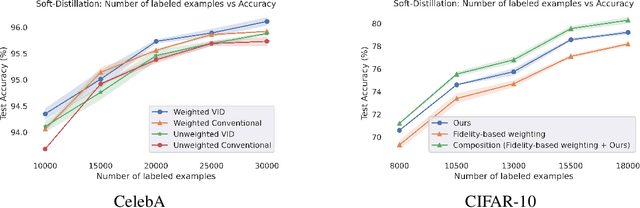

Distillation with unlabeled examples is a popular and powerful method for training deep neural networks in settings where the amount of labeled data is limited: A large ''teacher'' neural network is trained on the labeled data available, and then it is used to generate labels on an unlabeled dataset (typically much larger in size). These labels are then utilized to train the smaller ''student'' model which will actually be deployed. Naturally, the success of the approach depends on the quality of the teacher's labels, since the student could be confused if trained on inaccurate data. This paper proposes a principled approach for addressing this issue based on a ''debiasing'' reweighting of the student's loss function tailored to the distillation training paradigm. Our method is hyper-parameter free, data-agnostic, and simple to implement. We demonstrate significant improvements on popular academic datasets and we accompany our results with a theoretical analysis which rigorously justifies the performance of our method in certain settings.
Robust Active Distillation
Oct 03, 2022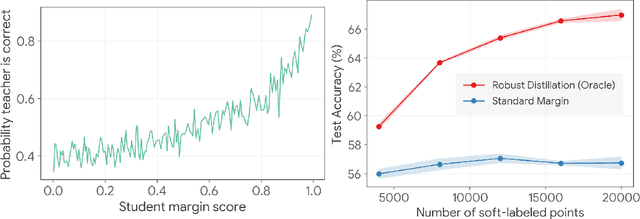
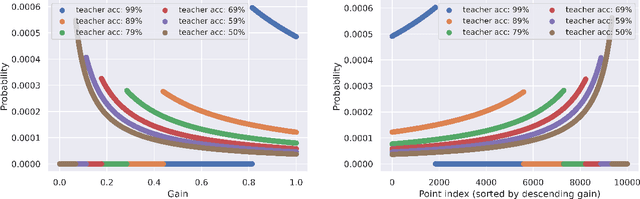
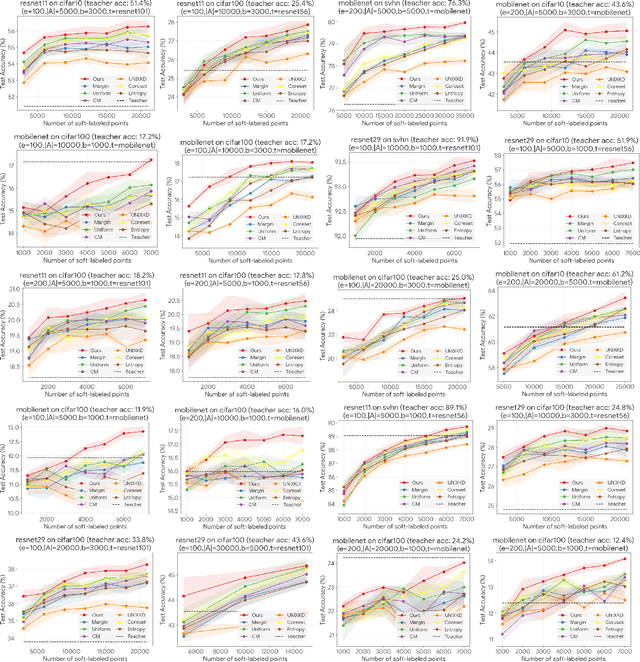
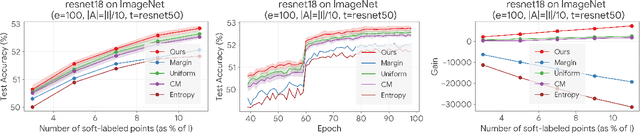
Distilling knowledge from a large teacher model to a lightweight one is a widely successful approach for generating compact, powerful models in the semi-supervised learning setting where a limited amount of labeled data is available. In large-scale applications, however, the teacher tends to provide a large number of incorrect soft-labels that impairs student performance. The sheer size of the teacher additionally constrains the number of soft-labels that can be queried due to prohibitive computational and/or financial costs. The difficulty in achieving simultaneous \emph{efficiency} (i.e., minimizing soft-label queries) and \emph{robustness} (i.e., avoiding student inaccuracies due to incorrect labels) hurts the widespread application of knowledge distillation to many modern tasks. In this paper, we present a parameter-free approach with provable guarantees to query the soft-labels of points that are simultaneously informative and correctly labeled by the teacher. At the core of our work lies a game-theoretic formulation that explicitly considers the inherent trade-off between the informativeness and correctness of input instances. We establish bounds on the expected performance of our approach that hold even in worst-case distillation instances. We present empirical evaluations on popular benchmarks that demonstrate the improved distillation performance enabled by our work relative to that of state-of-the-art active learning and active distillation methods.
