 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAuReL: Learned Augmented Residual Layer
Nov 13, 2024



One of the core pillars of efficient deep learning methods is architectural improvements such as the residual/skip connection, which has led to significantly better model convergence and quality. Since then the residual connection has become ubiquitous in not just convolutional neural networks but also transformer-based architectures, the backbone of LLMs. In this paper we introduce \emph{Learned Augmented Residual Layer} (LAuReL) -- a novel generalization of the canonical residual connection -- with the goal to be an in-situ replacement of the latter while outperforming on both model quality and footprint metrics. Our experiments show that using \laurel can help boost performance for both vision and language models. For example, on the ResNet-50, ImageNet 1K task, it achieves $60\%$ of the gains from adding an extra layer, while only adding $0.003\%$ more parameters, and matches it while adding $2.6\times$ fewer parameters.
SLaM: Student-Label Mixing for Semi-Supervised Knowledge Distillation
Feb 08, 2023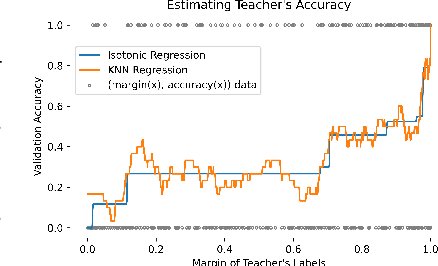
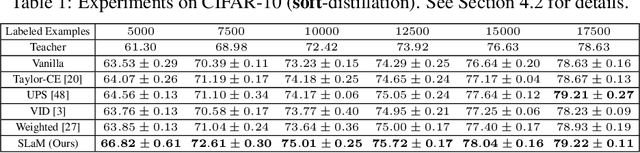
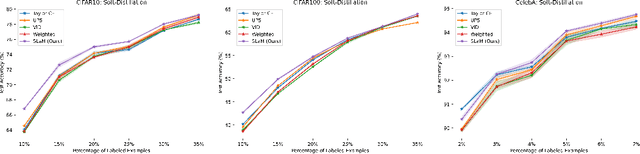

Semi-supervised knowledge distillation is a powerful training paradigm for generating compact and lightweight student models in settings where the amount of labeled data is limited but one has access to a large pool of unlabeled data. The idea is that a large teacher model is utilized to generate ``smoothed'' pseudo-labels for the unlabeled dataset which are then used for training the student model. Despite its success in a wide variety of applications, a shortcoming of this approach is that the teacher's pseudo-labels are often noisy, leading to impaired student performance. In this paper, we present a principled method for semi-supervised knowledge distillation that we call Student-Label Mixing (SLaM) and we show that it consistently improves over prior approaches by evaluating it on several standard benchmarks. Finally, we show that SLaM comes with theoretical guarantees; along the way we give an algorithm improving the best-known sample complexity for learning halfspaces with margin under random classification noise, and provide the first convergence analysis for so-called ``forward loss-adjustment" methods.
Weighted Distillation with Unlabeled Examples
Oct 13, 2022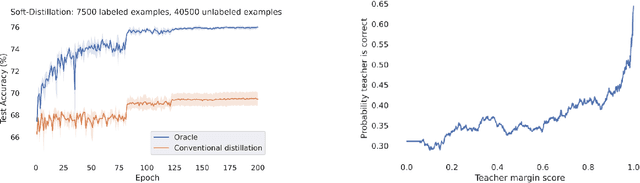
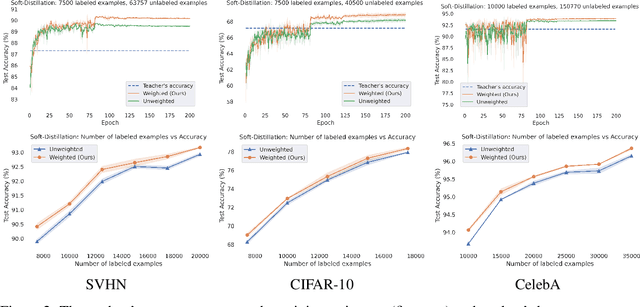
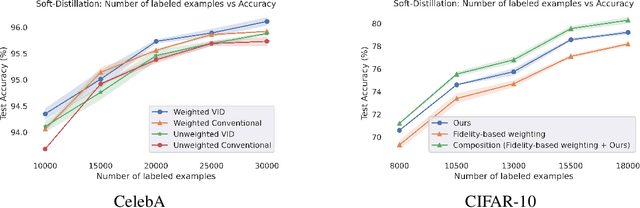

