Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from a Teacher using Unlabeled Data
Paper and Code
Nov 13, 2019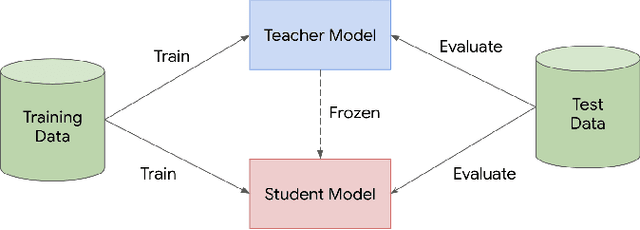
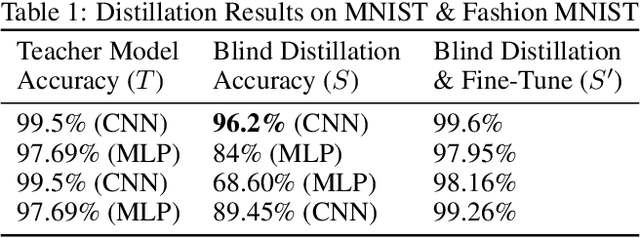

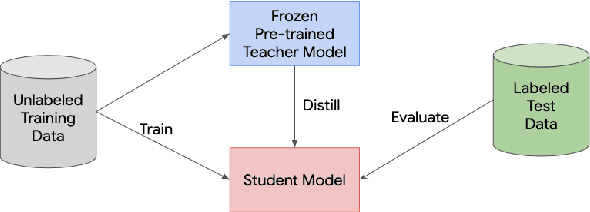
Knowledge distillation is a widely used technique for model compression. We posit that the teacher model used in a distillation setup, captures relationships between classes, that extend beyond the original dataset. We empirically show that a teacher model can transfer this knowledge to a student model even on an {\it out-of-distribution} dataset. Using this approach, we show promising results on MNIST, CIFAR-10, and Caltech-256 datasets using unlabeled image data from different sources. Our results are encouraging and help shed further light from the perspective of understanding knowledge distillation and utilizing unlabeled data to improve model quality.
View paper on