 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Projections of Teacher Embeddings for Few-Class Distillation
Sep 30, 2024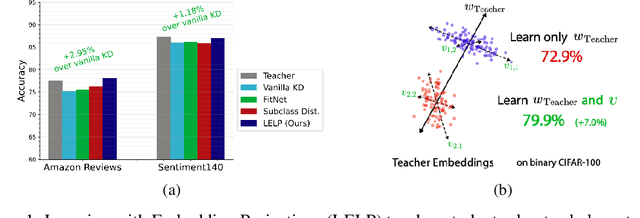

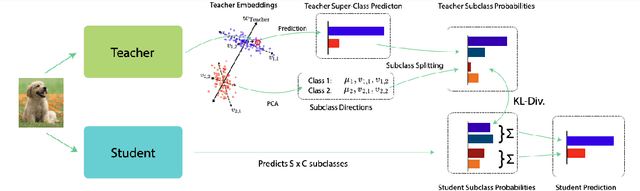

Knowledge Distillation (KD) has emerged as a promising approach for transferring knowledge from a larger, more complex teacher model to a smaller student model. Traditionally, KD involves training the student to mimic the teacher's output probabilities, while more advanced techniques have explored guiding the student to adopt the teacher's internal representations. Despite its widespread success, the performance of KD in binary classification and few-class problems has been less satisfactory. This is because the information about the teacher model's generalization patterns scales directly with the number of classes. Moreover, several sophisticated distillation methods may not be universally applicable or effective for data types beyond Computer Vision. Consequently, effective distillation techniques remain elusive for a range of key real-world applications, such as sentiment analysis, search query understanding, and advertisement-query relevance assessment. Taking these observations into account, we introduce a novel method for distilling knowledge from the teacher's model representations, which we term Learning Embedding Linear Projections (LELP). Inspired by recent findings about the structure of final-layer representations, LELP works by identifying informative linear subspaces in the teacher's embedding space, and splitting them into pseudo-subclasses. The student model is then trained to replicate these pseudo-classes. Our experimental evaluation on large-scale NLP benchmarks like Amazon Reviews and Sentiment140 demonstrate the LELP is consistently competitive with, and typically superior to, existing state-of-the-art distillation algorithms for binary and few-class problems, where most KD methods suffer.
LayerNAS: Neural Architecture Search in Polynomial Complexity
Apr 23, 2023Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial. For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$. LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to $ O(H \cdot |\mathbb{S}| \cdot L) $, where $H$ is a constant set in LayerNAS. Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.
SLaM: Student-Label Mixing for Semi-Supervised Knowledge Distillation
Feb 08, 2023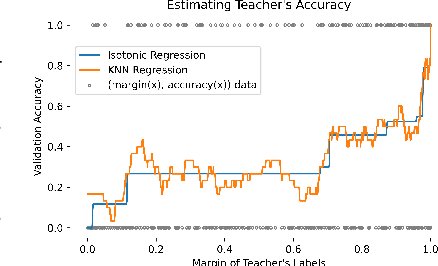
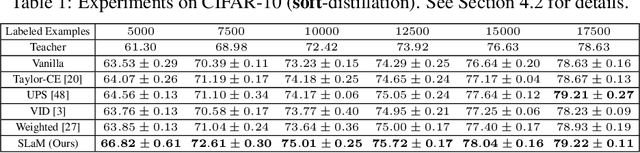
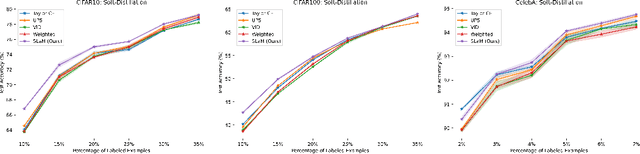

Semi-supervised knowledge distillation is a powerful training paradigm for generating compact and lightweight student models in settings where the amount of labeled data is limited but one has access to a large pool of unlabeled data. The idea is that a large teacher model is utilized to generate ``smoothed'' pseudo-labels for the unlabeled dataset which are then used for training the student model. Despite its success in a wide variety of applications, a shortcoming of this approach is that the teacher's pseudo-labels are often noisy, leading to impaired student performance. In this paper, we present a principled method for semi-supervised knowledge distillation that we call Student-Label Mixing (SLaM) and we show that it consistently improves over prior approaches by evaluating it on several standard benchmarks. Finally, we show that SLaM comes with theoretical guarantees; along the way we give an algorithm improving the best-known sample complexity for learning halfspaces with margin under random classification noise, and provide the first convergence analysis for so-called ``forward loss-adjustment" methods.
Weighted Distillation with Unlabeled Examples
Oct 13, 2022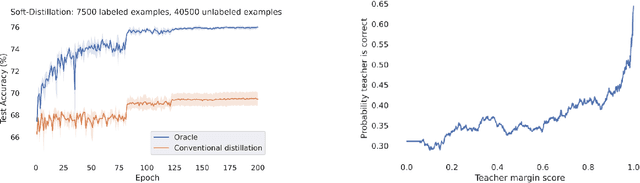
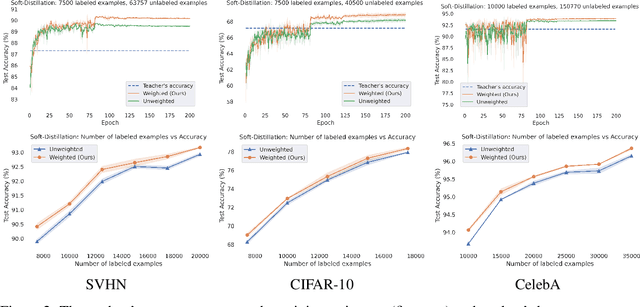
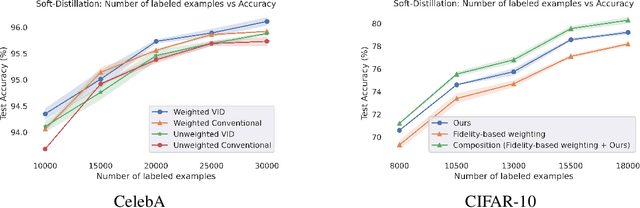