Distillation with unlabeled examples is a popular and powerful method for training deep neural networks in settings where the amount of labeled data is limited: A large ''teacher'' neural network is trained on the labeled data available, and then it is used to generate labels on an unlabeled dataset (typically much larger in size). These labels are then utilized to train the smaller ''student'' model which will actually be deployed. Naturally, the success of the approach depends on the quality of the teacher's labels, since the student could be confused if trained on inaccurate data. This paper proposes a principled approach for addressing this issue based on a ''debiasing'' reweighting of the student's loss function tailored to the distillation training paradigm. Our method is hyper-parameter free, data-agnostic, and simple to implement. We demonstrate significant improvements on popular academic datasets and we accompany our results with a theoretical analysis which rigorously justifies the performance of our method in certain settings.
Robust Active Distillation
Oct 03, 2022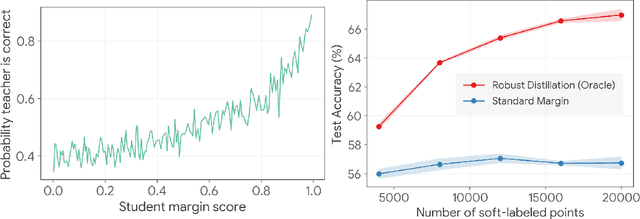
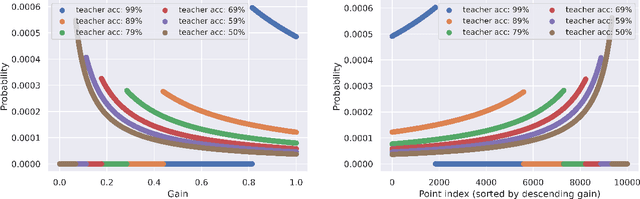
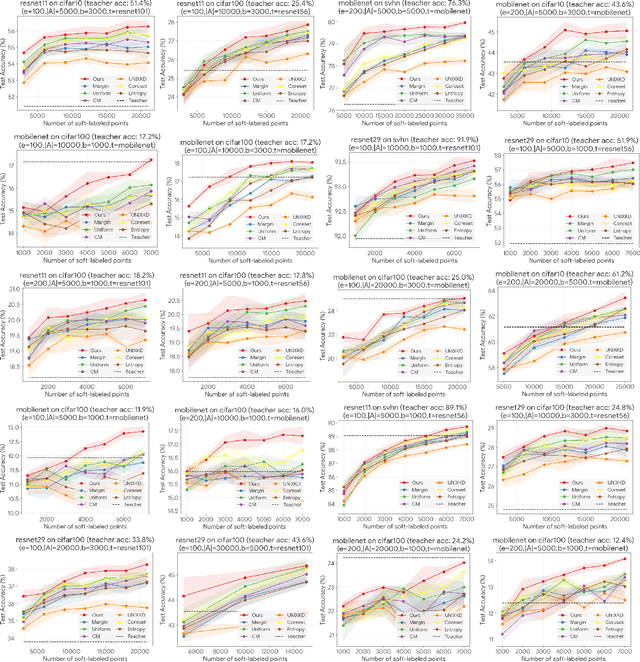
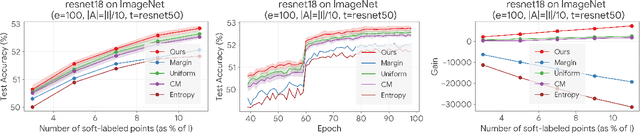
Distilling knowledge from a large teacher model to a lightweight one is a widely successful approach for generating compact, powerful models in the semi-supervised learning setting where a limited amount of labeled data is available. In large-scale applications, however, the teacher tends to provide a large number of incorrect soft-labels that impairs student performance. The sheer size of the teacher additionally constrains the number of soft-labels that can be queried due to prohibitive computational and/or financial costs. The difficulty in achieving simultaneous \emph{efficiency} (i.e., minimizing soft-label queries) and \emph{robustness} (i.e., avoiding student inaccuracies due to incorrect labels) hurts the widespread application of knowledge distillation to many modern tasks. In this paper, we present a parameter-free approach with provable guarantees to query the soft-labels of points that are simultaneously informative and correctly labeled by the teacher. At the core of our work lies a game-theoretic formulation that explicitly considers the inherent trade-off between the informativeness and correctness of input instances. We establish bounds on the expected performance of our approach that hold even in worst-case distillation instances. We present empirical evaluations on popular benchmarks that demonstrate the improved distillation performance enabled by our work relative to that of state-of-the-art active learning and active distillation methods.
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
Jun 21, 2021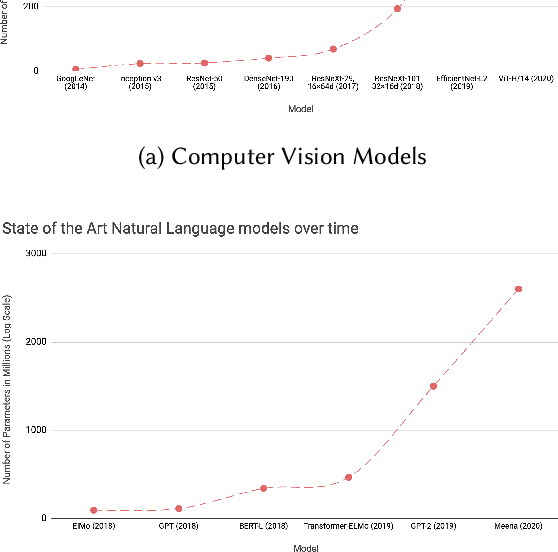

