 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Regret Active learning
Paper and Code
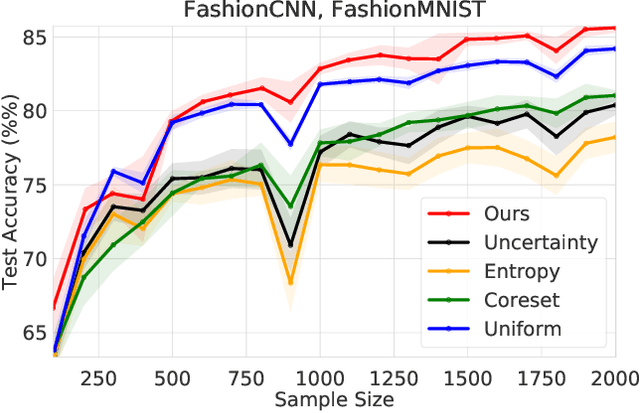

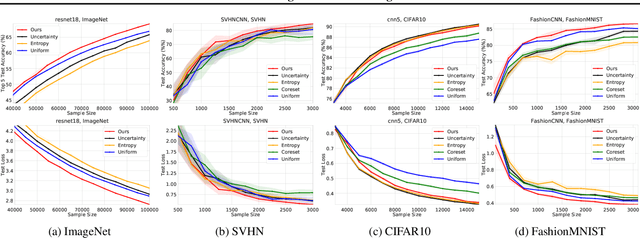

We develop an online learning algorithm for identifying unlabeled data points that are most informative for training (i.e., active learning). By formulating the active learning problem as the prediction with sleeping experts problem, we provide a framework for identifying informative data with respect to any given definition of informativeness. At the core of our work is an efficient algorithm for sleeping experts that is tailored to achieve low regret on predictable (easy) instances while remaining resilient to adversarial ones. This stands in contrast to state-of-the-art active learning methods that are overwhelmingly based on greedy selection, and hence cannot ensure good performance across varying problem instances. We present empirical results demonstrating that our method (i) instantiated with an informativeness measure consistently outperforms its greedy counterpart and (ii) reliably outperforms uniform sampling on real-world data sets and models.