 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of External Memory in Increasing Predictive Model Capacity
Jan 31, 2023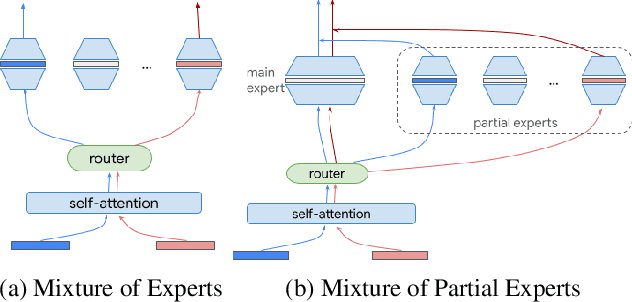
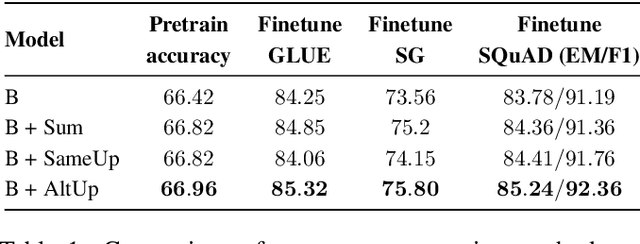
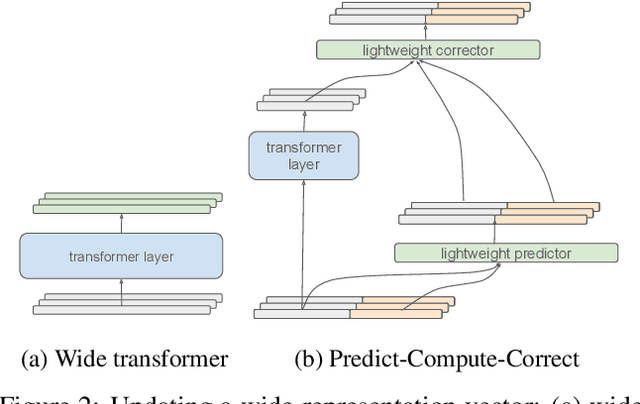
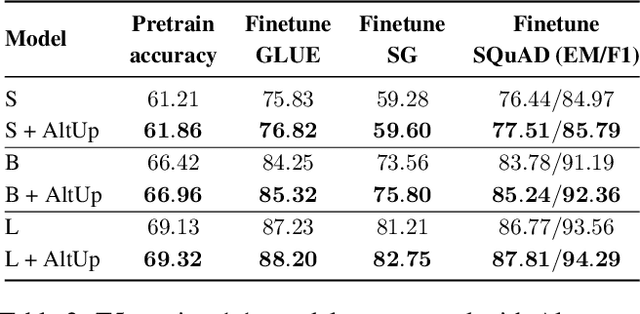
One way of introducing sparsity into deep networks is by attaching an external table of parameters that is sparsely looked up at different layers of the network. By storing the bulk of the parameters in the external table, one can increase the capacity of the model without necessarily increasing the inference time. Two crucial questions in this setting are then: what is the lookup function for accessing the table and how are the contents of the table consumed? Prominent methods for accessing the table include 1) using words/wordpieces token-ids as table indices, 2) LSH hashing the token vector in each layer into a table of buckets, and 3) learnable softmax style routing to a table entry. The ways to consume the contents include adding/concatenating to input representation, and using the contents as expert networks that specialize to different inputs. In this work, we conduct rigorous experimental evaluations of existing ideas and their combinations. We also introduce a new method, alternating updates, that enables access to an increased token dimension without increasing the computation time, and demonstrate its effectiveness in language modeling.