 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Projections of Teacher Embeddings for Few-Class Distillation
Paper and Code
Sep 30, 2024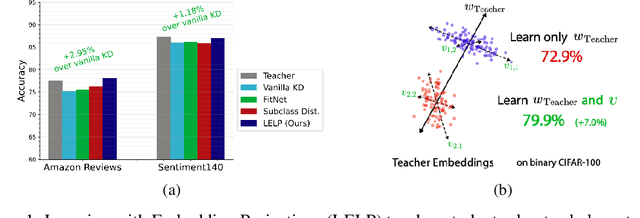

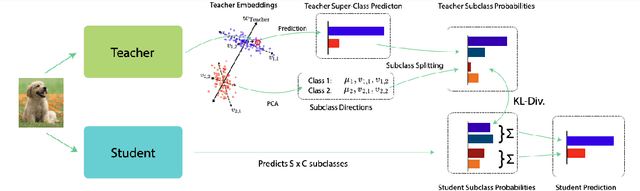

Knowledge Distillation (KD) has emerged as a promising approach for transferring knowledge from a larger, more complex teacher model to a smaller student model. Traditionally, KD involves training the student to mimic the teacher's output probabilities, while more advanced techniques have explored guiding the student to adopt the teacher's internal representations. Despite its widespread success, the performance of KD in binary classification and few-class problems has been less satisfactory. This is because the information about the teacher model's generalization patterns scales directly with the number of classes. Moreover, several sophisticated distillation methods may not be universally applicable or effective for data types beyond Computer Vision. Consequently, effective distillation techniques remain elusive for a range of key real-world applications, such as sentiment analysis, search query understanding, and advertisement-query relevance assessment. Taking these observations into account, we introduce a novel method for distilling knowledge from the teacher's model representations, which we term Learning Embedding Linear Projections (LELP). Inspired by recent findings about the structure of final-layer representations, LELP works by identifying informative linear subspaces in the teacher's embedding space, and splitting them into pseudo-subclasses. The student model is then trained to replicate these pseudo-classes. Our experimental evaluation on large-scale NLP benchmarks like Amazon Reviews and Sentiment140 demonstrate the LELP is consistently competitive with, and typically superior to, existing state-of-the-art distillation algorithms for binary and few-class problems, where most KD methods suffer.