 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLaM: Student-Label Mixing for Semi-Supervised Knowledge Distillation
Paper and Code
Feb 08, 2023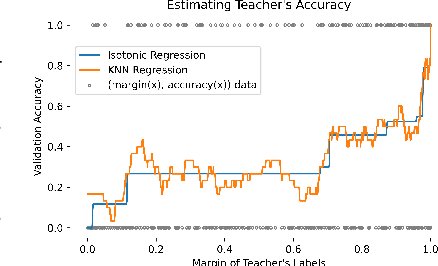
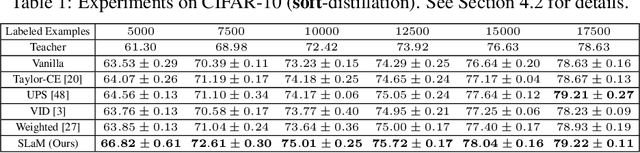
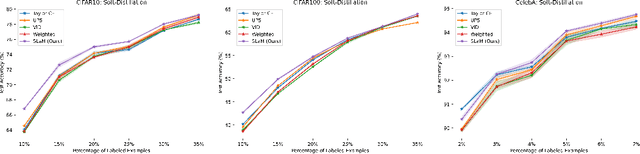

Semi-supervised knowledge distillation is a powerful training paradigm for generating compact and lightweight student models in settings where the amount of labeled data is limited but one has access to a large pool of unlabeled data. The idea is that a large teacher model is utilized to generate ``smoothed'' pseudo-labels for the unlabeled dataset which are then used for training the student model. Despite its success in a wide variety of applications, a shortcoming of this approach is that the teacher's pseudo-labels are often noisy, leading to impaired student performance. In this paper, we present a principled method for semi-supervised knowledge distillation that we call Student-Label Mixing (SLaM) and we show that it consistently improves over prior approaches by evaluating it on several standard benchmarks. Finally, we show that SLaM comes with theoretical guarantees; along the way we give an algorithm improving the best-known sample complexity for learning halfspaces with margin under random classification noise, and provide the first convergence analysis for so-called ``forward loss-adjustment" methods.