A Theoretical View on Sparsely Activated Networks
Aug 08, 2022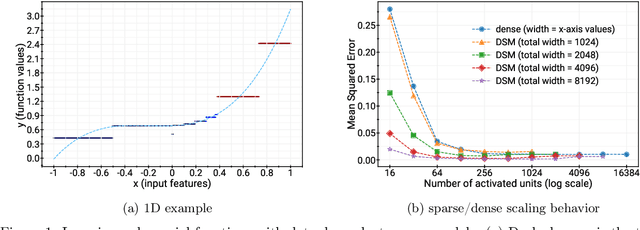

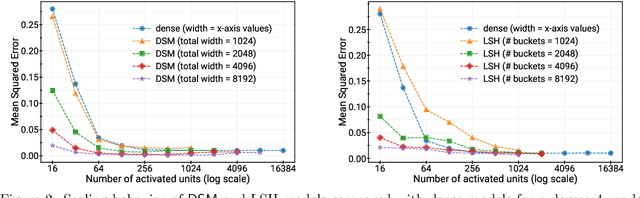
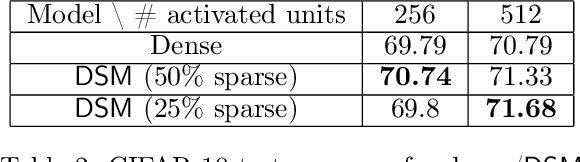
Deep and wide neural networks successfully fit very complex functions today, but dense models are starting to be prohibitively expensive for inference. To mitigate this, one promising direction is networks that activate a sparse subgraph of the network. The subgraph is chosen by a data-dependent routing function, enforcing a fixed mapping of inputs to subnetworks (e.g., the Mixture of Experts (MoE) paradigm in Switch Transformers). However, prior work is largely empirical, and while existing routing functions work well in practice, they do not lead to theoretical guarantees on approximation ability. We aim to provide a theoretical explanation for the power of sparse networks. As our first contribution, we present a formal model of data-dependent sparse networks that captures salient aspects of popular architectures. We then introduce a routing function based on locality sensitive hashing (LSH) that enables us to reason about how well sparse networks approximate target functions. After representing LSH-based sparse networks with our model, we prove that sparse networks can match the approximation power of dense networks on Lipschitz functions. Applying LSH on the input vectors means that the experts interpolate the target function in different subregions of the input space. To support our theory, we define various datasets based on Lipschitz target functions, and we show that sparse networks give a favorable trade-off between number of active units and approximation quality.
Bandit Sampling for Multiplex Networks
Feb 08, 2022



Graph neural networks have gained prominence due to their excellent performance in many classification and prediction tasks. In particular, they are used for node classification and link prediction which have a wide range of applications in social networks, biomedical data sets, and financial transaction graphs. Most of the existing work focuses primarily on the monoplex setting where we have access to a network with only a single type of connection between entities. However, in the multiplex setting, where there are multiple types of connections, or \emph{layers}, between entities, performance on tasks such as link prediction has been shown to be stronger when information from other connection types is taken into account. We propose an algorithm for scalable learning on multiplex networks with a large number of layers. The efficiency of our method is enabled by an online learning algorithm that learns how to sample relevant neighboring layers so that only the layers with relevant information are aggregated during training. This sampling differs from prior work, such as MNE, which aggregates information across \emph{all} layers and consequently leads to computational intractability on large networks. Our approach also improves on the recent layer sampling method of \textsc{DeePlex} in that the unsampled layers do not need to be trained, enabling further increases in efficiency.We present experimental results on both synthetic and real-world scenarios that demonstrate the practical effectiveness of our proposed approach.
