 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Pruning: The Effects of Pruning Neural Networks beyond Test Accuracy
Paper and Code
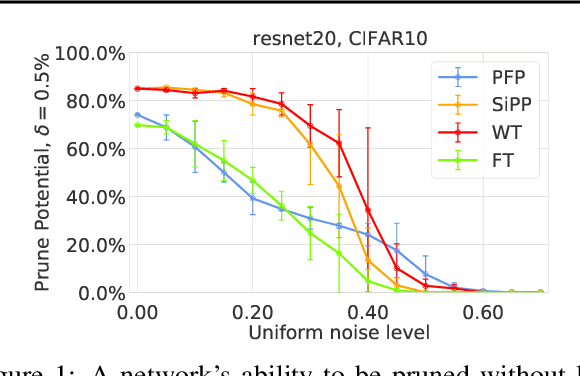

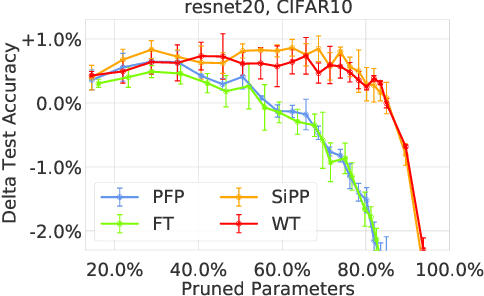
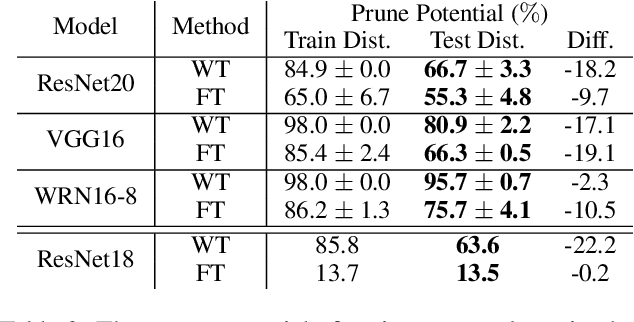
Neural network pruning is a popular technique used to reduce the inference costs of modern, potentially overparameterized, networks. Starting from a pre-trained network, the process is as follows: remove redundant parameters, retrain, and repeat while maintaining the same test accuracy. The result is a model that is a fraction of the size of the original with comparable predictive performance (test accuracy). Here, we reassess and evaluate whether the use of test accuracy alone in the terminating condition is sufficient to ensure that the resulting model performs well across a wide spectrum of "harder" metrics such as generalization to out-of-distribution data and resilience to noise. Across evaluations on varying architectures and data sets, we find that pruned networks effectively approximate the unpruned model, however, the prune ratio at which pruned networks achieve commensurate performance varies significantly across tasks. These results call into question the extent of \emph{genuine} overparameterization in deep learning and raise concerns about the practicability of deploying pruned networks, specifically in the context of safety-critical systems, unless they are widely evaluated beyond test accuracy to reliably predict their performance. Our code is available at https://github.com/lucaslie/torchprune.