Distillation with unlabeled examples is a popular and powerful method for training deep neural networks in settings where the amount of labeled data is limited: A large ''teacher'' neural network is trained on the labeled data available, and then it is used to generate labels on an unlabeled dataset (typically much larger in size). These labels are then utilized to train the smaller ''student'' model which will actually be deployed. Naturally, the success of the approach depends on the quality of the teacher's labels, since the student could be confused if trained on inaccurate data. This paper proposes a principled approach for addressing this issue based on a ''debiasing'' reweighting of the student's loss function tailored to the distillation training paradigm. Our method is hyper-parameter free, data-agnostic, and simple to implement. We demonstrate significant improvements on popular academic datasets and we accompany our results with a theoretical analysis which rigorously justifies the performance of our method in certain settings.
Robust Active Distillation
Oct 03, 2022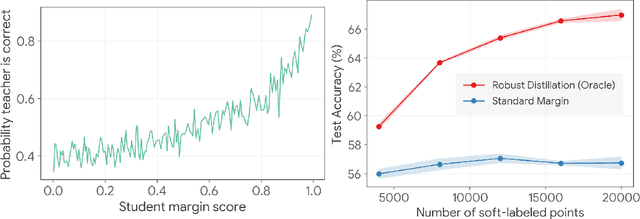
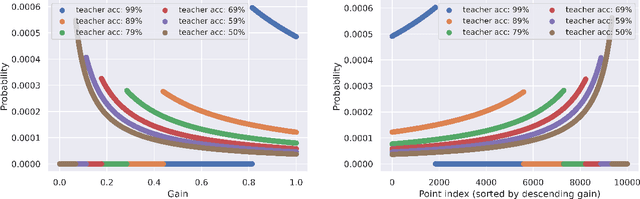
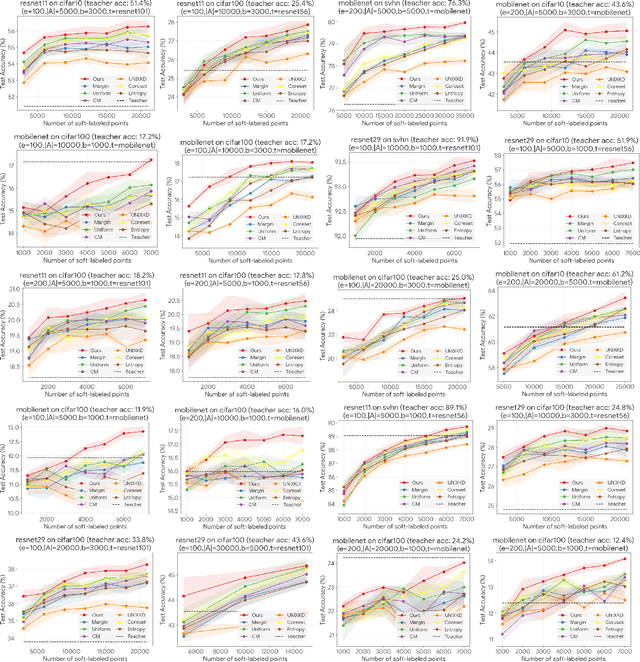
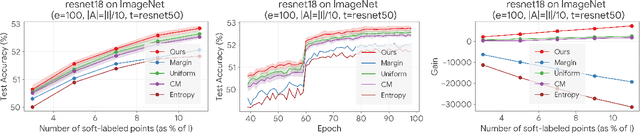
Distilling knowledge from a large teacher model to a lightweight one is a widely successful approach for generating compact, powerful models in the semi-supervised learning setting where a limited amount of labeled data is available. In large-scale applications, however, the teacher tends to provide a large number of incorrect soft-labels that impairs student performance. The sheer size of the teacher additionally constrains the number of soft-labels that can be queried due to prohibitive computational and/or financial costs. The difficulty in achieving simultaneous \emph{efficiency} (i.e., minimizing soft-label queries) and \emph{robustness} (i.e., avoiding student inaccuracies due to incorrect labels) hurts the widespread application of knowledge distillation to many modern tasks. In this paper, we present a parameter-free approach with provable guarantees to query the soft-labels of points that are simultaneously informative and correctly labeled by the teacher. At the core of our work lies a game-theoretic formulation that explicitly considers the inherent trade-off between the informativeness and correctness of input instances. We establish bounds on the expected performance of our approach that hold even in worst-case distillation instances. We present empirical evaluations on popular benchmarks that demonstrate the improved distillation performance enabled by our work relative to that of state-of-the-art active learning and active distillation methods.