Graph Belief Propagation Networks
Jun 06, 2021
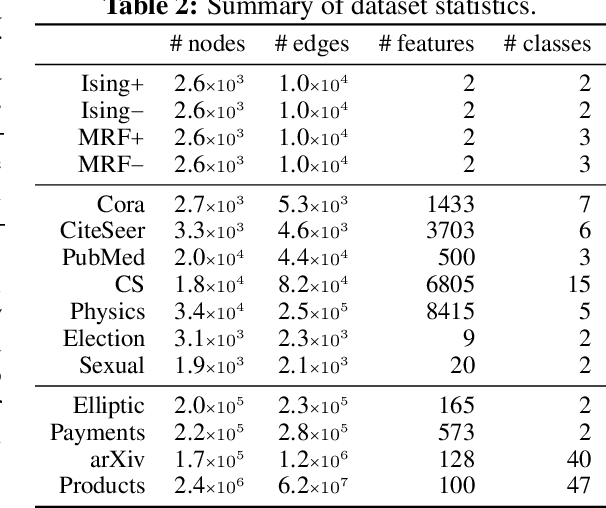
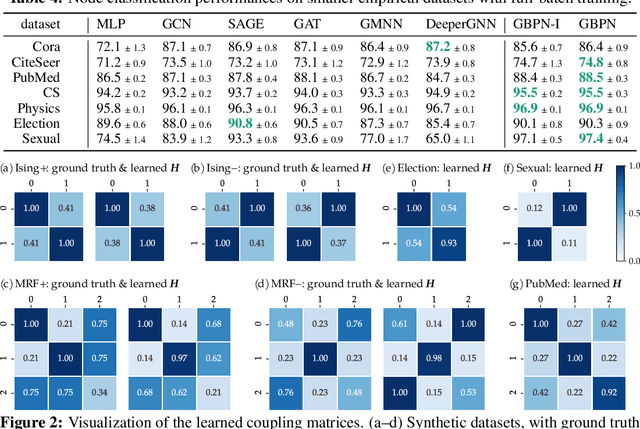

With the wide-spread availability of complex relational data, semi-supervised node classification in graphs has become a central machine learning problem. Graph neural networks are a recent class of easy-to-train and accurate methods for this problem that map the features in the neighborhood of a node to its label, but they ignore label correlation during inference and their predictions are difficult to interpret. On the other hand, collective classification is a traditional approach based on interpretable graphical models that explicitly model label correlations. Here, we introduce a model that combines the advantages of these two approaches, where we compute the marginal probabilities in a conditional random field, similar to collective classification, and the potentials in the random field are learned through end-to-end training, akin to graph neural networks. In our model, potentials on each node only depend on that node's features, and edge potentials are learned via a coupling matrix. This structure enables simple training with interpretable parameters, scales to large networks, naturally incorporates training labels at inference, and is often more accurate than related approaches. Our approach can be viewed as either an interpretable message-passing graph neural network or a collective classification method with higher capacity and modernized training.
