 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical View on Sparsely Activated Networks
Paper and Code
Aug 08, 2022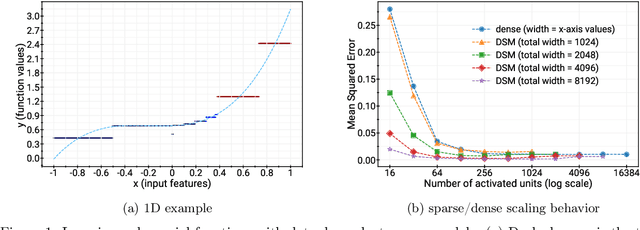

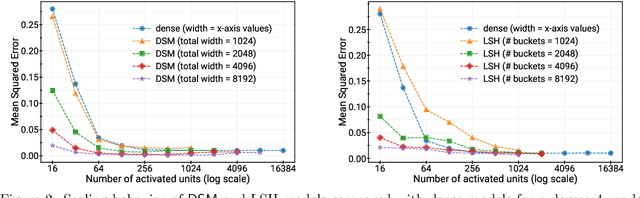
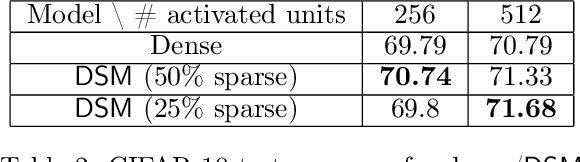
Deep and wide neural networks successfully fit very complex functions today, but dense models are starting to be prohibitively expensive for inference. To mitigate this, one promising direction is networks that activate a sparse subgraph of the network. The subgraph is chosen by a data-dependent routing function, enforcing a fixed mapping of inputs to subnetworks (e.g., the Mixture of Experts (MoE) paradigm in Switch Transformers). However, prior work is largely empirical, and while existing routing functions work well in practice, they do not lead to theoretical guarantees on approximation ability. We aim to provide a theoretical explanation for the power of sparse networks. As our first contribution, we present a formal model of data-dependent sparse networks that captures salient aspects of popular architectures. We then introduce a routing function based on locality sensitive hashing (LSH) that enables us to reason about how well sparse networks approximate target functions. After representing LSH-based sparse networks with our model, we prove that sparse networks can match the approximation power of dense networks on Lipschitz functions. Applying LSH on the input vectors means that the experts interpolate the target function in different subregions of the input space. To support our theory, we define various datasets based on Lipschitz target functions, and we show that sparse networks give a favorable trade-off between number of active units and approximation quality.