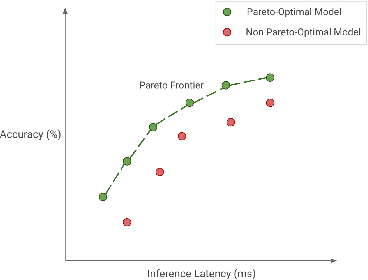

Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. However, with the progressive improvements in deep learning models, their number of parameters, latency, resources required to train, etc. have all have increased significantly. Consequently, it has become important to pay attention to these footprint metrics of a model as well, not just its quality. We present and motivate the problem of efficiency in deep learning, followed by a thorough survey of the five core areas of model efficiency (spanning modeling techniques, infrastructure, and hardware) and the seminal work there. We also present an experiment-based guide along with code, for practitioners to optimize their model training and deployment. We believe this is the first comprehensive survey in the efficient deep learning space that covers the landscape of model efficiency from modeling techniques to hardware support. Our hope is that this survey would provide the reader with the mental model and the necessary understanding of the field to apply generic efficiency techniques to immediately get significant improvements, and also equip them with ideas for further research and experimentation to achieve additional gains.
Learning from a Teacher using Unlabeled Data
Nov 13, 2019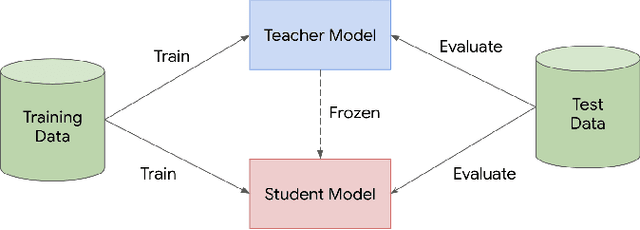
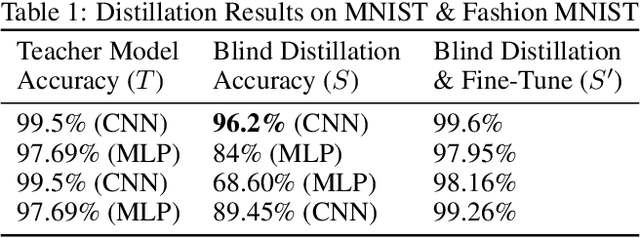

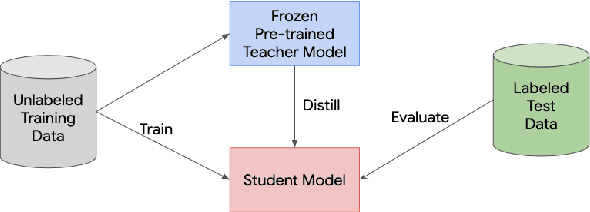
Knowledge distillation is a widely used technique for model compression. We posit that the teacher model used in a distillation setup, captures relationships between classes, that extend beyond the original dataset. We empirically show that a teacher model can transfer this knowledge to a student model even on an {\it out-of-distribution} dataset. Using this approach, we show promising results on MNIST, CIFAR-10, and Caltech-256 datasets using unlabeled image data from different sources. Our results are encouraging and help shed further light from the perspective of understanding knowledge distillation and utilizing unlabeled data to improve model quality.