Low-Regret Active learning
Apr 06, 2021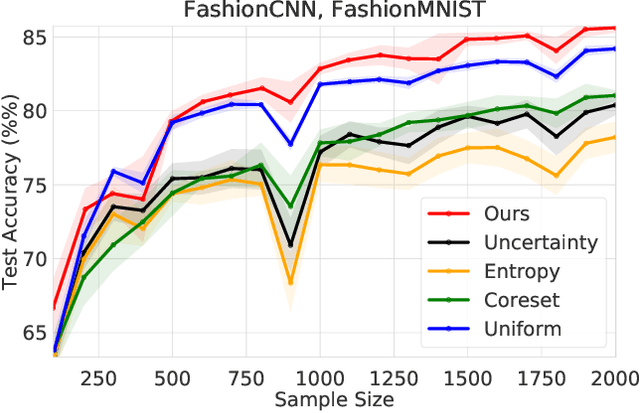


We develop an online learning algorithm for identifying unlabeled data points that are most informative for training (i.e., active learning). By formulating the active learning problem as the prediction with sleeping experts problem, we provide a framework for identifying informative data with respect to any given definition of informativeness. At the core of our work is an efficient algorithm for sleeping experts that is tailored to achieve low regret on predictable (easy) instances while remaining resilient to adversarial ones. This stands in contrast to state-of-the-art active learning methods that are overwhelmingly based on greedy selection, and hence cannot ensure good performance across varying problem instances. We present empirical results demonstrating that our method (i) instantiated with an informativeness measure consistently outperforms its greedy counterpart and (ii) reliably outperforms uniform sampling on real-world data sets and models.
Lost in Pruning: The Effects of Pruning Neural Networks beyond Test Accuracy
Mar 04, 2021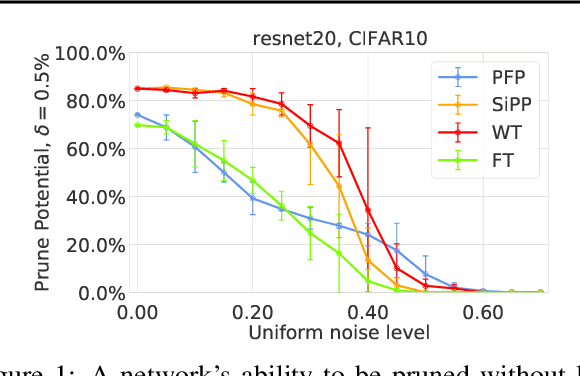

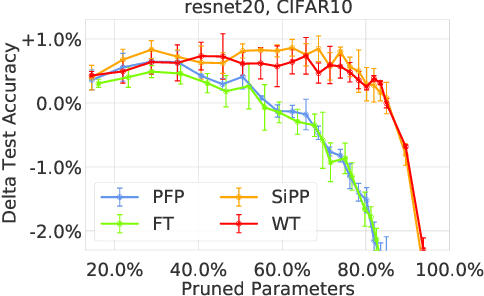
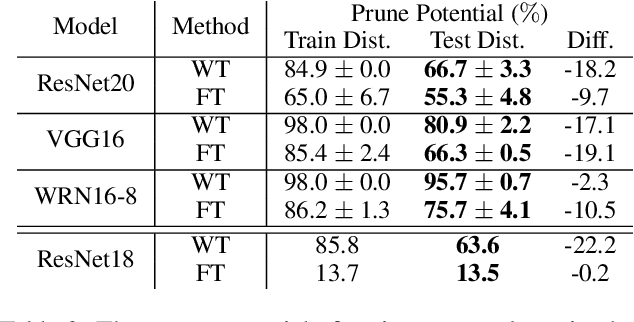
Neural network pruning is a popular technique used to reduce the inference costs of modern, potentially overparameterized, networks. Starting from a pre-trained network, the process is as follows: remove redundant parameters, retrain, and repeat while maintaining the same test accuracy. The result is a model that is a fraction of the size of the original with comparable predictive performance (test accuracy). Here, we reassess and evaluate whether the use of test accuracy alone in the terminating condition is sufficient to ensure that the resulting model performs well across a wide spectrum of "harder" metrics such as generalization to out-of-distribution data and resilience to noise. Across evaluations on varying architectures and data sets, we find that pruned networks effectively approximate the unpruned model, however, the prune ratio at which pruned networks achieve commensurate performance varies significantly across tasks. These results call into question the extent of \emph{genuine} overparameterization in deep learning and raise concerns about the practicability of deploying pruned networks, specifically in the context of safety-critical systems, unless they are widely evaluated beyond test accuracy to reliably predict their performance. Our code is available at https://github.com/lucaslie/torchprune.